







前言
这篇文章主要介绍了write combine的机制
一、write combine的试验
1.系统配置
(1)、CPU:11th Gen Intel(R) Core(TM) i7-11700 @ 2.50GHz
(2)、GPU:XX
(3)、link status:X16 GEN4(受限于CPU能力)
(4)、主板: TUF GAMING B560M-PLUS
(5)、linux 5.15.0-107-generic,ldd (Ubuntu GLIBC 2.31-0ubuntu9.16) 2.31
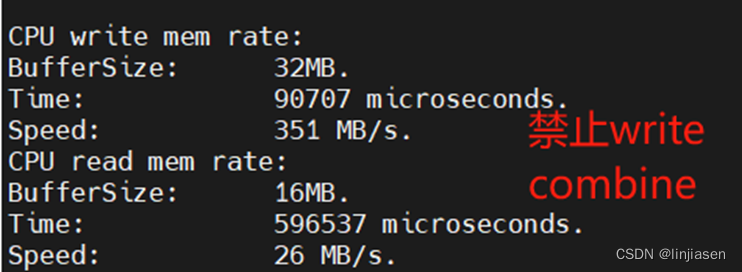
注意:CPU write combine受到CPU write combine buffer大小、write combine buffer entry数量、CPU的运行频率以及CPU evict write combine buffer的策略影响非常大,因此,绝对速率和CPU有关,这里只需要关注两种情况下,速率提高比例就可以了。
2、数据对比
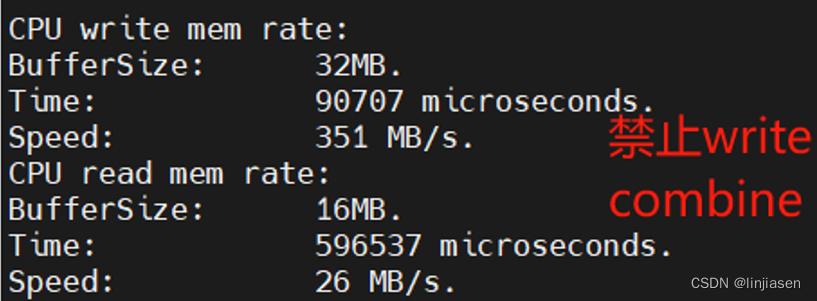
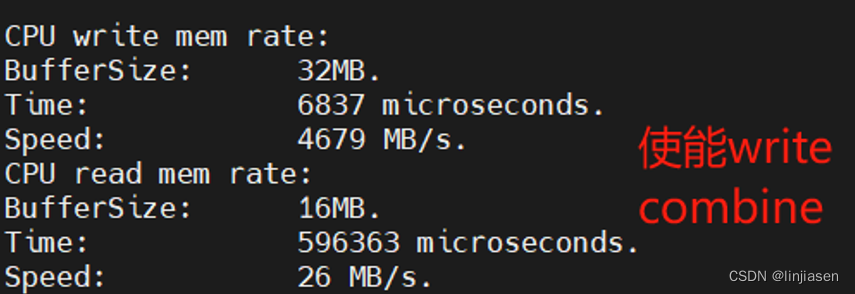
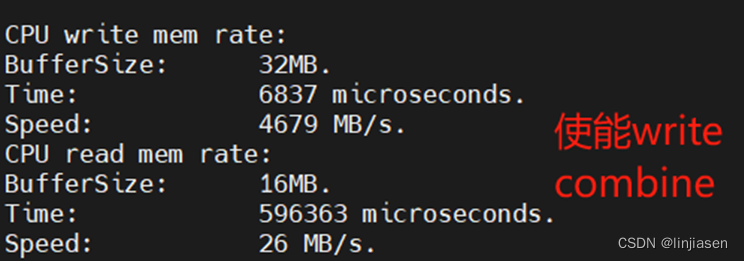
可见使用memcpy 把32M数据从system main memory拷贝的到GDDR,开启write combine后,CPU写的性能提供了13.3倍。这是怎么做到的呢?在讲write combine前需要先讲一下处理器的memory system,以及memory system中的cache。
二、背景知识:X86下的memory system
1、X86下的memory system简介
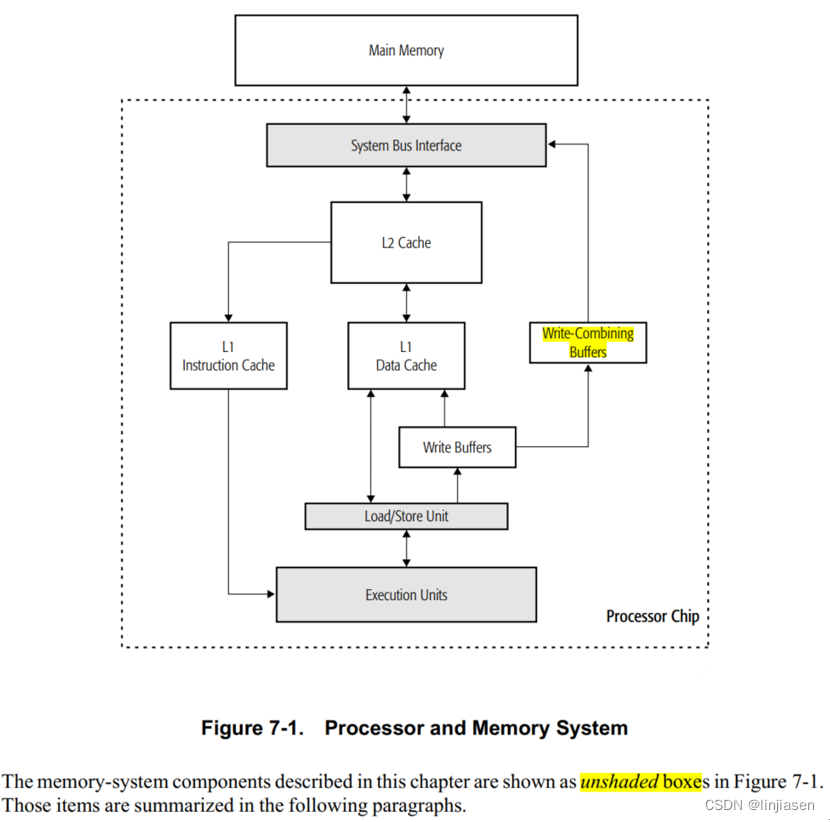
上图中的白色框就是memory system的组件。其中main memory在处理器芯片外,是离processor execution units最远的。
Cache是离processor execution units(处理器中负责执行指令和计算操作的部分)最近的。图中只是画了三种cache(L1 instruction cache、L1 data cache、L2 cache),实际上,对于多CPU core还有L3 cache。不同的微架构,L1/L2/L3的功能可能不太相同,但是基本原理差不多。
L1 cache和L2 cache一般是每个core都有自己独立的(根据CPU架构不同,可能有些CPU L2 cache就是share的了),只是L1 cache通常会被分成L1 data cache和L1 instruction cache ,而L2 cache的data 和instruction是合一的。
2、skylake CPU的cache hierarchy
下图是intel skylake CPU的 cache hierarchy(缓存层次结构),可看到每个CPU core有自己独立的L1和L2 cache,但是L3 cache(LLC)是share给所有的processors的。
在L2 cache和L3 cahce之间是L2 Snoop Filter, 是skylake架构中的一个缓存一致性机制。L2 Snoop Filter通过减少不必要的snoop请求(记录缓存数据的位置),来减少的缓存之间的通信开销,提高缓存一致性协议的效率。
所谓缓存一致性就是在多核处理器系统中,各个核的缓存需要保持一致性,以确保不同核访问同一内存地址时,数据是一致的。当一个核需要访问另一个核的缓存数据时,会发出 snoop 请求。这种请求会在总线上广播,以检查其他缓存中是否有该数据。

关于snoop,Intel64 andlA-32 Architectures Software Developer's Manual的11.2 CACHING TERMINOLOGY讲得比较清楚了。

在MP(多处理器)系统中,像Intel486和Intel 64这样的处理器具有snoop(侦听、监视)其他处理器访问system memory和访问处理器internal cache的能力,也就是所谓的“snoop”。 Snoop的功能让处理器的internal cache与system memory和总线上其他处理器中的cache保持一致。
例如,在Pentium和P6系列处理器中,通过侦听功能,如果处理器A检测到另一个处理器打算写一块memory location,而这块memory location已经自己被cache了,侦听处理器A就会invalidate自己的cache line,强制让自己在下一次访问相同的memory location时执行cache line fill的操作(从system memory来获取最新的数据)。
从P6系列处理器开始,如果一个处理器A检测到另一个处理器正在尝试访问一块memory location,而这块memory location已经在自己的cache中修改,但尚未写回到system memory,那么侦听处理器A将向其他处理器发出HITM#信号(Hold In Transaction Mode),这个信号告诉其他处理器该cache line已经处于modify状态并且将会发出modified data的write-back。
在这种情况下,具有有效修改数据的处理器可能会直接将此数据传递给请求处理器,而不立即将其写回system memory中。负责管理系统内存的memroy controller监视此操作,以确保系统内存最终得到最新的数据。因此,即使数据可能在处理器之间共享而不立即写回内存,内存控制器也确保系统内存最终反映出最新的数据。。
也就说,任何一个处理器别想偷偷干坏事(让自己的internal cache和其他处理的internal cache不一致),其他处理器一直在偷偷看着呢。
3、memory type(cache type)
前面说了那么多,就是为了引出cache type(memory type),Intel 64和IA-32架构定义下面的memory type。
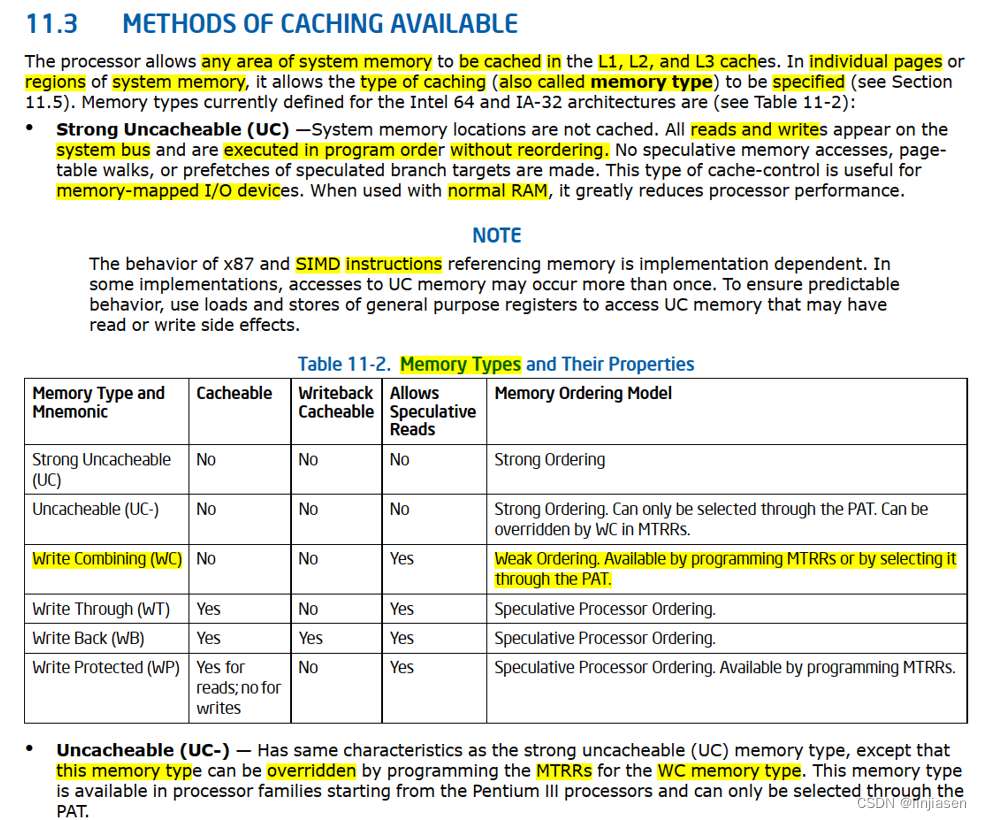

对WC类型的memory的写操作可能会delay并被combine在write combing buffer中,因此来减少memory access。如果WC buffer只是部分填充,write会被delay直到下一个串行事件发生,比如SFENCE或者MFENCE指令,CPUID或者其他串行指令,read或者write uncached memory,中断产生,或者执行LOCK指令。
WC 类型的cache-control非常适合video frame buffer,因为写order不重要。只要写入操作更新了内存,显示内容能够正确地显示在屏幕上即可。换句话说,即使写入操作的顺序不同,只要最终的内存状态能够正确反映出视频内容,就可以保证画面的正常显示。
4、Write combining buffer

往WC memory的写的数据会被保存在internal write combining buffer,这个buffer和L1/L2/L3 cache是不同的(见前面的Figure 7-1. Processor and Memory System)。WC buffer没有snoop功能,因此,不能提供数据一致性。
WC缓冲区的大小和结构在本架构文档上没有定义(也就说是vendor specific的)。对于Intel Core 2 Duo、Intel Atom、Intel Core Duo、Pentium M、Pentium 4和Intel Xeon处理器,WC缓冲区由若干个64字节的WC缓冲区组成。对于P6系列处理器,WC缓冲区由若干个32字节的WC缓冲区组成。
当软件开始向WC内存写入数据时,处理器就开始逐个填充WC缓冲区。当一个或多个WC缓冲区被填满后,处理器可以选择将数据从write combining buffer evict到system memory。WC缓冲区evict协议取决于厂商具体的实现,软件不能依赖此协议来确保系统内存的一致性。使用WC内存类型时,软件必须要注意:数据延迟写入系统内存,并在需要系统内存一致性时,需要软件主动清空WC缓冲区。
一旦处理器开始从WC缓冲区将数据evict到系统内存,它将基于缓冲区中包含的有效数据量做bus-transaction style的决策。如果缓冲区已满(例如,所有字节都是有效的),处理器将在总线上执行一个burst-write transaction。一个burst-write transaction会有32字节(P6系列处理器)或64字节(奔腾4及更高版本处理器)的数据会传输到data bus上。如果WC缓冲区的数据有一个或多个字节是无效的(例如,尚未被软件写入),处理器将使用“partial”transaction将数据传输到内存(一次一个chunk,其中一个“chunk”是8字节)。
“partial”transaction将导致将WC缓冲区中的数据发送到内存时最多进行4个(32/8)“partial”transaction(对于P6系列处理器)或8个(64/8)“partial”transaction(对于奔腾4及更高版本处理器)。
WC内存类型在定义上是weakly order的。一旦开始evict WC缓冲区中的数据,数据就受到weakly order的影响。在连续分配/释放WC缓冲区时不会保持顺序(例如,对WC缓冲区1的写入后,然后对WC缓冲区2的写入,可能在系统总线上看起来是缓冲区2先于缓冲区1)。使用partial write把数据从WC缓冲区中evict到system memory时,连续部分写之间也没有保证的顺序(例如,chunk 2的partial write可能在总线上先于chunk 1的partial write,反之亦然)。
三、Linux中Write combine相关函数
1、使能PAT的debug打印
关于pat的介绍可以参考
13. PAT (Page Attribute Table) — The Linux Kernel documentation
在cmdline增加debugpat就可以让dprintk打印
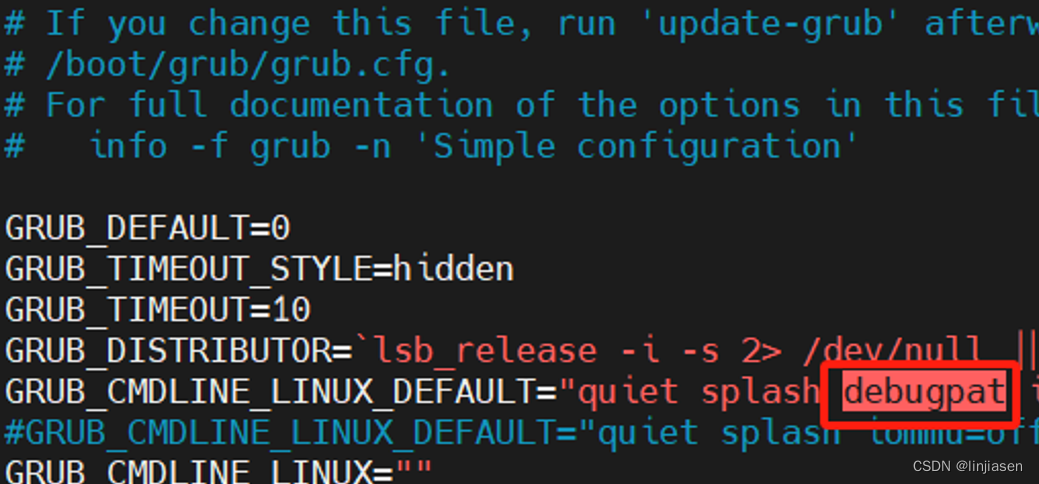


下面的打印就是我们cmdline增加debugpat,然后调用对应的API接口时,OS的打印:
[28168.324996] x86/PAT: memtype_reserve added [mem 0x6000000000-0x67ffffffff], track write-combining, req write-combining, ret write-combining
[28168.325001] mtgpu 0000:01:00.0: Enable mtrr success,base:0x6000000000,size:0x800000000, mtrr 0.
[28168.325006] x86/PAT: Overlap at 0xa4a00000-0xa4a48000
[28168.325009] x86/PAT: memtype_reserve added [mem 0xa4000000-0xa5ffffff], track uncached-minus, req uncached-minus, ret uncached-minus
[28168.325021] mtgpu 0000:01:00.0: PCIe BAR0 map start:0xa4000000 size:0x2000000, virtal addr:00000000d90d9aa4 (attribution: UC)
[28168.325028] x86/PAT: Overlap at 0x6000000000-0x6800000000
[28168.325030] x86/PAT: memtype_reserve added [mem 0x6000000000-0x67ffffffff], track write-combining, req write-combining, ret write-combining
[28168.325038] mtgpu 0000:01:00.0: PCIe BAR2 map start:0x6000000000 size:0x800000000, virtal addr:00000000542d4401 (attribution: WC)
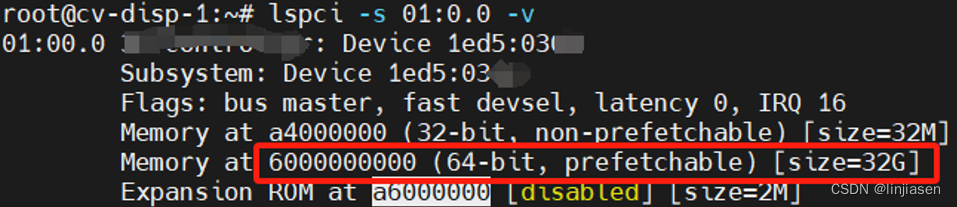
2、debugFS中PAT
cat /sys/kernel/debug/x86/pat_memtype_list,在我们drv中调用对应API后,debugFS会显示对应的page attribute。

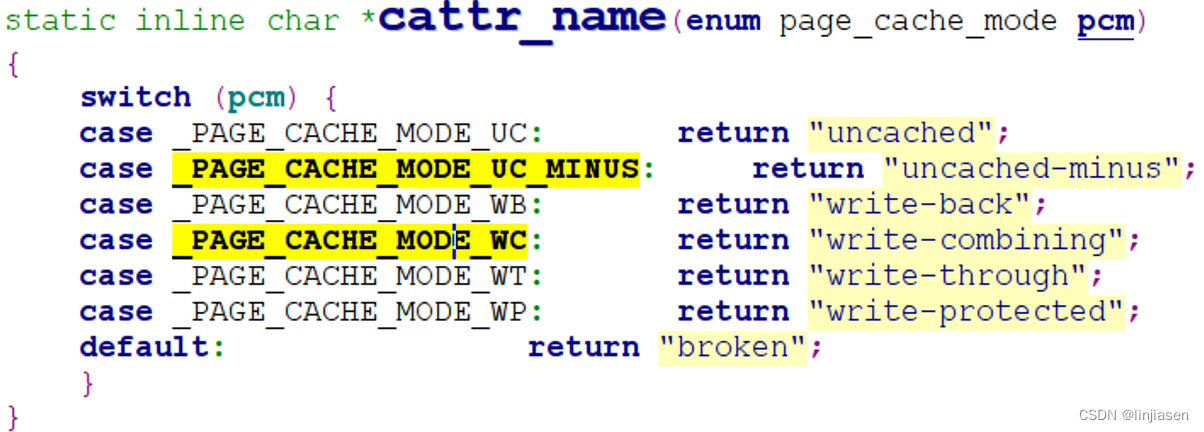
Linux 代码中的实现如下:


3、API接口
3.1 arch_io_reserve_memtype_wc
4.9.0增加了arch_io_reserve_memtype_wc
[PATCH 1/2] x86/io: add interface to reserve io memtype for a resource range. - Dave Airlie
memtype.c - arch/x86/mm/pat/memtype.c - Linux source code (v5.15) - Bootlin

3.2 memtype_reserve_io
arch_io_reserve_memtype_wc->memtype_reserve_io
memtype.c - arch/x86/mm/pat/memtype.c - Linux source code (v5.15) - Bootlin
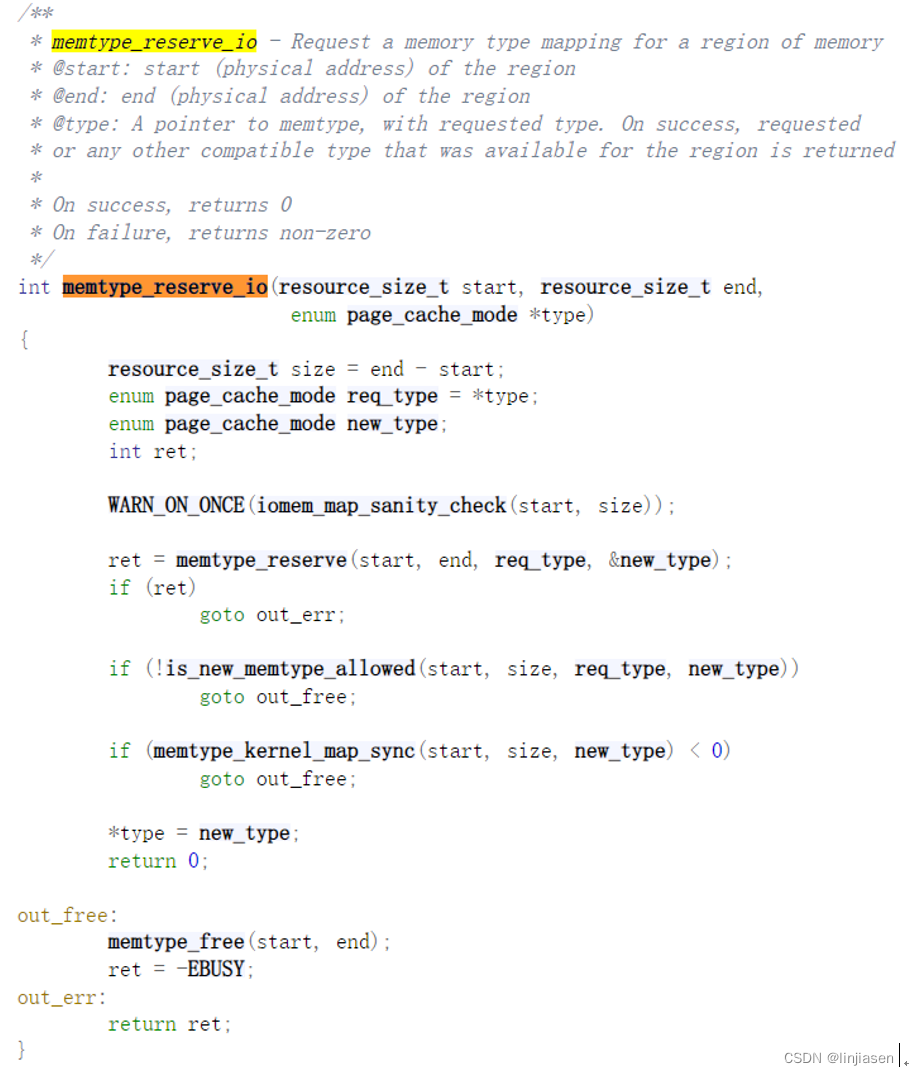
3.3 memtype_reserve
arch_io_reserve_memtype_wc->memtype_reserve_io->memtype_reserve
memtype.c - arch/x86/mm/pat/memtype.c - Linux source code (v5.15) - Bootlin


memtype_reserve是API调用栈的核心代码,主要实现下面功能
(1)memtype_reserve->pat_x_mttr_type来获取actual_type,
(2)然后memtype_reserve->pat_pagerange_is_ram来检查start和end是否不是RAM
./kprobe 'r:myopen pat_pagerange_is_ram $retval'
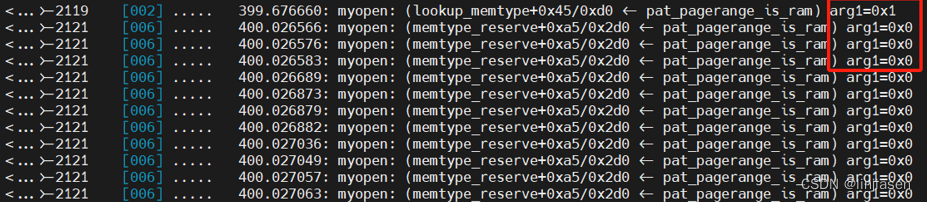
使用kprobe查看pat_pagerange_is_ram的返回值,当传入的start和end是MMIO地址的话,pat_pagerange_is_ram返回是的0。
(3)申请一个entry_new,memtype_reserve->memtype_check_insert,把新的entry插入到memtype_rbroot
3.4 memtype_check_insert
arch_io_reserve_memtype_wc->memtype_reserve_io->memtype_reserve->memtype_check_insert
memtype_interval.c - arch/x86/mm/pat/memtype_interval.c - Linux source code (v5.15) - Bootlin
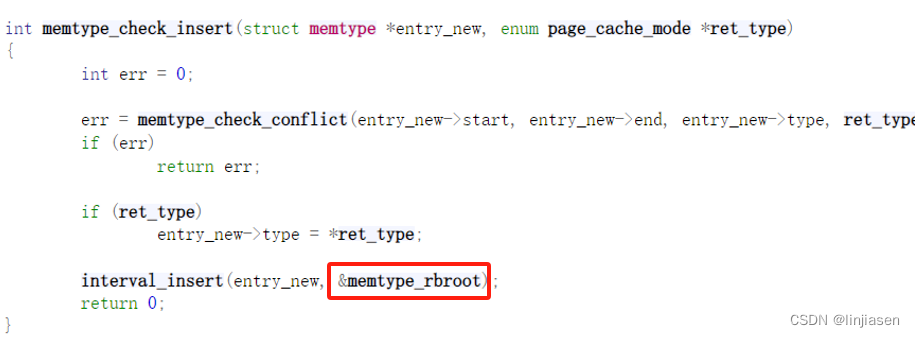
3.5、哪些接口会调用memtype_check_insert
./kprobe -s 'p:myprobe memtype_check_insert'
可以看到涉及到使用MMIO的下面接口都会调用memtype_check_insert




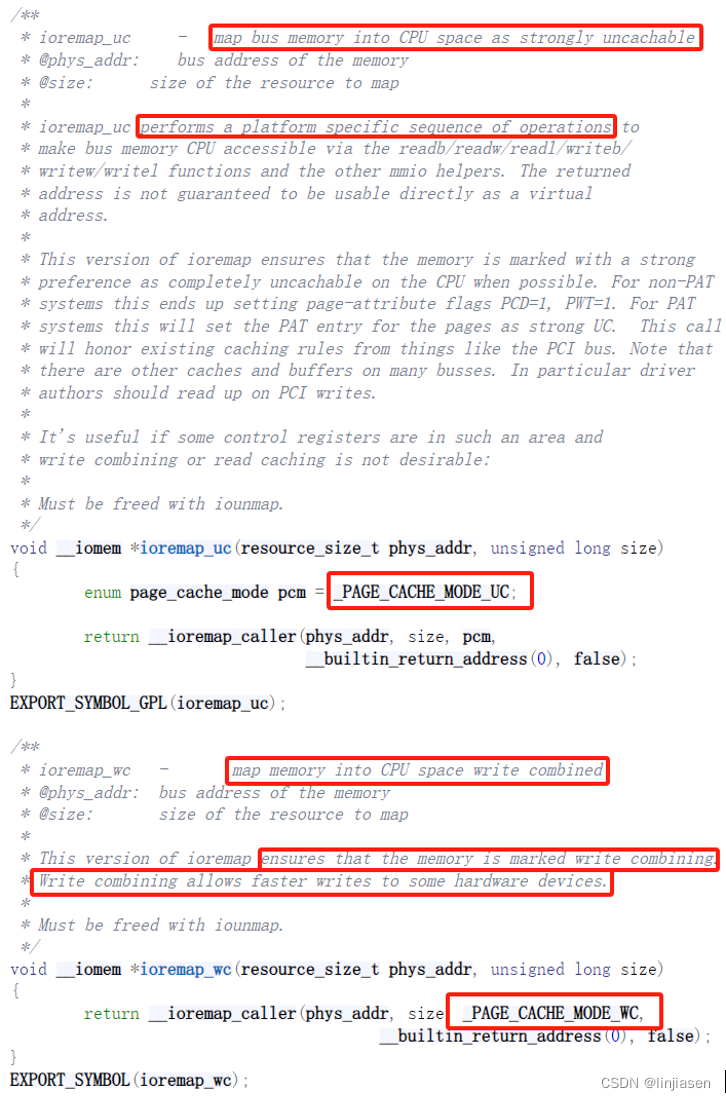
3.6、ioremap和ioremap_wc区别
ioremap.c - arch/x86/mm/ioremap.c - Linux source code (v5.15) - Bootlin
ioremap和ioremap_wc区别就是传入的page attribute不一样。最终还是会调用memtype_check_insert把对应的entry放到memtype_rbroot。
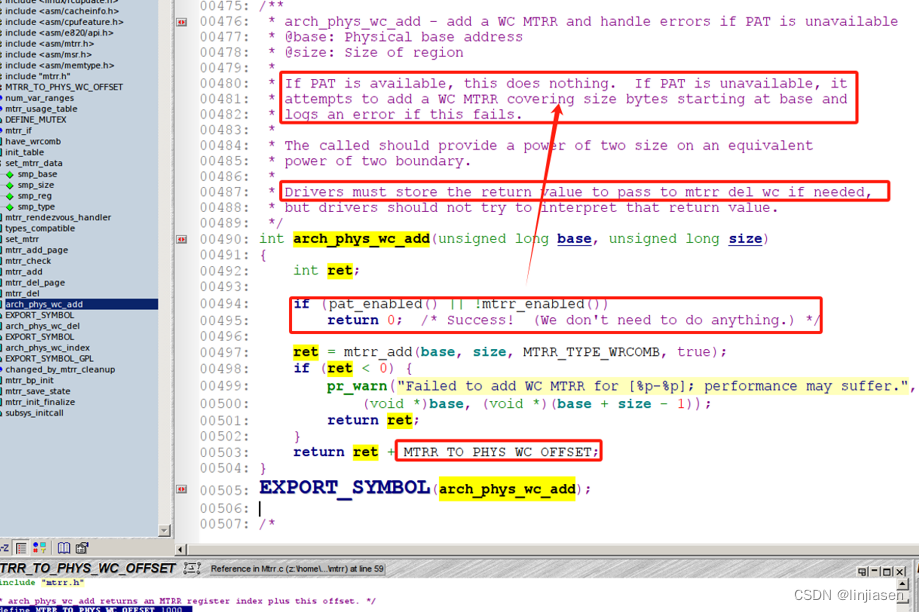
3.7 arch_phys_wc_add
linux kernel 3.11.0增加了arch_phys_wc_add
如果pat_enable已经enable或者mtrr_enable没有enable,arch_phys_wc_add直接返回了。
四、开启write combine后访问MMIO提升的原因
回到我们最初的问题,使用memcpy 把32M数据从system main memory拷贝的到GDDR,开启write combine后,CPU写的性能提供了13.3倍。这是怎么做到的呢?在回答这个问题前,我们先看看两种场景下PCIe trace的差异。
1、disable write combine时PCIe trace
我们从PCIe trace上看到第一笔写到最后一笔写,耗时是90753us,和测试代码抓到的耗时(90707us)一致。
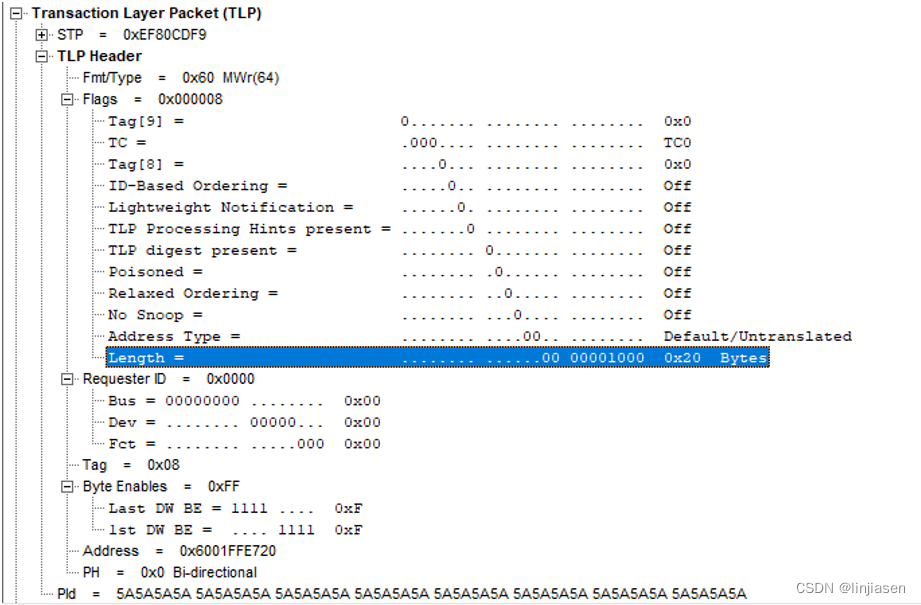
分析trace可以发现,disable write combine时,所有写请求都是32byte的,32M的数据需要32M/32= 1,048,576笔操作。
这里为啥每一笔写请求都是32byte,而不是4byte的,和glibc对于memcpy的实现有关系,这里不展开说明,有兴趣的看glibc的memcpy作者马凌的回答。
https://www.zhihu.com/question/35172305
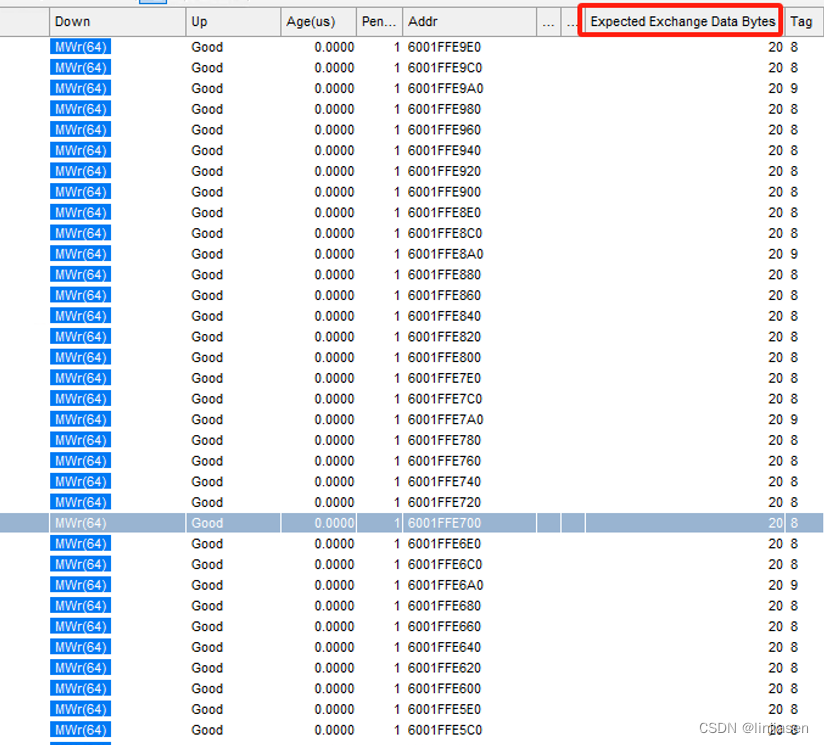
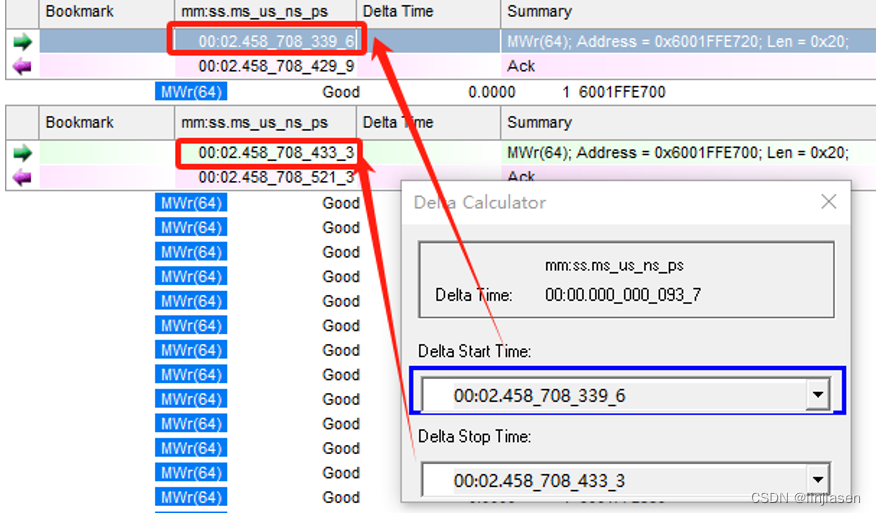
随机找了两笔相邻的请求,时间间隔93ns,看了一下统计基本上在80-100ns之间,个别可能超过100ns。1,048,576笔传输,耗时90753us,每传输32Byte耗时90753us/1,048,576=86.5ns,每传输64Byte需要耗时173ns。
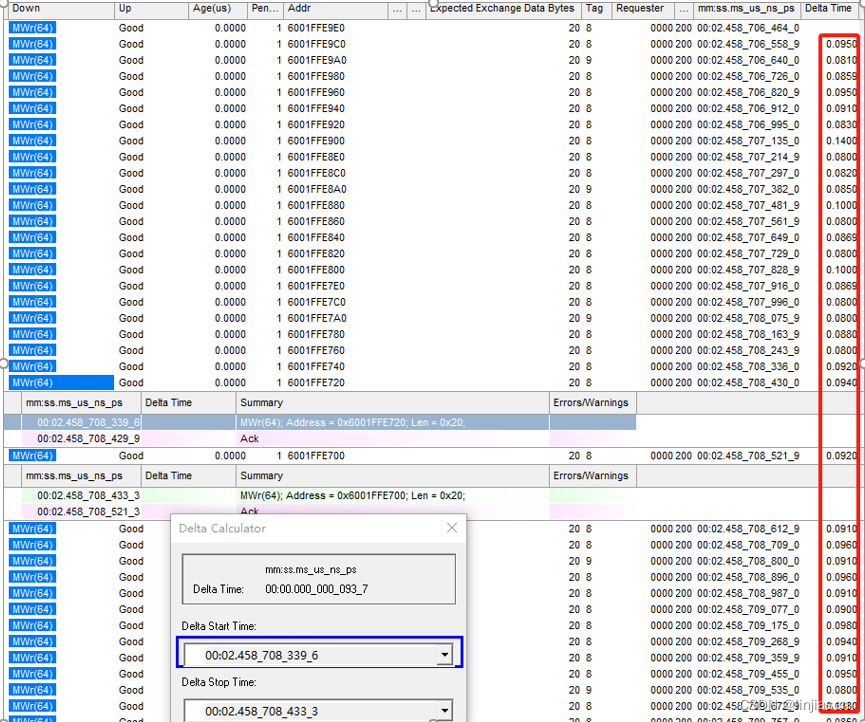
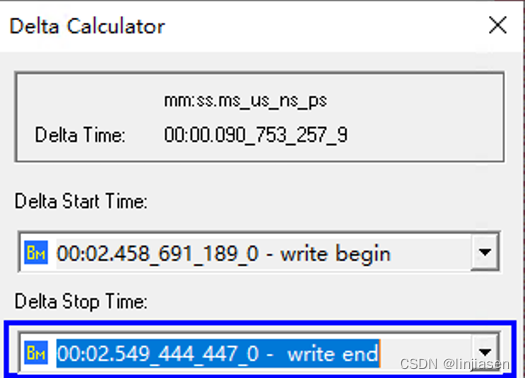
2、enable write combine时PCIe trace
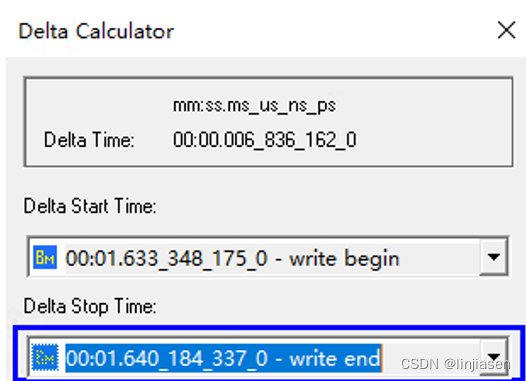
我们从PCIe trace上看到第一笔写到最后一笔写,耗时是6836us,和测试代码抓到的耗时(6837us)一致。
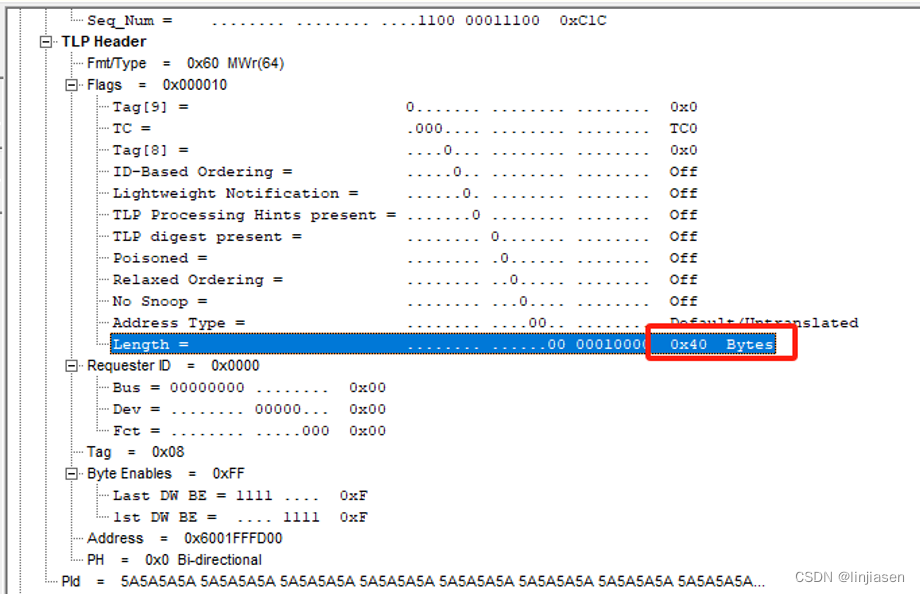
分析trace可以发现,enable write combine时,所有写请求都是64byte的(和前面intel architecture介绍的WC buffer是64Byte是吻合的),32M的数据需要32M/64= 524,288笔操作。
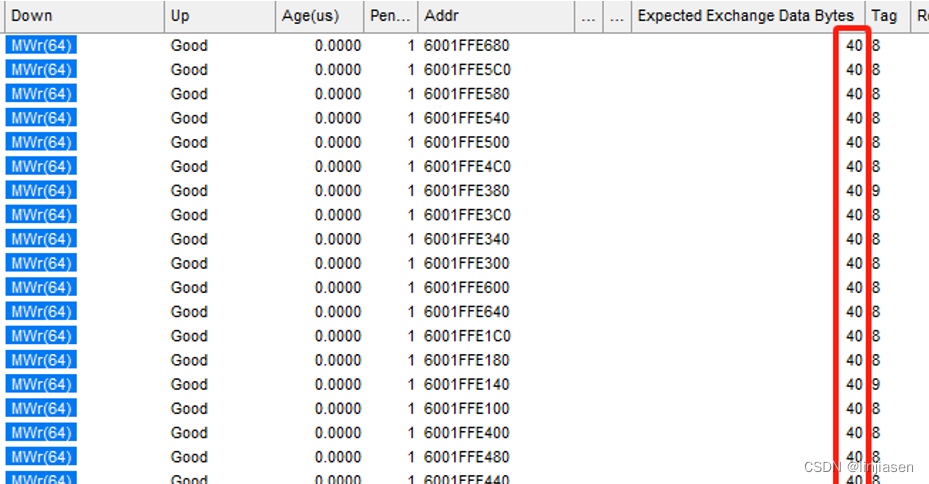
随机找了两笔相邻的请求,时间间隔8ns,看了一下统计差异比较大,大部分都在10~20ns之间。524,288笔传输,耗时6837us,每传输64Byte耗时6837us/524,288= 13ns,数据是吻合的。
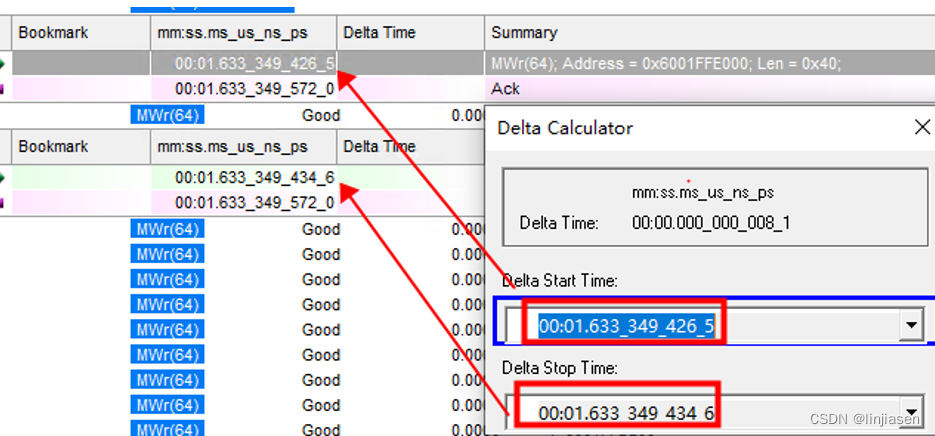
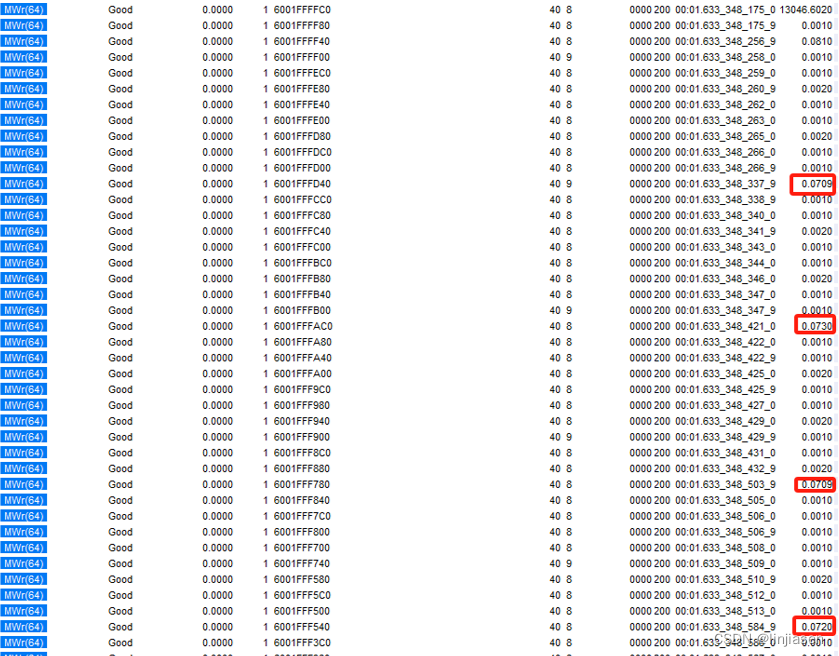
猜测每次时间间隔比较大的时候,都是处理器在fill WC buffer的时候(只是猜测,没有datasheet没法证明),只是这种猜测符合WC memory delay and combine的设计。
总结
使用memcpy 把32M数据从system的main memory拷贝的到GDDR,开启write combine后,CPU写的性能提高了13.3倍,主要原因不是写的transaction的combine(transaction数量只少了一半),而在于数据被处理器从main memory预取到write combine buffer,然后从write combine buffer使用burst 传输方式推送到system bus,这种burst传输方式提高了传输效率,这个时间(10多ns)比从main memory取数据的时间短的多(100多ns)。
 上图中architecture中的这两段话值得多读几遍,这是为什么write combine可以提高CPU写的原因所在。
上图中architecture中的这两段话值得多读几遍,这是为什么write combine可以提高CPU写的原因所在。
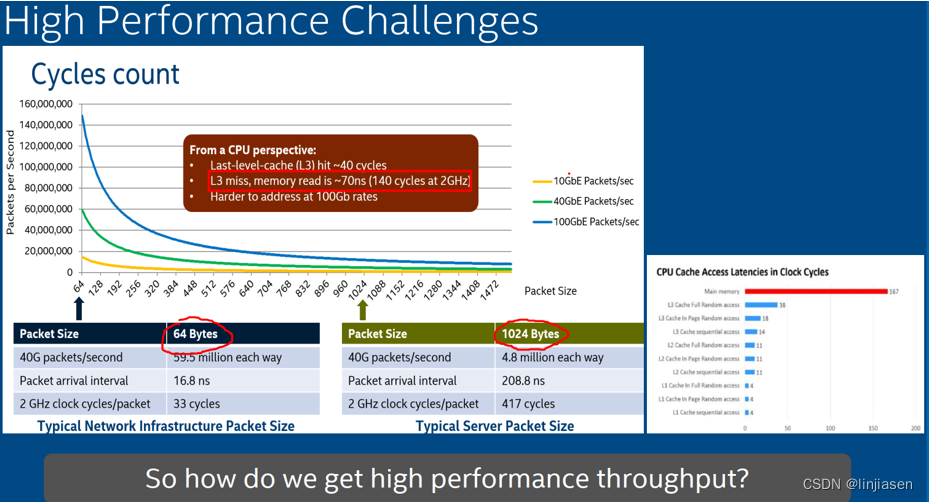
手上没有11th Gen Intel(R) Core(TM) i7-11700 @ 2.50GHz的资料,只有一个skylake的资料,看到从main memory读大概需要167*0.5(2GHz)需要83ns,考虑到server级别的CPU,而11th Gen Intel(R) Core(TM) i7-11700 @ 2.50GHz是消费级别的CPU,会被skylake弱一些,我们抓的数据是符合预期的。


















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











