







前方高能警告:这篇文章很长很长,有31页word。主要介绍了,PCIe No Snoop,TPH,传统DMA、DCA、intel DDIO的数据流对比。
一、No Snoop含义

当transaction往memory写数据或者从memory读数据时,需要检查CPU内部cache,用来查看对应的memory区域是否已经被copy到其他CPU的cache中。如果对应的memory区域已经被copy到其他CPU cache了,在请求transaction被允许访问memory前,cache内容可能需要被写回memory或者把cache状态变为invalidated。这就是所谓的snoop,这个过程需要一定时间并且会增加请求的时延。
有时,软件知道请求的区域不会在CPU cache中(或许因为该区域被system定义为uncacheable),因此,snoop不是必须的,并且可以跳过这一步。No snoop bit正是为了这种情况而添加的。
关于snoop,Intel64 andlA-32 Architectures Software Developer's Manual的11.2 CACHING TERMINOLOGY讲得比较清楚了。

在MP(多处理器)系统中,像Intel486和Intel 64这样的处理器具有snoop(侦听、监视)其他处理器访问system memory和访问处理器internal cache的能力,也就是所谓的“snoop”。 Snoop的功能让处理器的internal cache与system memory和总线上其他处理器中的cache保持一致。
例如,在Pentium和P6系列处理器中,通过snoop功能,如果处理器A检测到另一个处理器打算写一块memory location,而这块memory location已经自己被cache,并且cache状态是shared,侦听处理器A就会invalidate自己的cache line,强制让自己在下一次访问相同的memory location时执行cache line fill的操作(从system memory来获取最新的数据)。
从P6系列处理器开始,如果一个处理器A通过snoop功能检测到另一个处理器正在尝试访问一块memory location,而这块memory location已经在自己的cache中修改,但尚未write back到system memory,那么侦听处理器A将向其他处理器发出HITM#信号(Hold In Transaction Mode),这个信号告诉其他处理器该cache line已经处于modify状态并且将会发出modified data的write-back。
在这种情况下,具有有效修改数据的处理器可能会直接将此数据传递给请求处理器,而不立即将其写回system memory中。负责管理系统内存的memroy controller监视此操作,以确保系统内存最终得到最新的数据。因此,即使数据可能在处理器之间共享而不立即写回内存,内存控制器也确保系统内存最终反映出最新的数据。。
也就说,任何一个处理器别想偷偷干坏事(让自己的internal cache和其他处理的internal cache不一致),其他处理器一直在偷偷看着呢。

Memory 请求说明:
- memory data不允许跨越4KB边界
- 为了改善性能,所有的memory-mapped write都是posted
- 可以使用32bit或者64bit地址
- Data payload size是0-1024DW(0-4KB)
- Qos可能会被使用,最多有8 Traffic Class
- 当target是main memory时,No Snoop属性可以减轻系统snoop处理器cache需求
- 为了改善性能,Relax order属性允许数据路径上的设备应用Relaxed order规则。
二、TLP中的No Snoop bit和Device Control Register的Enable No Snoop
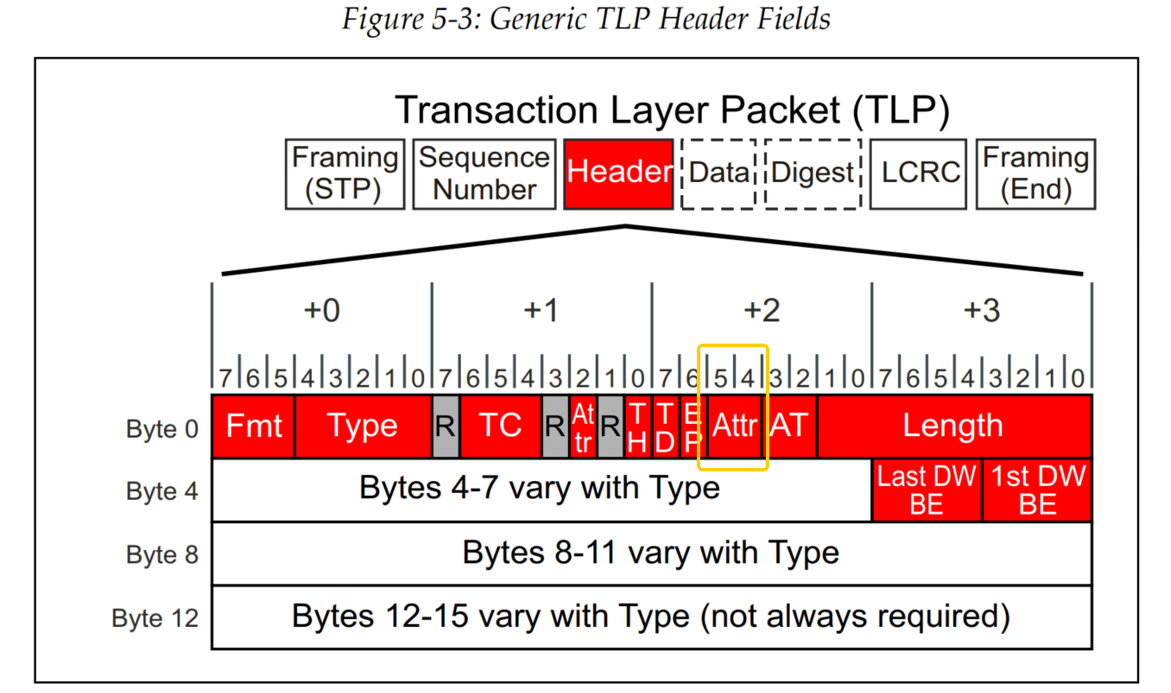


TLP的Byte2的bit4是No Snoop属性,如果该bit是1,则说明对于该TLP,requester表示没有host cache coherency的问题存在。对于这个请求,System hardware可以跳过正常的processor cache snoop。
如果该bit是0,则PCI-type的cache snoop包含是必须的。需要system hardware确保cache coherency。
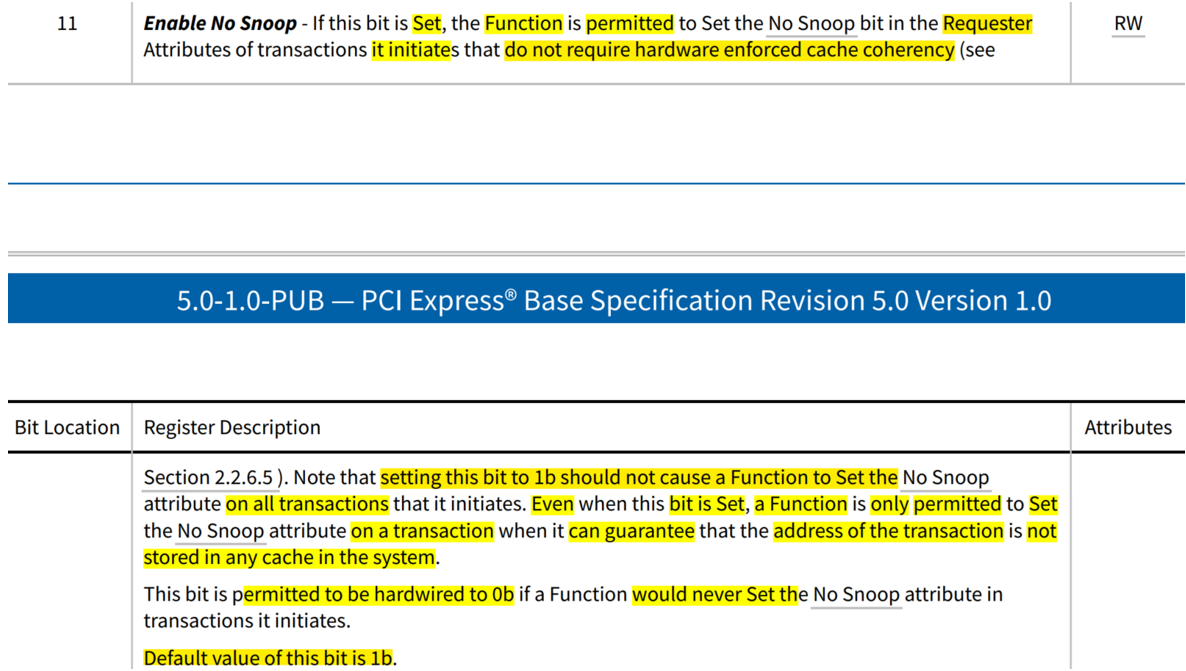
Device Control Register的bit 11:Enable No Snoop是RW属性。
如果该bit是1,则允许function在请求者的transaction属性中设置No Snoop bit,表示不需要hardware来确保cache一致性。值得注意的是设置该bit为1,并不意味着该function发出的所有transaction的No snoop属性都设置1。甚至当该bit为1时,只有function可以保证 transaction中地址没有cache问题时,才能设置对应的transaction的 No Snoop bit为1。
如果一个function永远不会设置它发出的transaction的No Snoop属性,允许被hardware成0。Intel的CPU就是这么处理的。

三、Root Complex的snoop问题和解决方法


Snoop问题:通常,任何时候访问system memory,都可能访问到处理器认为cacheable的位置(这意味着处理器有权限在本地cache中存储临时副本)。
如果外设试图访问memory区域,在允许访问memory区域前,chipset必须首先检查处理器的cache,因为cached 中的数据可能已经修改了。如果cached 中的数据可能已经修改了,则在外设访问memory之前,需要把已经修改的数据write back到memory。
虽然,确保memory一致性是必需的,但是snoop的过程需要时间。这个过程需要多长时间通常是有限的,但是不可预测,因为它取决于当时CPU正在执行的其他操作。根据时序要求,这种不确定性可能会破坏同步的data flow。

Snoop解决方案:避免snoop的一种方法是让设备只访问被指定为uncacheable的memory区域。
另一种选择是让软件在高优先级数据包头中设置“No Snoop”属性bit。设置了No Snoop bit后,无论内存类型是什么,将会让chipset强制跳过snoop的步骤,直接访问memory,因为软件已经保证这样做不会引起问题。
为了将此作为isochronous path的要求,硬件可以在Root Port为高优先级虚拟通道(VC)初始化另一个bit,称为“Reject Snoop Transactions”。这样做的目的是只允许No Snoop bit为1的transaction 通过该VC。任何没有设置该属性的传入数据包都将被丢弃(当做UR),以确保时序永远不会因为等待snoop而受到影响。

VC Resource Capability Register的bit 15:Reject Snoop Transactions是HwInit属性。
如果该bit是0,不管transaction中No Snoop bit是1还是0,都会被该VC接受。
如果该bit是1,则任何No Snoop属性是applicable但是不为1的transaction都被当成UR。
该bit只对Root Port和RCRB是合法的。
四、传统的DMA、DCA和DDIO数据流简介
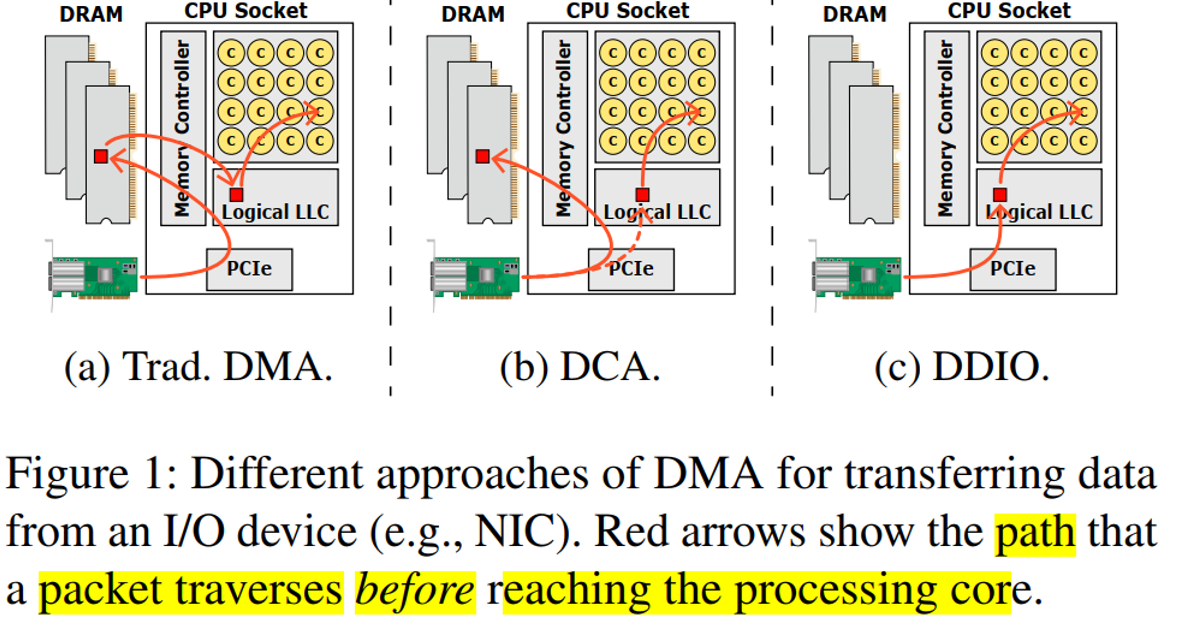
这里介绍传统的DMA、DCA(Direct Cache Access)和增强型DCA(DDIO)的数据流。
1、传统的DMA
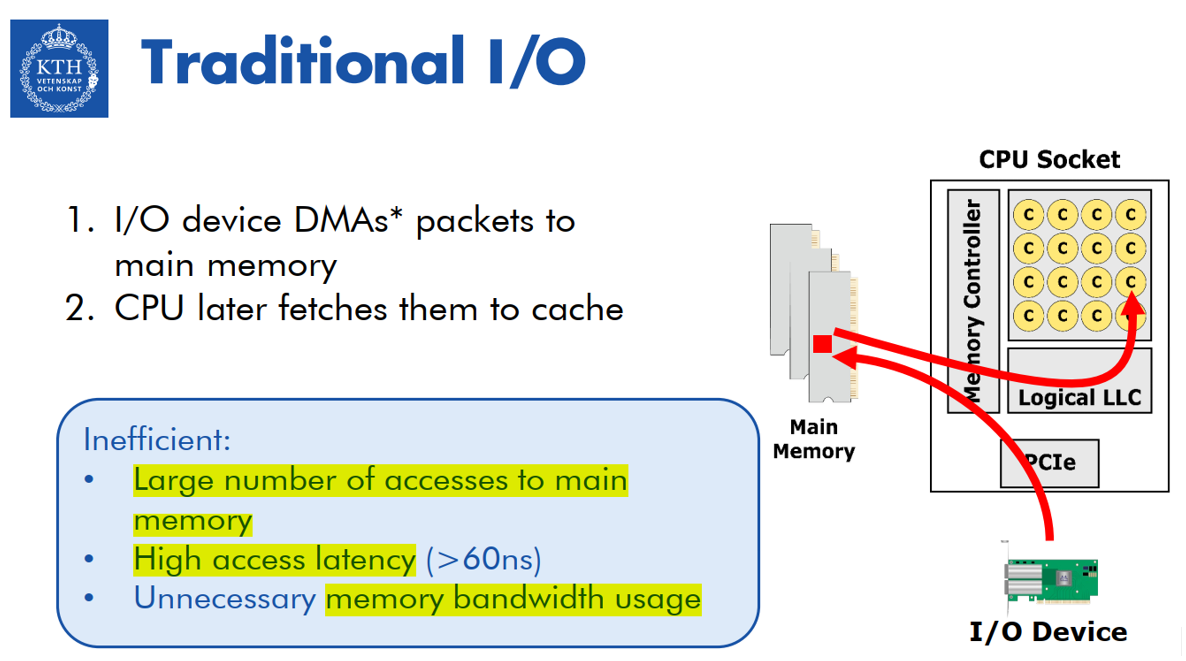
- 软件instructed 处理器提供一系列memory地址(如RX描述符/TX描述)给IO设备。
- IO设备通过DMA,直接从main memory中读数据或者写入数据到main memory。
- 对于inbound traffic(IO write),处理器通过接收中断或者轮询 IO设备知道数据被IO设备(DMA)写到了main memory。接下来处理器将IO数据从main memory 预取到自己的cache中,并处理这些数据(详细见后面)。
- 对于outbound traffic(IO read),处理器在memory中创建数据结构(cache miss,需要从memory中读到处理器cache),然后通过TX描述符通知IO设备数据已经准备好了。接下来IO设备需要先读取TX描述符,然后读取data。由于数据是最近由CPU上的软件创建的,所以有很大概率这些数据已经存在于CPU的cache层次结构中,如果data在cache中,则从cache转发给IO设备,但是data可能会被从cache中驱逐(详细见后面)。
2、DCA(Direct Cache Access)
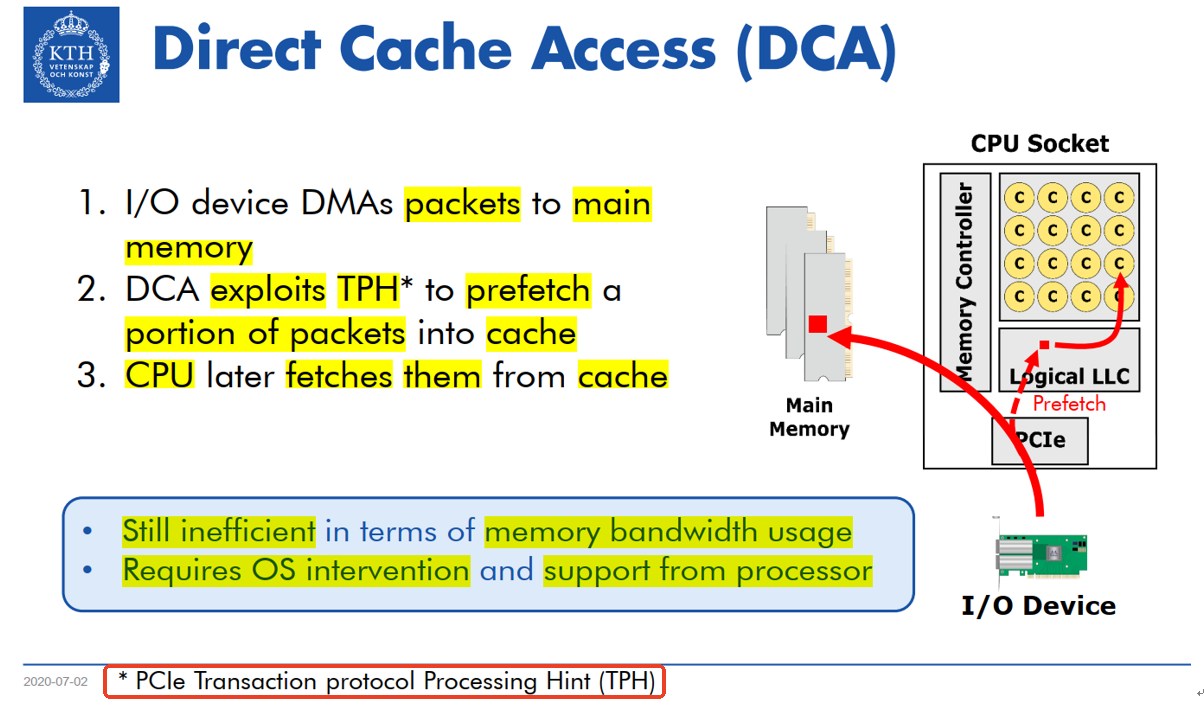
为了解决多次访问memory的问题,intel在2005年引入的DCA(Direct Cache Access)。DCA技术使用PCIe TLP的TPH使得可以将部分 I/O 数据预取到处理器的cache中,但是DMA数据还是放在main memory (详细见后面)。
这一方法可能克服传统 DMA 的缺点,从而实现最大的 I/O 带宽并减少处理器的停滞时间。尽管这种实现 DCA 的方式可以有效地预取所需的部分I/O数据(例如描述符和数据header),由于整个数据包仍然需要 DMA 传输到main memory,memory带宽利用率仍然很低。
此外,这还需要OS的干预,需要 I/O 设备、系统chipset和处理器的支持(后面会介绍)。
3、DDIO(Intel Data Direct I/O)
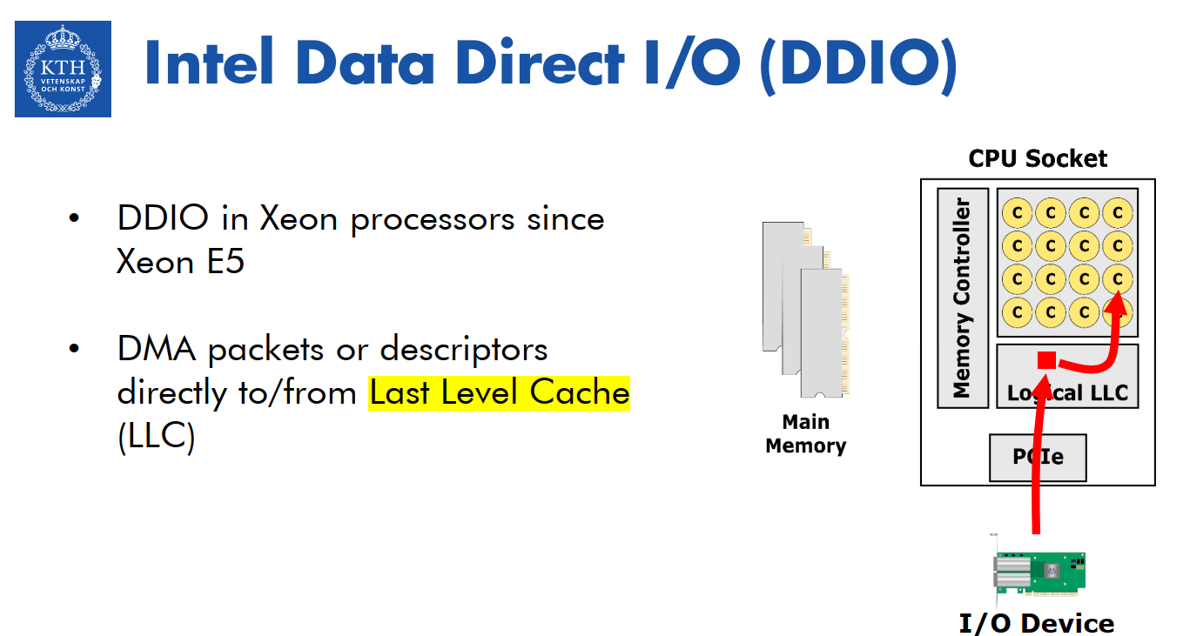
为了解决上面的问题,intel在2011年重构了DCA,引入了 DDIO。允许I/O 设备可以直接对LLC进行DMA读写而不是system memory(详细见后面)。
四、TPH简介

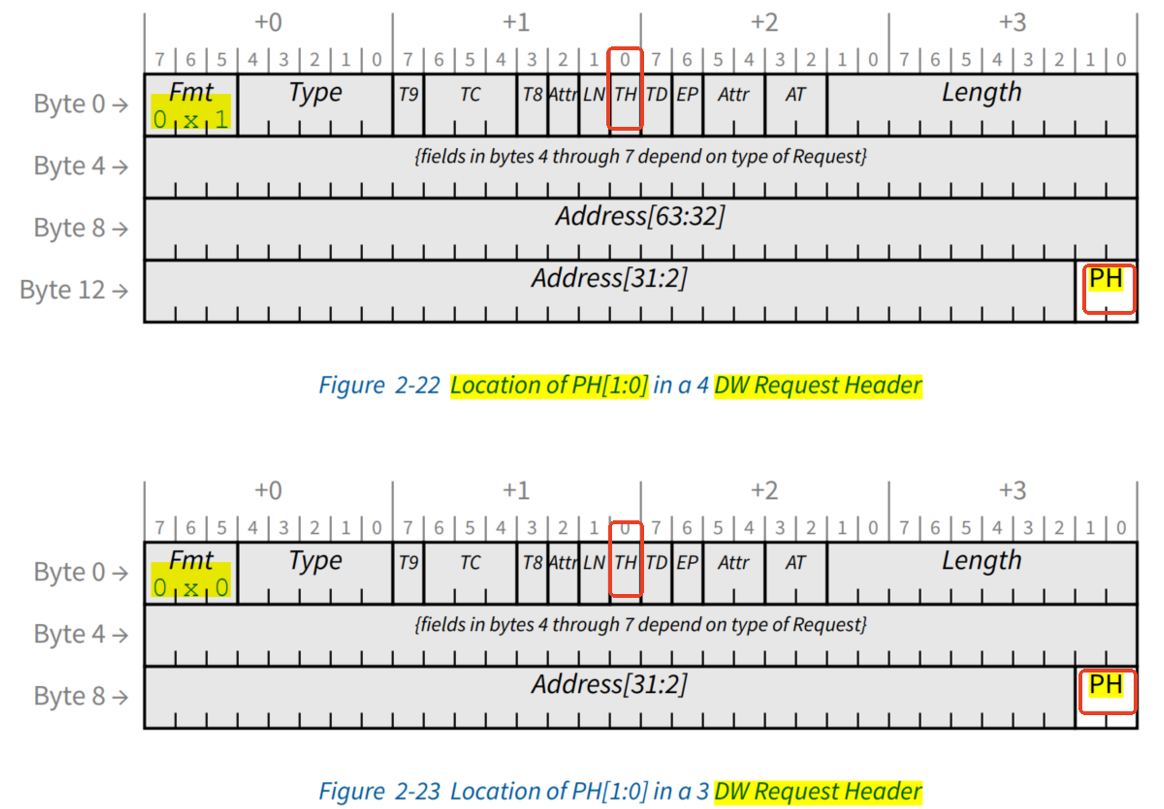
TPH是一个可选的feature,这个feature通过在request TLP header 中提供hints信息,来优化针对memory space请求的处理。Processing Hints使得系统硬件(Root Complex和Endpoint)能够基于每个TLP来优化平台资源(例如系统和memory互联)。
TPH机制定义了Processing Hints,这些hints提供了endpoint和root complex之间通信模型的信息。System software发现并识别TPH capability,以确定每个支持TPH的function的Steering Tags的分配。
TPH Requester Control Register的 TPH Requester Enable bit为1时, TLP中的TH 为1b,则表示存在TLP header存在TPH和可能的TPH TLP Prefix(TPH Requester Capability Register 的Extended TPH Requester Supported),当TH为0b,则PH字段是reserved。

Function作为requester,如果要生成带有TPH的TLP,就需要实现TPH Requester Extended Capability并且需要系统软件设置TPH Requester Enable bit。
Function作为completer,如果要处理携带TPH的TLP,就需要通过Device Capabilities 2 register的bit13-12来表示自己作为completer有处理处理带有TPH的TLP的能力。
TPH针对memory space的transaction,适用于device-to-host,device-to-device和host-to-device的数据流。在每种数据流的情况下,如果要支持TPH,Requester、Completer以及所有的intermediate都必须支持相关的TPH能力。
软件通过PH Requester Extended Capability发现requester有生成带有TPH的请求TLP的能力,通过Device Capabilities 2 register的bit13-12发现completer有处理带有TPH的TLP的能力。
软件必须使能TPH Requester Extended Capability的TPH Requester Enable 字段,让function能够发起带有TPH的请求。
TPH通过供额外信息,仅针对memory space的请求进行优化。因此,管理memory space访问的现有机制和规则(例如,bus master、memory space enable和base address register)都不会改变。
五、传统的Device Write Host Read和支持TPH的Device Write Host Read
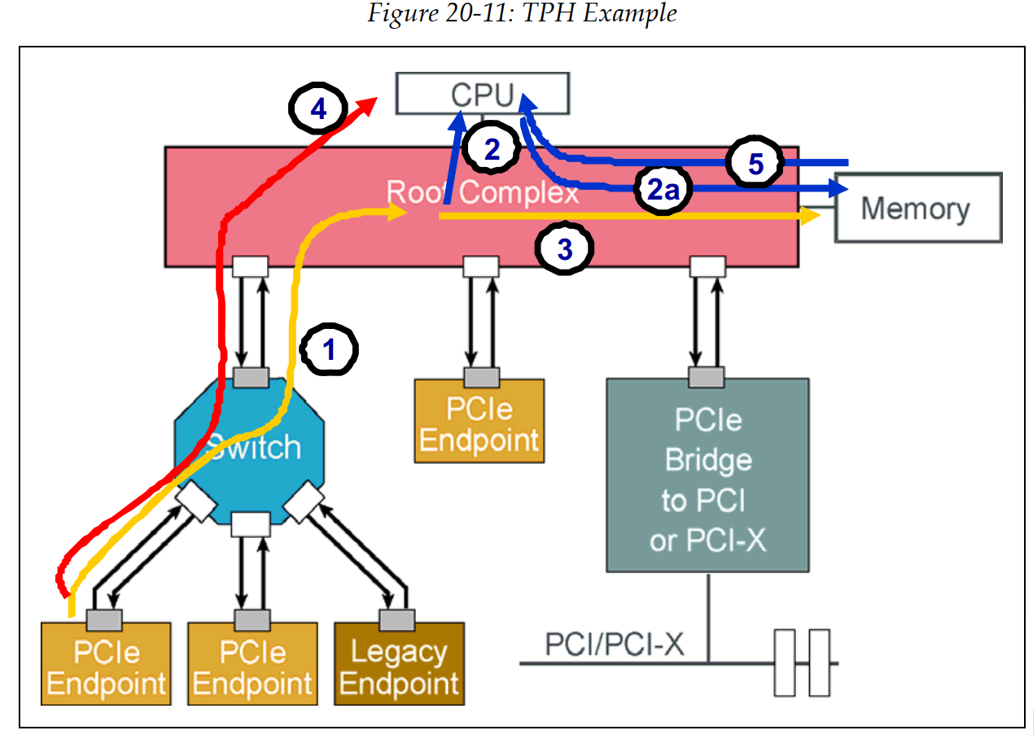

1、没有TPH的Device Write数据到memory,然后CPU Read 的数据流:
- Endpoint首先发送一个memory write TLP,TLP的地址是system memory,这个数据包被路由到Root Complex。
- RC识别出这是一个cacheable的memory space的访问,就会暂停这个访问的处理,并在检查CPU cache。主要检查write的address在CPU cache是否有对应的cache line,如果是,在这个write transaction被处理前,CPU需要执行write-back用来更新system memory(步骤2a)。。
- 一旦任何write-back完成,RC才允许memory write请求更新system memory。等待write-back后再执行endpoint write的原因是:如果CPU在Endpoint写入数据后再执行了cache flush操作,并且使用了不同的数据(例如0xBB)覆盖了system memory,那么Endpoint写入的数据(0xAA)就会被丢失,system memory的数据将被CPU cache中的脏数据(0xBB)所覆盖。
- EP通知CPU数据write完成(一般是通过中断,或者CPU poll EP状态)。
- 最后,CPU从system memory中获取数据。
2、有TPH的Device Write数据到memory,然后CPU Read的数据流:
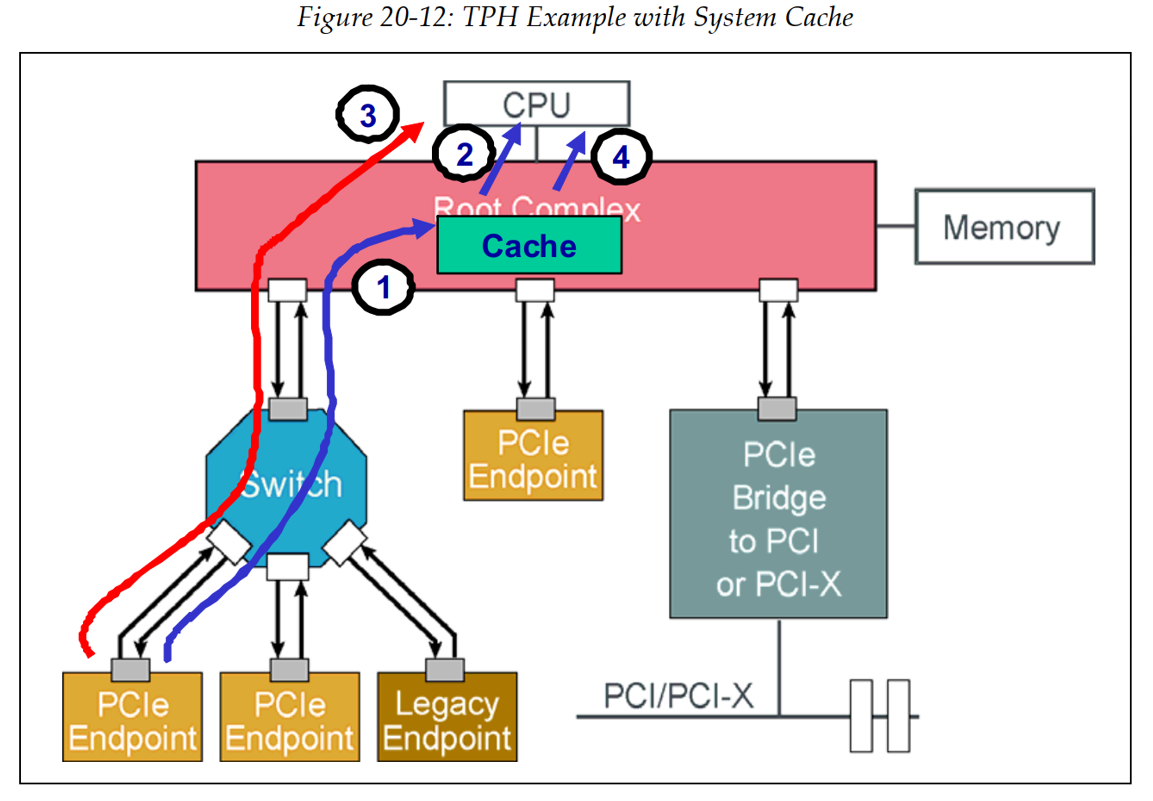

- Endpoint首先发送一个memory write TLP,TLP的地址是system memory但是这个TLP包含了TPH bits。Memory write被路由到Root Complex。
- RC识别出这是一个cacheable的memory space的访问,需要上面flow一样进行snoop操作。一旦snoop操作完成,RC就会根据TPH bits把这个TLP存储到cache而不是直接写入到system memory。
- EP通知CPU数据write完成(一般是通过中断,或者CPU poll EP状态)。
- 最后,CPU从指定地址读取数据,但现在数据在中间cache中找到,因此请求不会访问system memory。这带来了cache设计的典型好处:更快的访问时间以及减少system memory的traffic。
更复杂系统中,cache可能在switch或者其他位置。
六、支持TPH的Host Write Device Read
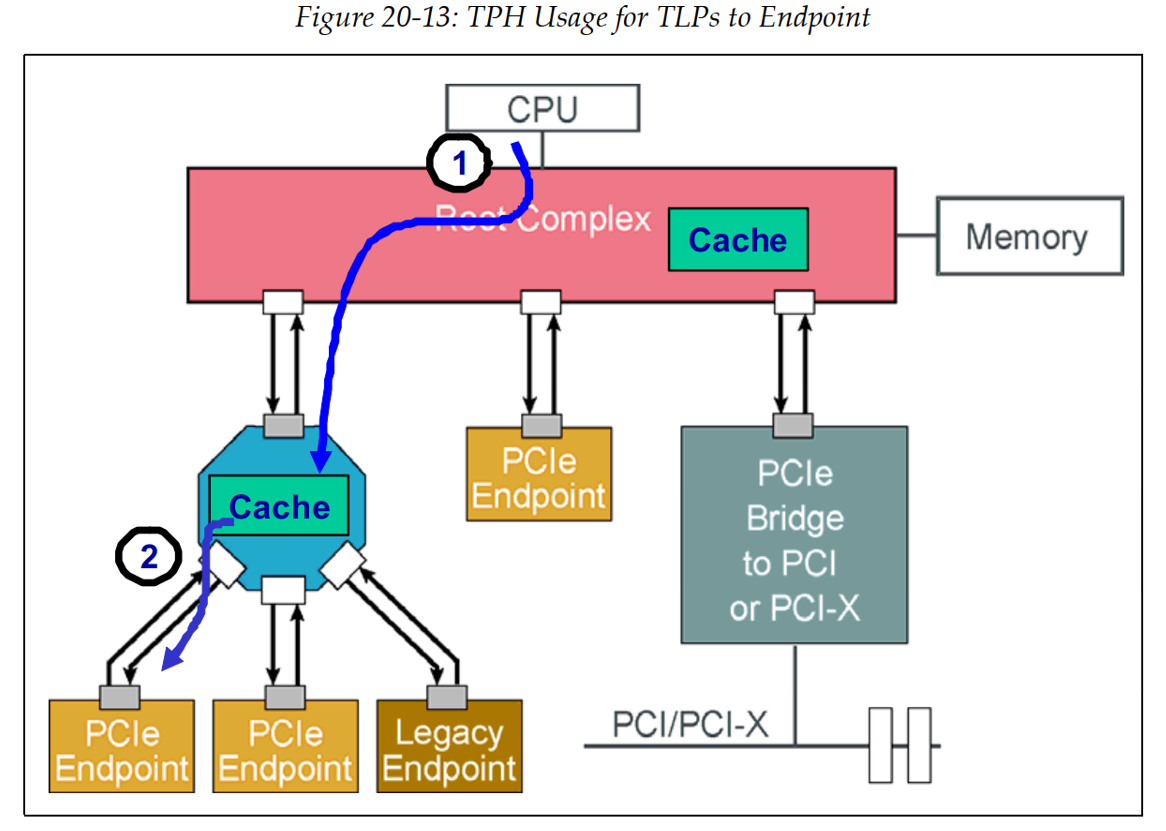

1、有TPH的Host Write, Device Read的数据流:
为了说明相反方向的概念(称为Host写入,Device读取或HWDR)。
- CPU发起一个memory write请求,请求的地址是PCIe Endpoint。数据包包含TPH bits,这些bits告诉RC,数据包应该被存储在靠近EP的中间cache中,而不是在之前示例中使用的RC中的cache中。在这种情况下,内置于switch中的cache起到了作用。
- 然后,TLP在第二步被转发到endpoint。
如果数据模型是:endpoint不频繁更新数据,但是经常读数据,这种模型是有益的。Endpoint到system memory的memory read操作被到switch cache的read操作替代,从而减轻了从switch到RC的链路以及到memory路径的负担。
七、支持TPH的Device to Device
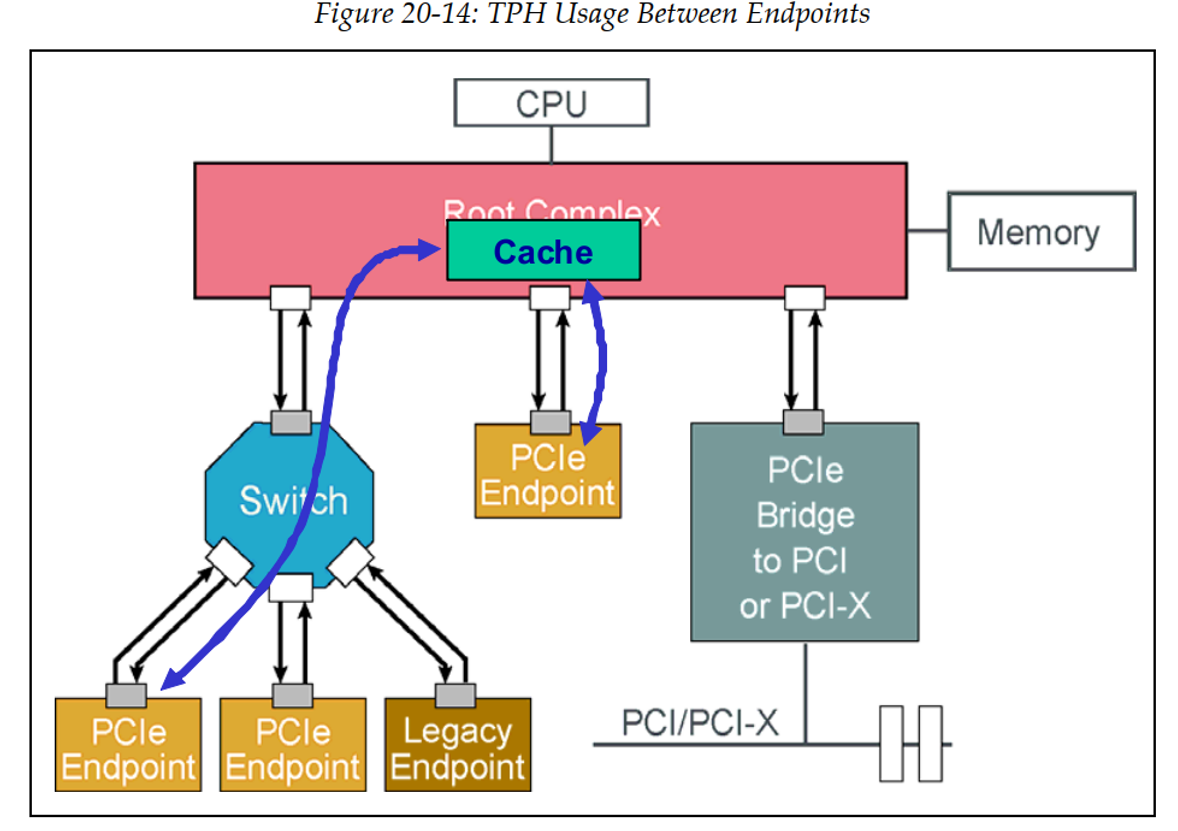

1、有TPH的Device to Device的数据流:
两个endpoint通过共享内存位置相互通信(称为Device Read/Write to Device Read/Write或DD),这个内存位置由TPH bits指向一个中间cache。在这种情况下,两者都可能更新memory中不同location,这些location需要被处理为“read mostly”(数据被读取的频率远高于被写入的频率),或者一个endpoint可能更新数据,另一个endpoint需要多次读取的数据。在这两种情况下,使用中间cache都可以提高系统性能。
八、intel DDIO背景

在IO速度比较慢,并且处理器的cache比较小的时代,系统被设计成:main memory是IO数据主要的目的地和来源,而不是宝贵的cache资源。这导致I/O数据传输需要多次“强制”访问内存子系统,以获取和传递I/O设备所需的数据。这也使得cache中缺少CPU不经常使用的I/O数据。这些访问使得内存子系统的负载达到链路速度的五倍,迫使CPU和I/O子系统运行更慢,消耗更多功率。
现状已经改变:Intel® Xeon®处理器E5产品系列支持高达20 MB的LLC,cache资源不再稀缺。Intel已经更新了Intel Xeon处理器的架构,通过Intel DDIO,允许Intel以太网控制器和适配器与host cache直接通信,消除了经典模型中的低效性。
通过消除了经典模型中频繁访问main memory的情况,减少了功耗,提供了更大的I/O带宽可扩展性,并降低了延迟。Intel DDIO是一项平台技术,它使得I/O数据传输几乎不需要访问memory(在最理想的情况下接近零次)。通过这样做,Intel DDIO显著提高了性能(更高的吞吐量、更低的CPU使用率和更低的延迟),并降低了功耗。
总结来说,DDIO允许I/O设备与CPU core共享LLC的所有权(即:I/O设备也可以读写cache line),这么做可以提高IO的性能,但是,对于非I/O的工作负载,如果CPU core被分配了与DDIO正在使用的相同的LLC ways,可能导致32%的性能下降(也就是说I/O设备可能与CPU core竞争了LLC资源)。
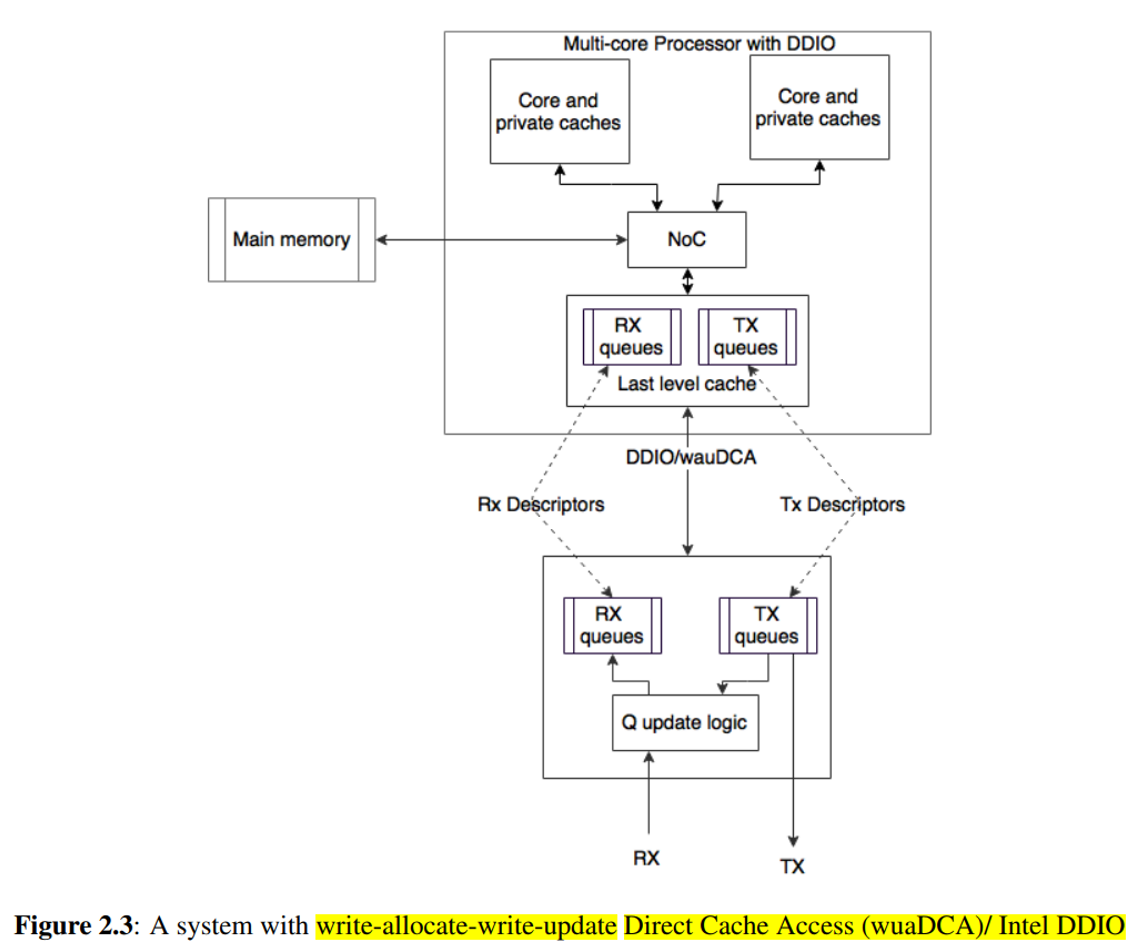
使用Intel DDIO,intel 以太网服务器适配器和控制器可以直接与处理器的cache通信,而不必通过system memory。Intel DDIO让处理器的cache成为IO数据的主要目的地和数据源而不是main memory。通过避免对system memory的多次读写,Intel DDIO降低了延迟,增加了系统I/O带宽,并减少了功耗。Intel DDIO在所有基于Intel Xeon处理器E5的服务器和工作站平台上默认启用。

数据消费(IO read)操作:I/O设备在需要从main memory中读取数据时启动此操作。例如,网卡(NIC)在执行发送数据包的操作时,会触发I/O读取操作,从main memory中获取要通过网络发送的数据包和控制结构。
数据交付(IO write)操作:I/O设备在需要将数据写入main memory时启动此操作。例如,NIC在从其连接的网络接收数据时,会触发I/O写入操作,以便将接收到的数据写到main memory中。
以下部分将描述这些交互,以CNA为例。一般来说,这些交互可以推广到其他I/O设备。
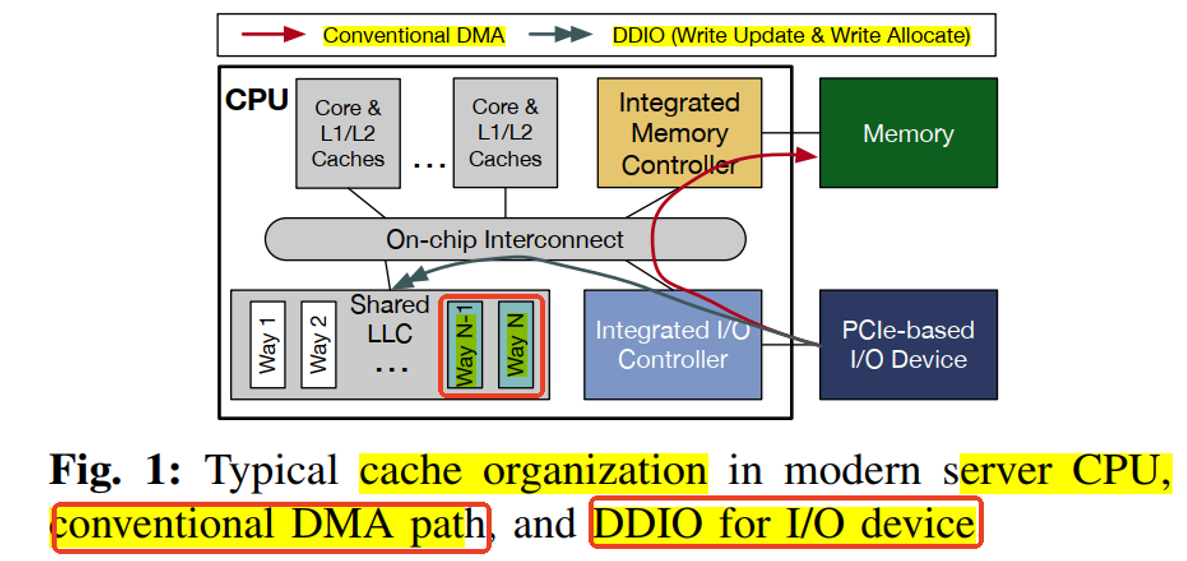
九、没有DDIO的Device Write Host Read

当I/O设备将数据从设备传输到host时,会启动数据传输或写入操作。以NIC为例子,当NIC从网络接收到数据包或需要传递给主机软件进行处理的控制结构时会发送write操作。
数据传输始于NIC从网络接收数据包;接收到的数据包和任何伴随的控制数据被传输到主机进行协议处理。如果协议处理成功,数据包的有效载荷将被传递到一个应用程序。这涉及到将数据以及任何伴随的控制结构带入CPU的cache层次结构,供主机上运行的软件最终读取。
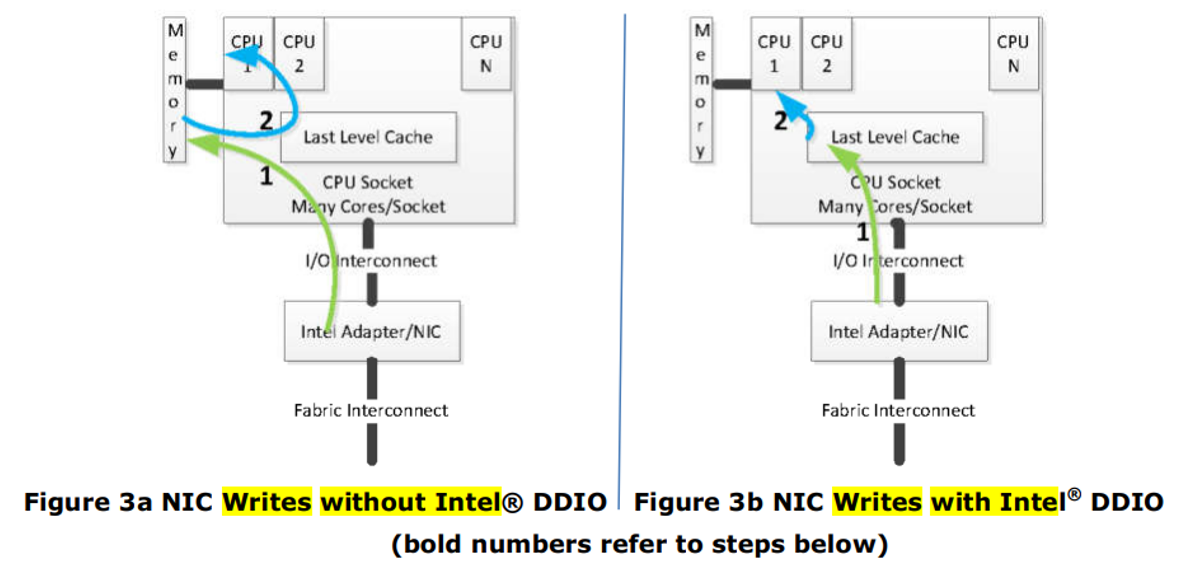

步骤 1:
数据传输操作由NIC将数据(数据包或控制信息)传输到host memory。如果被传输的数据恰好在CPU的cache层次结构中,cache中数据将被置为失效(如果cache hit,则需要先执行write back操作,把CPU cache中的数据先写到system memory,然后再执行NIC write)。
步骤2:
运行在CPU上的软件读取数据以执行处理任务。这些数据访问操作会cache miss(见步骤1的解释),并导致数据从memory中读取到CPU的cache层次结构中。
十、有DDIO的Device Write Host Read
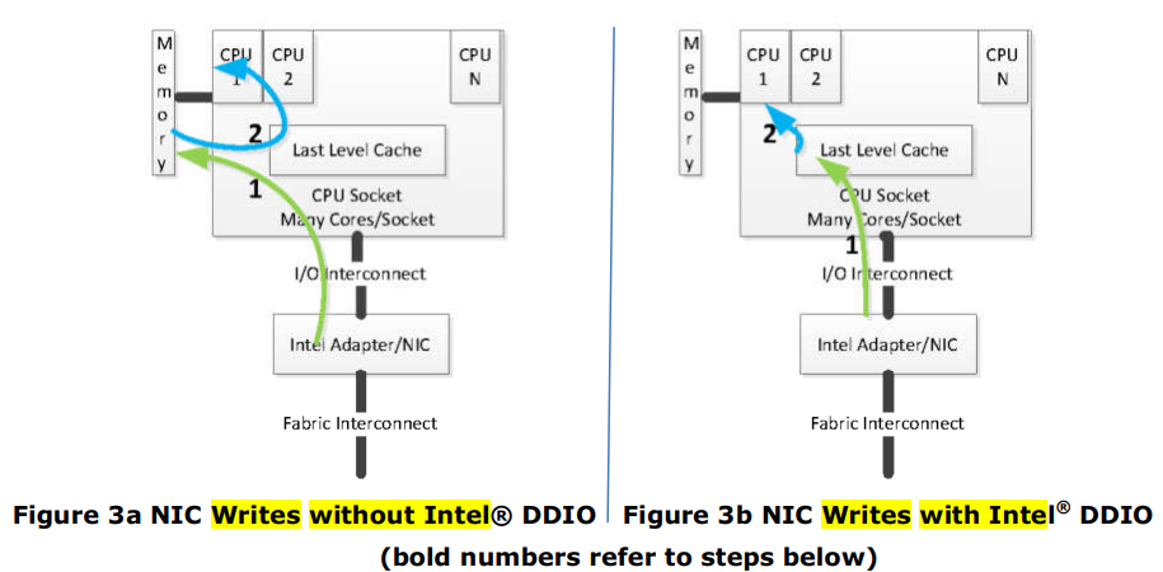

步骤1:
IO Write使用Write Update和Write Allocate操作(取决于是否cache hit),数据直接被写到cache而不是memory。
步骤2:
随后由软件发起的CPU读取操作由cache中的数据满足,不会导致cache miss。
Write Update(IO Write LLC hit):如果正在传输的数据的memory address在 CPU的cache层次结构中已经存在,那么不需要访问memory,CHA直接使用inbound data更新LLC 中的cache line。
注意:虽然LLC hit是IO write最理想的结果,但是如果在其他的cache agents也发现了数据副本(比如在另外CPU socket的core),就需要进行snoop操作以使这些cache agents中的数据失效,以保持一致性
Write Allocate(IO Write LLC Miss):如果正在传输的数据的memory address不在CPU的cache层次结构中,则在CPU cache层次结构的LLC中分配空间,然后DDIO把数据写到在LLC中allocate的cache line中,同样不需要访问memory。
现实情况远比上面讨论的复杂,详细的可以参考:

Write Allocate操作被限制在LLC的10%以内,这是阻止数据流未被CPU消费和数据流入速率快导致cache pollution的一种权衡。10%的LLC不是一个专门/保留给I/O(或Intel DDIO)的cache。它完全可用于运行在CPU上的应用程序。这是固定的,不能更改。
cache pollution是指cache中存储了大量不会被CPU上的线程(即运行在CPU上的程序代码)频繁访问的数据。这种情况可能发生在以下场景:
数据流未被消费:
如果有一些数据流被写入cache,但是没有对应的CPU线程(运行在CPU上的软件)去处理这些数据,那么这些数据就会占据cache空间,导致cache中存储了大量无用数据。
数据流入速率快:
在数据流入速率远高于CPU线程处理能力的情况下,即数据被写入cache的速度远远超过CPU线程能够处理的速度,这会导致cache很快被新数据填满,而没有足够的空间来存储那些CPU线程真正需要频繁访问的数据。
通过将Write Allocate操作限制在LLC的10%以内,系统可以确保即使在高数据流入速率的情况下,cache的大部分空间仍然可以用于存储那些对CPU线程来说重要且频繁访问的数据。这样,cache的效率得以保持,因为cache中的数据更有可能是CPU线程需要的,而不是那些不被处理的数据流。这是一种平衡缓存空间使用和防止缓存效率下降的策略。
因此,使用Intel DDIO技术的I/O设备数据传输操作实现了更少的内存访问次数,在理想情况下,甚至不需要访问内存。此外,从CPU cache的角度来看,cache中的数据不会因为I/O数据传输操作而受到干扰。
十一、没有DDIO的Host Write Device Read
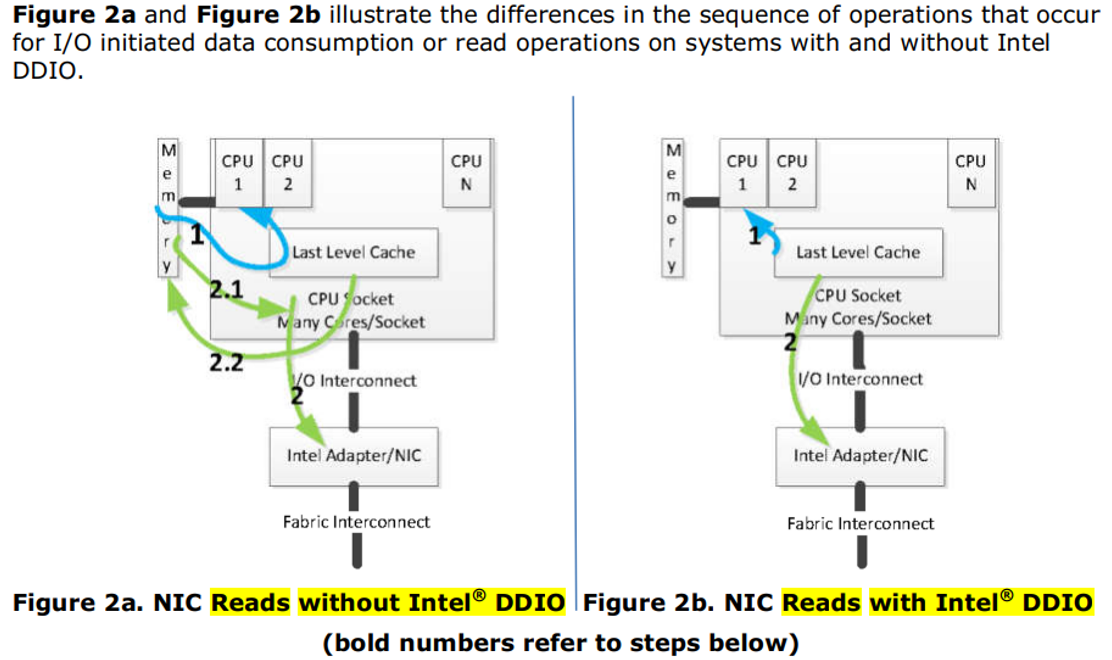

步骤 1: 软件创建数据包
在CPU上运行的软件在maim memory中创建数据包。新的信息(需要网卡发送的data)和为NIC准备控制结构和命令(TX描述符)会被填充到分配的缓冲区(memory地址)中。
这些数据访问操作可能会导致“cache miss”(2.2中解释),cache miss会导致数据被从memory读取到CPU的cache层次结构中。一旦数据被创建,CPU会通知NIC开始传输操作。
步骤 2: NIC开始传输操作
当NIC接收到开始传输操作的通知时,它首先读取控制结构,然后读取数据包数据。
由于数据是最近由CPU上的软件创建的,所以有很大概率这些数据已经存在于CPU的cache层次结构中。
步骤 2.1: NIC触发的读取操作
数据从cache中转发:如果数据在cache中(即cache hit),那么PCIe互连上的NIC的每次读取操作都会导致数据从cache中转发。然而,这种读取操作也会导致数据被从cache中驱逐。也就是说,I/O设备的读取行为会导致数据被从cache中移除(I/O设备的读取操作可能被视为对数据的访问,从而会影响cache中数据的“热度”,可以会导致cache被替换策略(比如LRU)移除或者替换)。
步骤 2.2: 早期系统中的推测性读取
在早期的处理器代中,这个IO读操作还会导致CPU同时向main memory发出一个推测性读请求,同时一致性协议会检查数据是否恰好在CPU的cache层次结构中。
总之,在没有DDIO的系统中,一次单一的读取操作至少需要两次或三次内存访问,这取决于平台的具体实现。
十二、有DDIO的Host Write Device Read
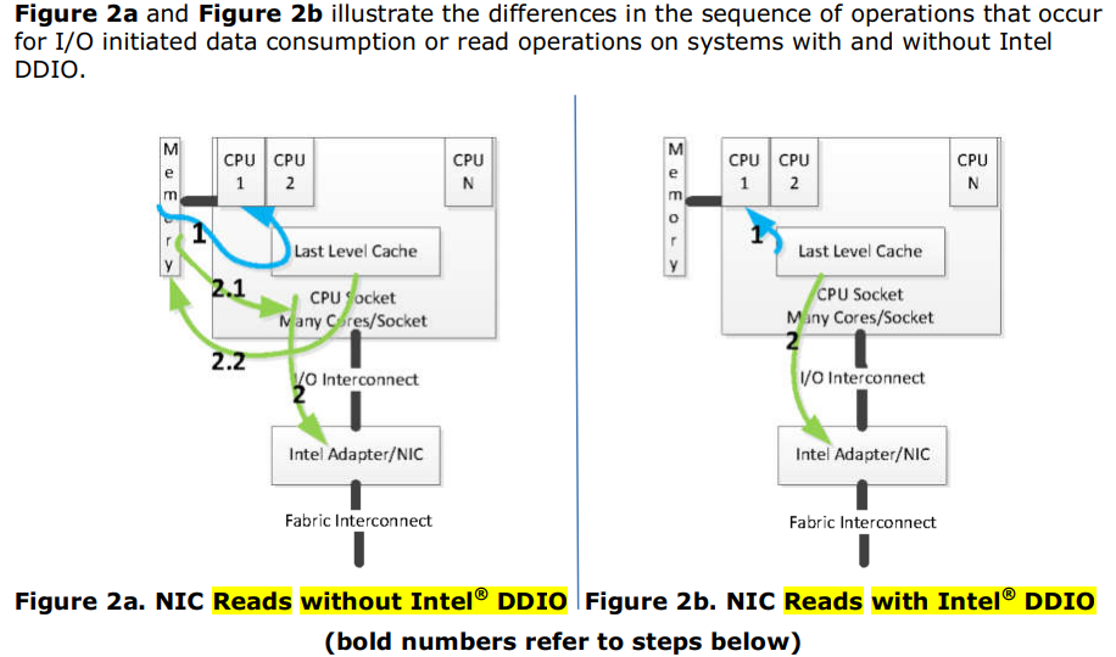

步骤 1: 软件创建数据包
与创建数据包相关的数据访问操作在cache内部得到满足。运行在CPU上的软件不会遇到cache miss,因此,不需要从main memory中获取数据。
步骤 2: NIC开始传输操作
由NIC发起的读取操作由cache中的数据满足,不会导致数据被逐出,即数据仍然保留在cache中,由于这些数据被软件重用,它们会留在cache中。
因此,使用Intel DDIO技术的I/O设备数据消费(IO read)操作需要更少的内存访问次数,在理想情况下,甚至不需要访问内存。另外,从CPU cache的角度来看,cache中的数据不会被I/O数据消费操作所干扰。
IO Read LLC hit:NIC从cache line中读取数据。
IO Read LLC miss:如果IO read在cache中找不到数据(cache miss),它会从main memory中获取数据。默认情况下,如果从main memory中读取数据,不会导致数据被分配到cache层次结构中(和IO write不同)。
IO read LLC miss不在LLC中缓存数据的原因是,IO read可能是一次性操作,数据可能不会被CPU频繁使用,如果像IO Write那样在LLC中allocate反而浪费宝贵的cache资源。
实际情况原比上面介绍的复杂,详细的可以参考:
十三、DDIO和NUMA

Intel DDIO在intel E5默认就enable了。intel DDIO没有硬件依赖并且对软件也是不可见的(这里的软件指的是OS/driver/VMM)。不需要驱动程序更改。不需要OS或VMM更改。不需要应用程序更改。所有来自独立硬件供应商(IHVs)的I/O设备都能从Intel DDIO中受益,包括InfiniBand、FC、RAID和Ethernet。

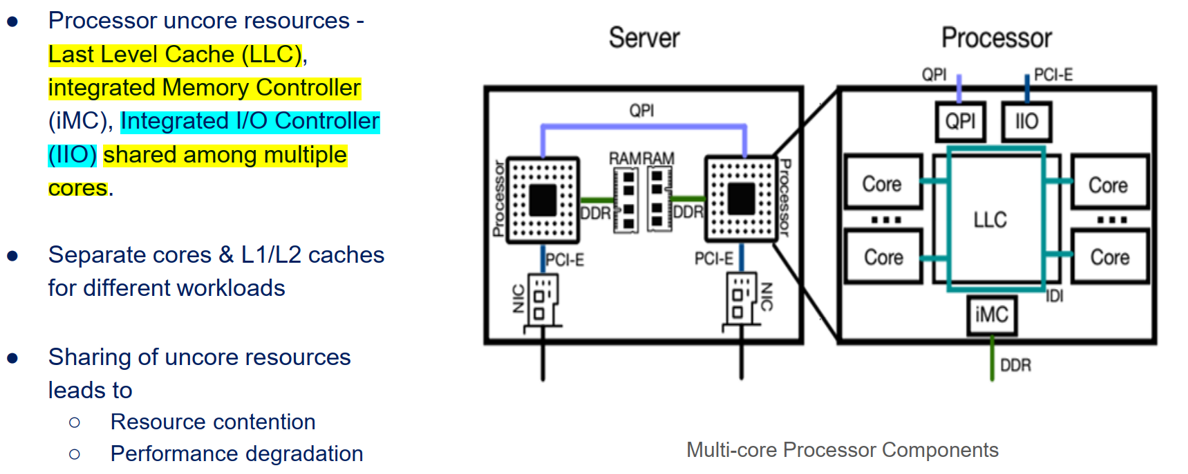
I/O适配器可以直接连接到I/O本地socket(称为“本地”),或者I/O必须穿越QPI链路到达远端的socket。目前,Intel DDIO技术只影响本地socket,因此其性能提升是由于本地socket I/O与远端socket I/O之间的性能差异。
虽然Intel DDIO技术提高了服务器的整体I/O性能,但并非所有线程都能获得这种提升。为了确保Intel DDIO的好处能够被最需要的应用程序所利用,可以通过Intel DDIO将应用程序固定到特定socket上。这种安排被称为socket亲和性(socket affinity)。
十四、DDIO性能提升

在使用基于Intel® Xeon®处理器E5的服务器时,与之前的基于Intel® Xeon®处理器5600的架构相比,可以看到2倍甚至更多的性能提升,因为内存带宽不再是限制因素。更常见的数据中心应用程序并不强调I/O;性能提升通常相对较小,但它们将看到每个双端口NIC功耗节省高达七瓦特。
对延迟敏感的应用程序,如基于UDP的金融交易,将看到由于Intel DDIO,延迟减少了约10-15%。在实验室中,I/O数据率已经被推向极限,以找到Intel Xeon E5平台的绝对极限,并实现了约250 Gbps的I/O数据率,是上一代Intel Xeon处理器5600服务器所能达到的最大值的三倍。
十五、DDIO是否对所有的数据模型都可以提升性能
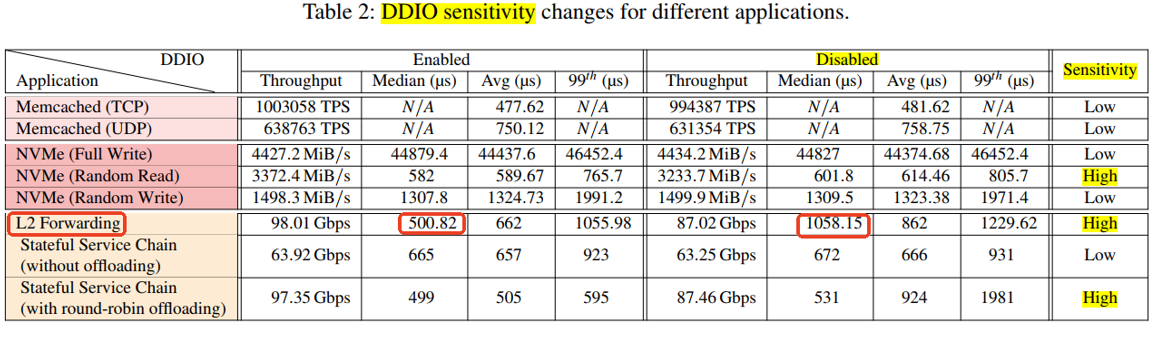

DDIO对某些I/O密集型应用程序(如L2 forwarding)的性能有显著影响,而对其他应用程序(如Memcached和NVMe)的影响较小
详细参考:https://www.usenix.org/system/files/atc20-farshin.pdf
十六、skylake CPU的intel DDIO开启和关闭

1、Disable DDIO
Disable IIO的方法有两种:全局设置和每个root port的设置。网页GitHub - aliireza/ddio-bench: Reexamining Direct Cache Access to Optimize I/O Intensive Applications for Multi-hundred-gigabit Networks提供了对应的方法。
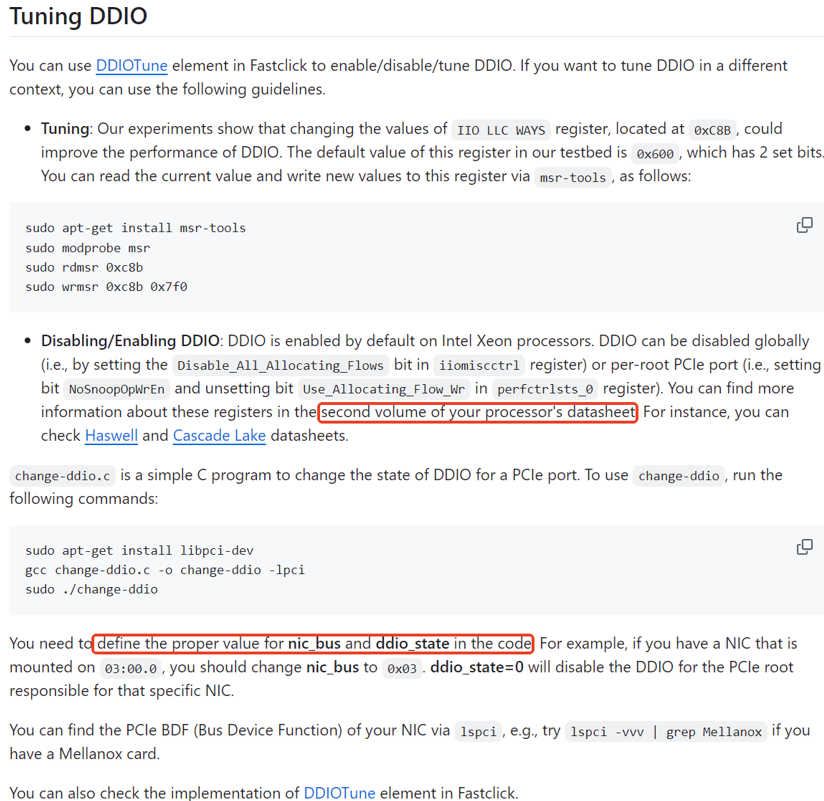
全局设置:IIOMISCCTRL: IIO MISC Control(0x1C0)的bit24: Disable_all_allocating_flows 置1(默认值是0)。
Disable_all_allocating_flows 置1是,IIO将不再发出任何新的inbound IDI命令(IDI命令是用来在LLC中allocate的)。相反,所有的写入操作将使用non-allocating commands,这些命令包括PCIWiL(PCI Write Line)、PCIWiLF(PCI Write Line with Fence)、PCINSWr(PCI Non-snooping Write)、PCINSWrF(PCI Non-snooping Write with Fence)。
这样的设计主要是为了在某些特定情况下,如PsMI中,需要一种模式来避免在LLC中分配空间。
软件应该只有在IDI上没有active的请求时才能设置这个bit。因此,要么在设置或者清零这个bit之前采用了lock/quiesce流程,要么在系统启用DMA之前就设置它。
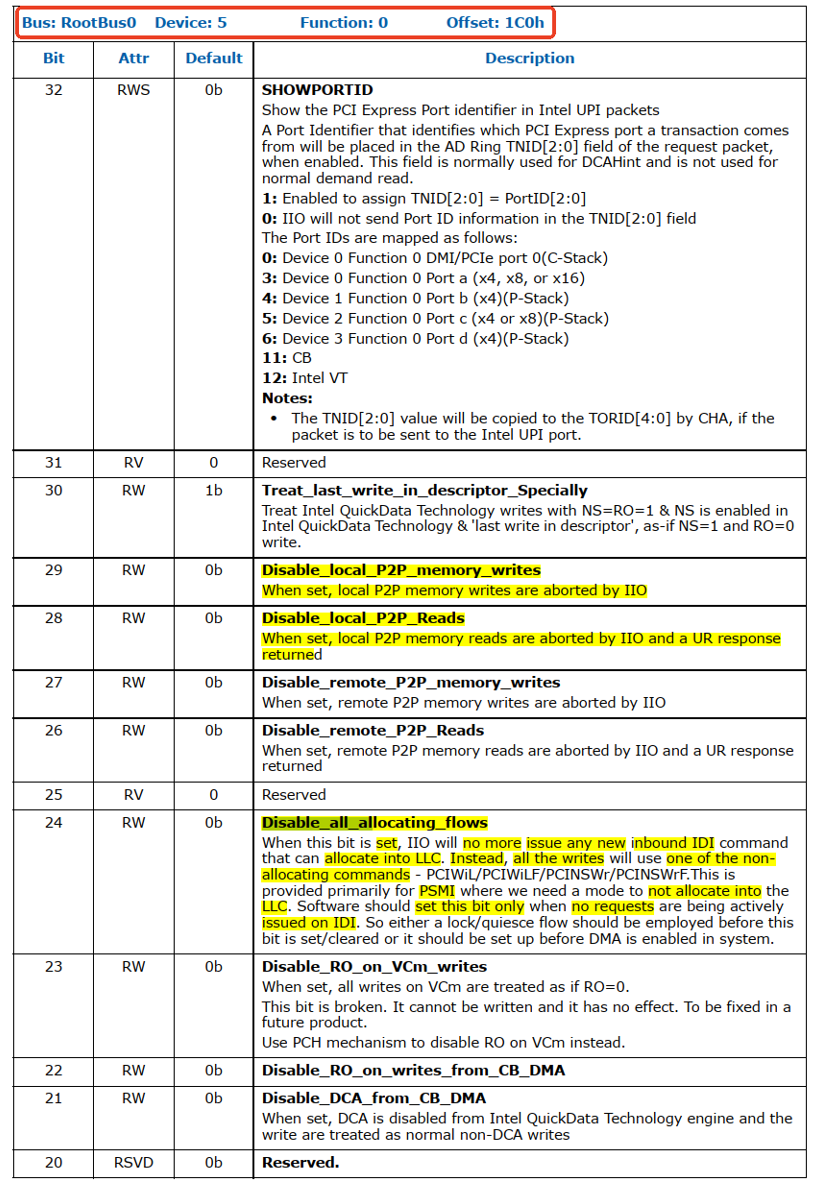
每个root port的设置:PERFCTRLSTS_0: Performance Control and Status(0x180)的
(1)bit7:Use_Allocating_Flow_Wr设置为0(默认值是1):
如果bit7为0,则所有的snoop write将会使用Non-Allocte flow。
且(2)bit3:NoSnoopOpWrEn设置为1(默认值是0):
当NS=1并且(TPH=0 或者TPHDIS=1(PERFCTRLSTS_1: Performance Control and Status reg bit9))时。
如果bit3为1,对于memory的inbound write请求,如果满足NS=1并且(TPH=0 或者TPHDIS=1)将会当做Non-coherent(No snoop) write:使用Non-Allocte NS flow。
如果TPH=1且TPH_DIS=0,那么NS bit被ignore,且NoSnoopOpWrEn没作用。
TPH and ForceNoSnoopWrEn(bit5)比bit3有更高的优先级。
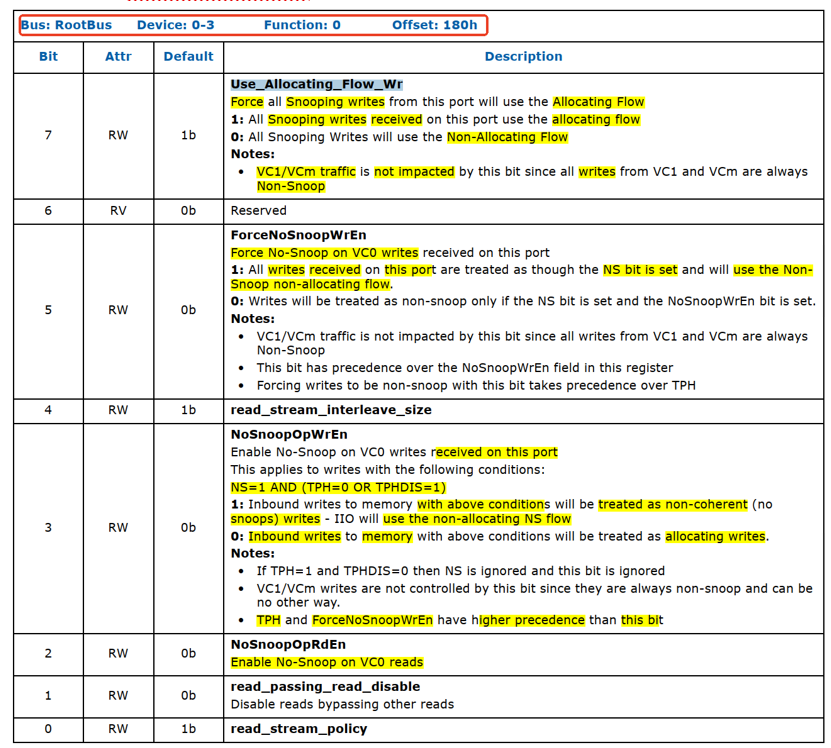
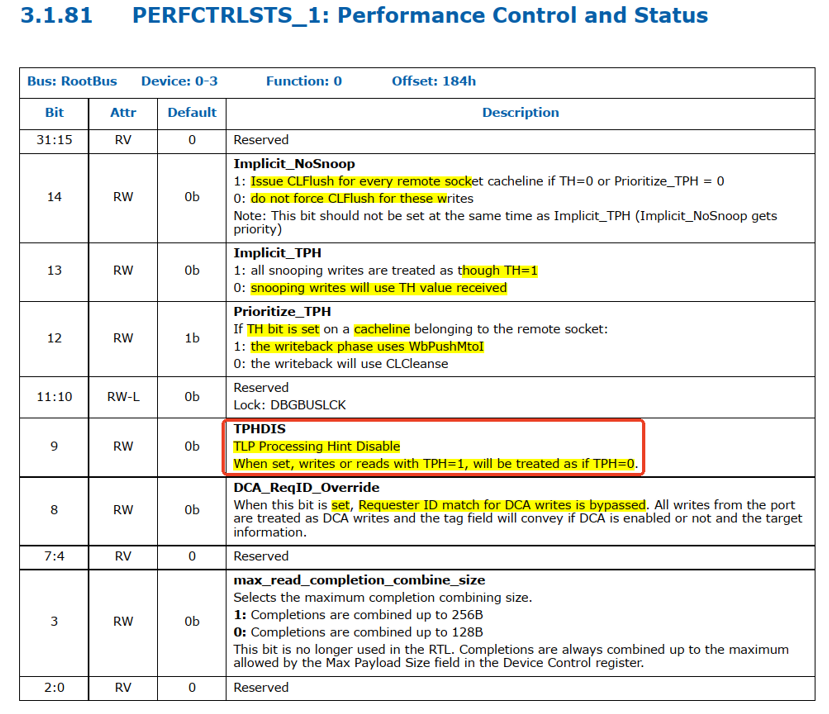
2、默认情况DDIO enable
默认情况下,DDIO是enable的。
(1)PERFCTRLSTS_1的bit9 TPHDIS默认值是0,也就是TLP Processing Hit没有被disable,CPU收到带有TPH=1的TLP,不会当作TPH=0,而是根据TPH的情况正常处理。
(2)PERFCTRLSTS_0的bit7 Use_Allocating_Flow_Wr 默认值是1,也就是该root port收到的所有的Snoop write都要用allocate flow。
注意:VC1/VCm traffic不受到这个bit影响,因为VC1/VCmde的写都是non-snoop的。
(3)PERFCTRLSTS_0的bit5 ForceNoSnoopWrEn默认值是0,也就是说只有当NS bit=1 且 NoSnoopWrEn=1(默认值为0)时,该root port收到所有write将会被当成Non-snoop(从 “This bit has precedence over the NoSnoopWrEn field in this register” 推测NoSnoopWrEn是指的PERFCTRLSTS_0的bit3 NoSnoopOpWrEn)。
注意1:VC1/VCm traffic不受到这个bit影响,因为VC1/VCmde的写都是non-snoop的。
注意2:Bit5比该寄存器的 bit3 NoSnoopWrEn 字段具有更高的优先级。
注意1:Bit5为1比TPH有更高优先级。
(4)PERFCTRLSTS_0的bit3 NoSnoopOpWrEn默认值是0,也就是说该root port收到NS=1 且(TPH=0 或者TPHDIS=1)的memory write请求会被当成allocate write。
注意1:如果TPH=1且TPHDIS=0,那么NS和该bit3都要被ignore。
注意2:VC1/VCm traffic不受到这个bit影响,因为VC1/VCmde的写都是non-snoop的。
注意3:TPH和ForceNoSnoopWrEn(bit5)比bit3有更高优先级
(5)PERFCTRLSTS_0的bit2 NoSnoopOpRdEn默认值是0,也就说root port VC0收到的read请求不会被当作Non-Snoop的。
十七、DDIO的一些讨论
1、Reexamining Direct Cache Access to Optimize I/O Intensive Applications for Multi-hundred-gigabit Networks
https://www.usenix.org/system/files/atc20-farshin.pdf
https://www.youtube.com/watch?v=m_yx_Sbao2I&t=48s
2、Introduction to Intel® Data Direct I/O Technology (Intel® DDIO) Analysis with Performance Monitoring
针对DDIO的IO Write和IO read原比九、十二章节讨论的复杂,详细见:
3、ISCA'21 - Session 2B - Don't Forget the I/O When Allocating Your LLC
https://yifanyuan3.github.io/files/iat-isca21.pdf
https://www.youtube.com/watch?v=Kmby1OIMNIE
4、A case for effective utilization of Direct Cache Access for big data workloads
A case for effective utilization of Direct Cache Access for big data workloads


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











