






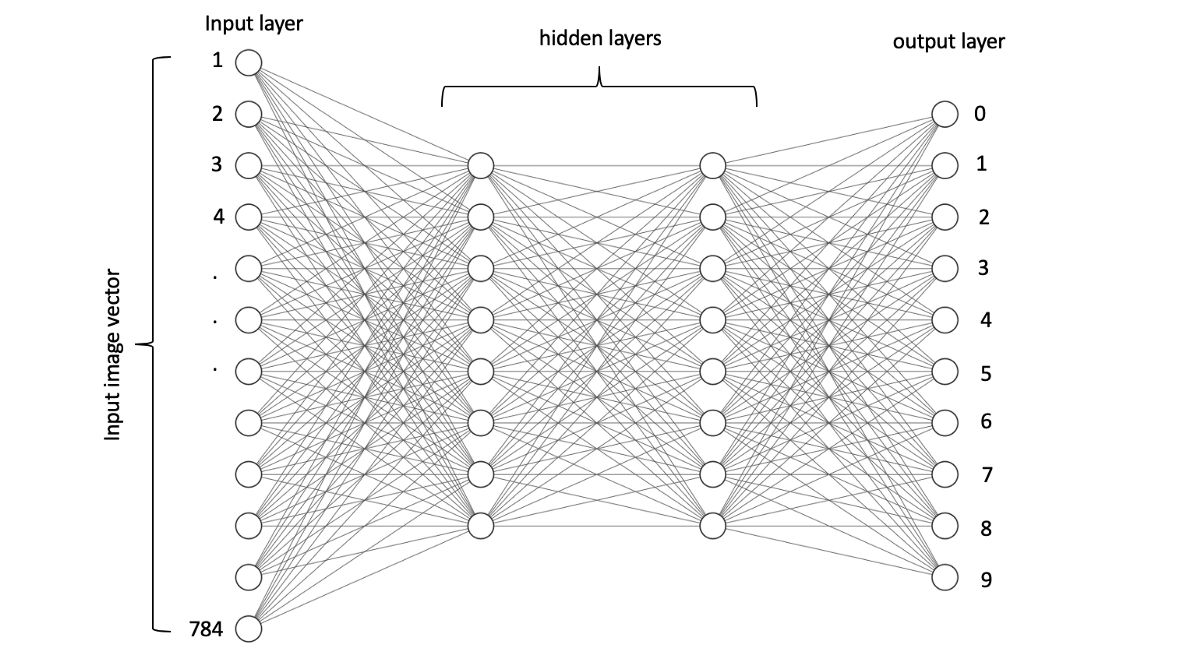
I used Alexlenail website to create this image
上一张图片是用于深度神经网络的简单架构。 这篇文章的目的是了解深度学习细节并建立自己的网络,而不是将现有模型用作黑匣子!
准备输入数据
在本文中,我们将介绍一个简单的神经网络,该网络可以学习识别手写数字(MNIST数据集)。 当前,有各种类型的神经网络,但是为了简单起见,我们将从香草形式(也称为"多层感知器")开始。
请注意,先前图中的圆圈称为神经元。 每个神经元包含一个介于0和1之间的数字,称为"激活"。 另外,请注意,这些神经元之间的线称为权重。 每个权重是一个随机生成的数字,其值介于-1和1之间。
MNIST数据集中的每个图像仅由黑白形成,其尺寸为(28 x 28=784像素)。 如果您仍然想知道为什么神经元的激活范围介于0和1之间,那是因为它保留了图像的灰度,其中0完全是黑色,而1却是完全白色。 最后,要在神经网络中输入图像,我们需要通过获取每一行像素并将其附加到上一个图像,将其转换为像素向量,请检查以下示例:

图层说明
如上所述,网络的输入将是一幅图像,该图像将转换为像素向量(精确地为784),这是我们神经网络的第一层。
输出层神经元的数量应与我们试图预测的类的数量相关联。 在我们的示例中,类的数量为10(0、1、2,...,9)。 因此,最后一层(输出层)应包含10个神经元。
隐藏的层是介于两者之间的层。 现在,让我们只说我们随机选择了隐藏层的数量和神经元的数量。
目标是什么?
我们想要建立一个能够预测输入图像数字的模型(图像分类)。 但是,很难一步一步地展示整个网络的示例。 因此,我们将从一个简单的神经网络开始,该神经网络由三个输入节点,一个具有单个神经元的隐藏层和一个输出组成。 我们的网络将如下所示
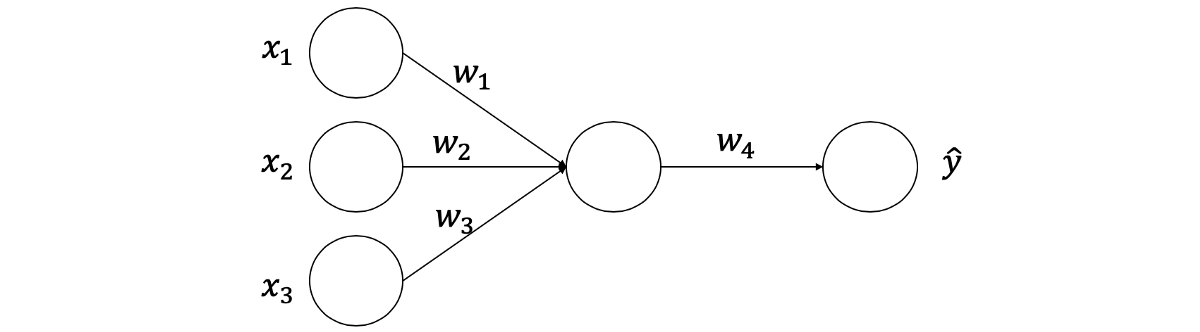
正向传播
正向传播是从输入开始,经过神经网络及其计算,最后进行单个预测(以y ^表示并称为y-hat)的过程。 让我们从下面的向量[0.6,0.4,0.2]开始,实际输出(y)为1。

所有这些数字从何而来? 好了,输入节点已经给定了,Z是将输入激活与权重相乘并将其相加的结果,y ^是Z与权重相乘的结果。 最后,还给出了y,它是所需的输出。 通常,要计算任何输出,我们将激活与权重相乘,然后将它们相加。 这是第一层的公式。
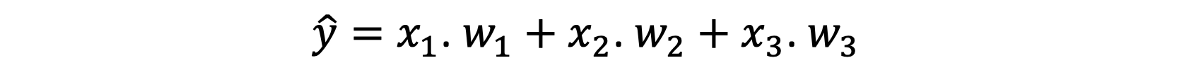
显然,我们在所有输入和权重上重复相同的乘法。 因此,我们只计算总和,因为我们可能有3个以上的输入。
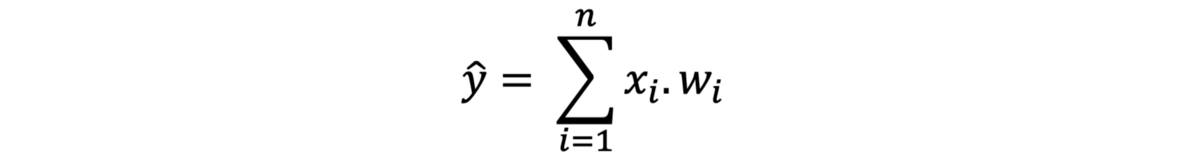
偏见
每个神经元都会在某个时间发射和发光。 当神经元发射时,这意味着该神经元检测到图像中的特定特征。 例如,每当数字7的图像进入网络时,几乎相同的神经元就会激活并激发(这意味着它们触发了类似的事件,类似的角度等)。 但是,当激活大于0时,您不希望每个神经元都触发(否则,所有积极的激活都会继续触发)。 您希望它们在某个阈值(例如10)之后启动,这称为偏差(b)。 我们将b添加到求和中以控制神经元何时触发。
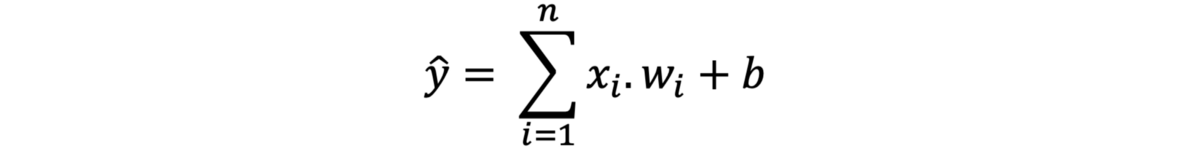
激活功能
到目前为止,我们的方程将产生良好的结果。 但是,结果可能小于0或大于1。如前所述,每次激活都应在0到1的范围内,因为那是每个图像的灰度。 因此,我们需要一个函数(f)来将y ^的结果压缩在0和1之间。此函数称为激活函数,尤其是Sigmoid。 在y ^上调用Sigmoid会得到以下结果
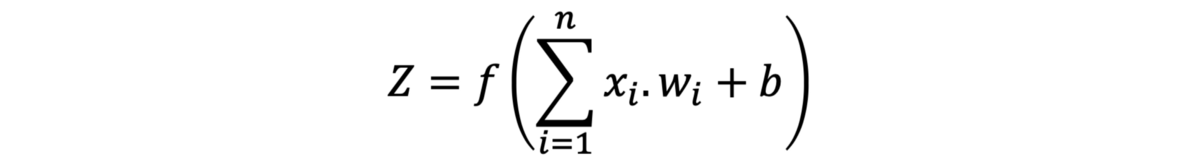
或者您可以将其编写如下
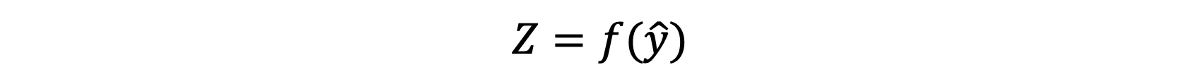
注意我命名了左手尺寸(Z),这是应用激活函数后隐藏层输出的约定名称。 另外,请注意,我称f不是Sigmoid,因为我们可以应用许多不同的激活函数。 以下是常用激活功能的列表:
· Sigmoid:是一种在0到1之间传输输出的函数,它在概率中使用很多,因为这是概率的范围。
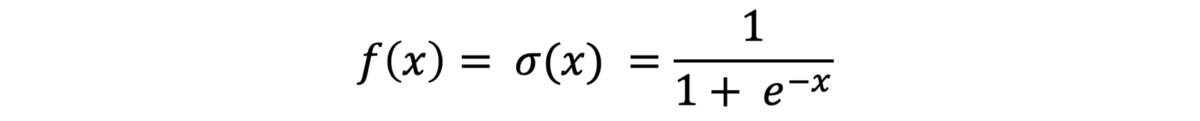

Image by WolframMathWorld
· Tanh或双曲正切:在某种程度上类似于Sigmoid,范围为-1至1。
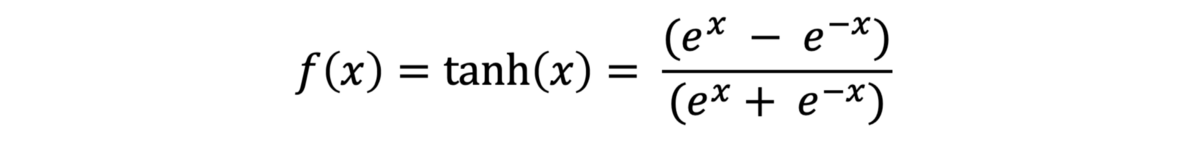
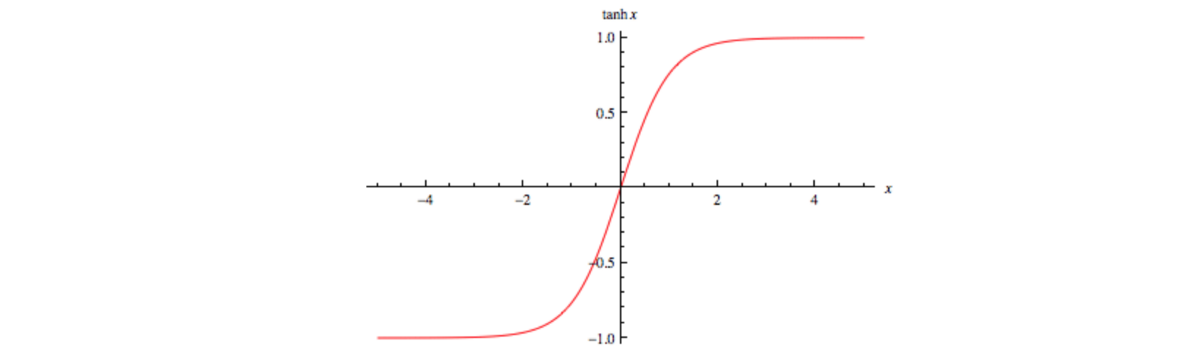
Image by WolframMathWorld
· 整流线性单位(RELU):RELU是最常用的激活功能。 其范围是0到无穷大。 如果输入为负,则RELU返回0,否则,返回实际输入:max(0,x)
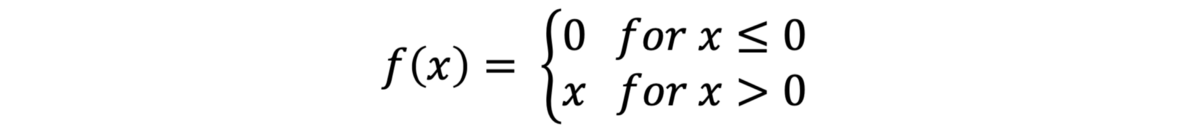
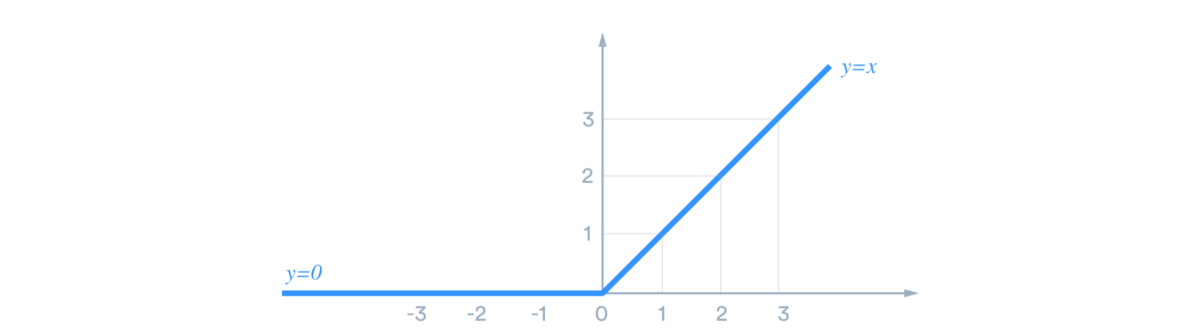
Image by Danqing Liu — Medium: RELU
· Softmax:是一个独特的激活函数,它采用k个数的向量并将其归一化为k个概率。 换句话说,它没有选择单个输出类别,而是列出了每个类别的概率。
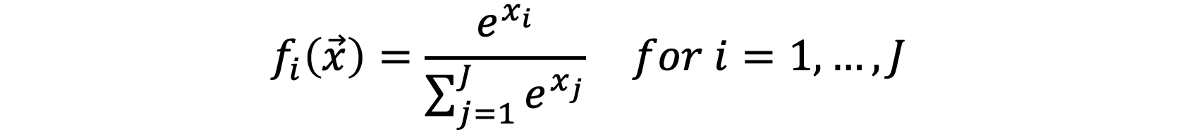
还有许多其他激活功能,例如Leaky RELU,Parametric RELU,SQNL,ArcTan等。
计算损失
有什么损失? 简而言之,损失就是模型离预测正确答案有多远。 如前所述,输出为1,而预测输出为0.3,因此在我们的情况下损失为0.7。 如果模型预测是理想的,则损失为0。因此可以使用以下公式计算损失(L代表损失)
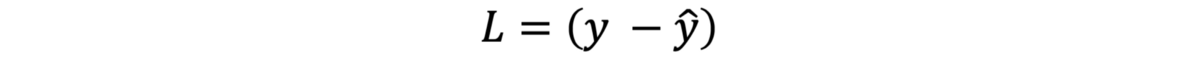
是吗?基本上,是的,但是很少有什么事情可以改善损失,从而在将来对我们更有利:
· 绝对值误差:损失是模型预测与输出的距离量。 考虑有两个错误。 第一个错误是100,第二个错误是-100。 将这些误差相加并取平均值即可得出0,这意味着您的预测是100%正确的,而不是正确的。 因此,我们只对技术教程正误差感兴趣。
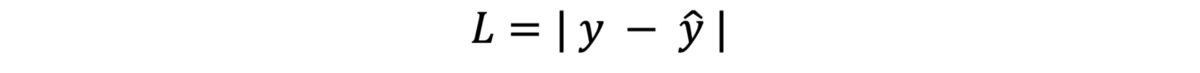
· 平方值误差:考虑有两个错误(一个小错误和一个大错误)。 您将更关注哪个错误? 当然,更大的错误! 因为它对结果的影响更大。 因此,计算损耗的平方值有助于我们消除符号,并使大误差变大而小误差变小。 考虑具有0.01和100的误差。通过对这些误差求平方,我们得到0.0001和10000。对这些误差进行优先级确定对于造成不良预测的原因非常重要。
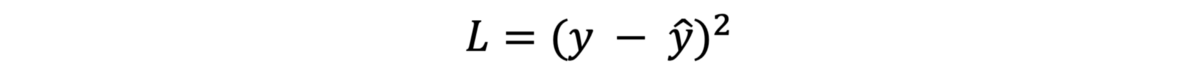
· 总和:在前面的示例中,我们计算了预测和输出之间的损失,但是如果我们有多个输出神经元怎么办? 因此,我们计算了神经网络中所有损耗值之间的总和。 (D表示包含许多示例的数据集)。
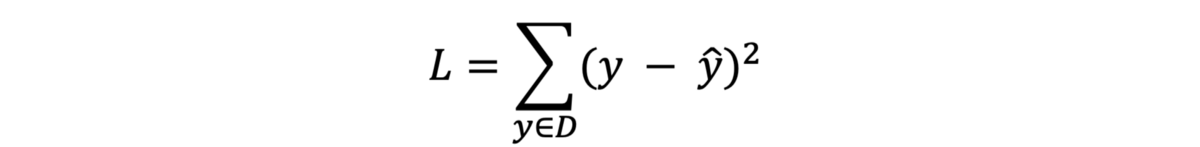
· 平均值:数据集中示例的平均值。 在我们的例子中,我们有一个例子。 但是现在,我们需要将其除以D中的示例数(N)。
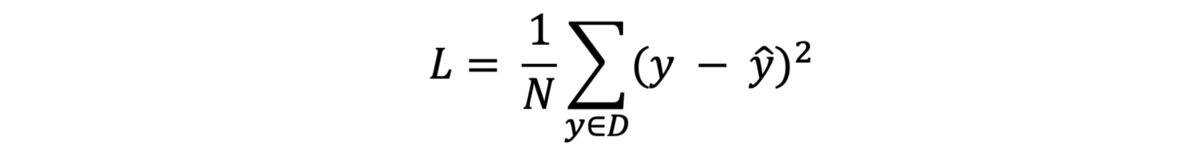
此损失函数称为均方误差(MSE),它是最常用的损失函数之一。 还有许多其他损失函数,例如交叉熵,铰链,MAE等。但是您是否想知道成本函数是什么? 损失函数和成本函数有什么区别? 好吧,不同之处在于损失函数用于单个训练示例,而成本函数是整个训练数据集的平均损失。
恭喜你! 我们完成了正向传播。 但是,我们刚刚做出的预测可能不是很准确(考虑输出1,但是模型预测为0.7)。 我们如何做出更好的预测? 好吧,我们不能更改输入值,但是可以更改权重!! 中提琴 现在您知道了深度学习的秘密。
反向传播
我们无法更改输入。 但是,我们可以增加权重,然后通过将其乘以输入将获得更大的预测输出,例如0.8。 继续重复此过程(调整权重),将获得更好的结果。 以相反的方向改变重量被称为反向传播! 但是,如何才能做到这一点呢? 好吧,这可以使用优化算法来完成。 有不同的优化手段,例如渐变下降,随机渐变下降,Adam Optimizer等。
梯度下降
梯度下降是旨在通过调整权重来减少损失的优化算法之一。 当然,手动更改权重是不可能的(我们在单个神经网络中拥有数十个和数百个权重)。 那么我们如何使这一过程自动化? 以及如何告诉功能要调整的重量以及何时停止?
让我们开始调整权重,检查这如何影响损失并绘制所有结果(检查波纹管图)。 如您所见,在特定点(红线)是最小损失。 在红线的左边,我们必须增加权重以减少损失,而在红线的右边,我们显然需要减少权重以减少损失。 主要问题仍然存在:如何知道给定点是在红线的左侧还是右侧(以便知道是否应该增加或减少权重)? 为了接近最小损失,我们应该增加或减少多少重量? 一旦我们回答了这个问题,便可以减少损耗并获得更好的精度。
请注意,在简单的2D尺寸中,很容易快速达到最小点。 但是,大多数深度学习模型都涉及高维度。
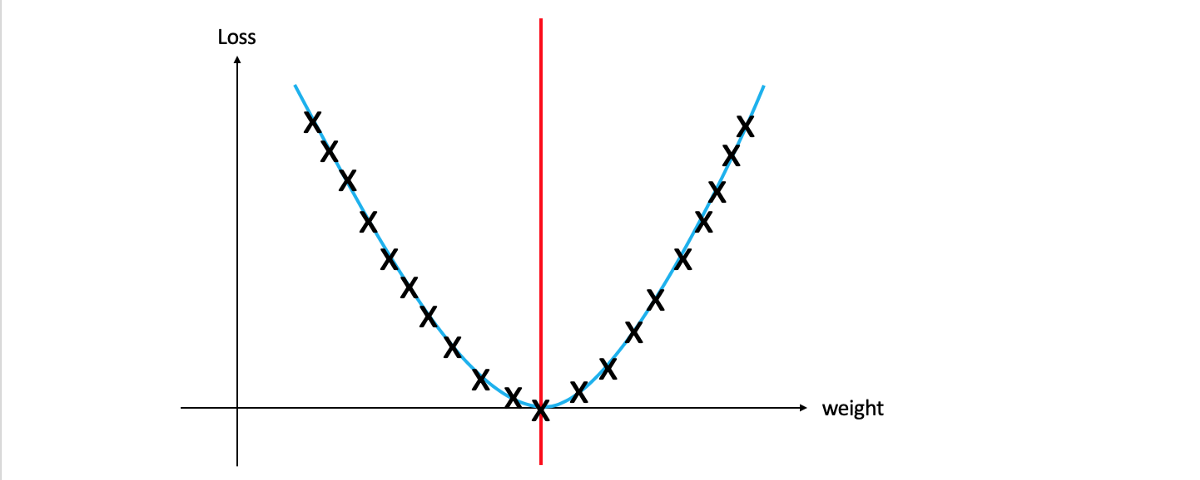
幸运的是,数学中有一种方法可以回答这些问题,导数(您在高中时忽略了的事情:))。 使用导数,我们可以使用损失相对于权重的导数来计算图上切线的瞬时变化率。
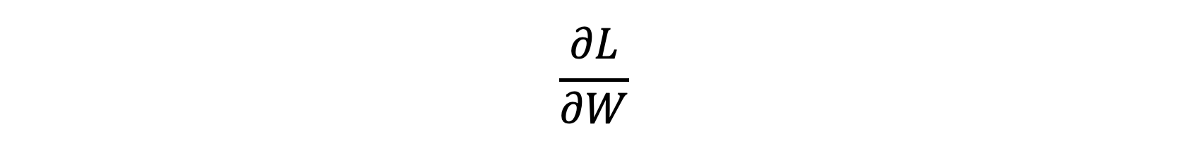
如果您不熟悉导数,并且上一句话听起来像胡言乱语,则可以将其视为一种测量在特定点触摸图形的线的斜率和方向的方法。 根据给定点的斜率方向,我们可以知道该点是否存在于红线的左侧或右侧。
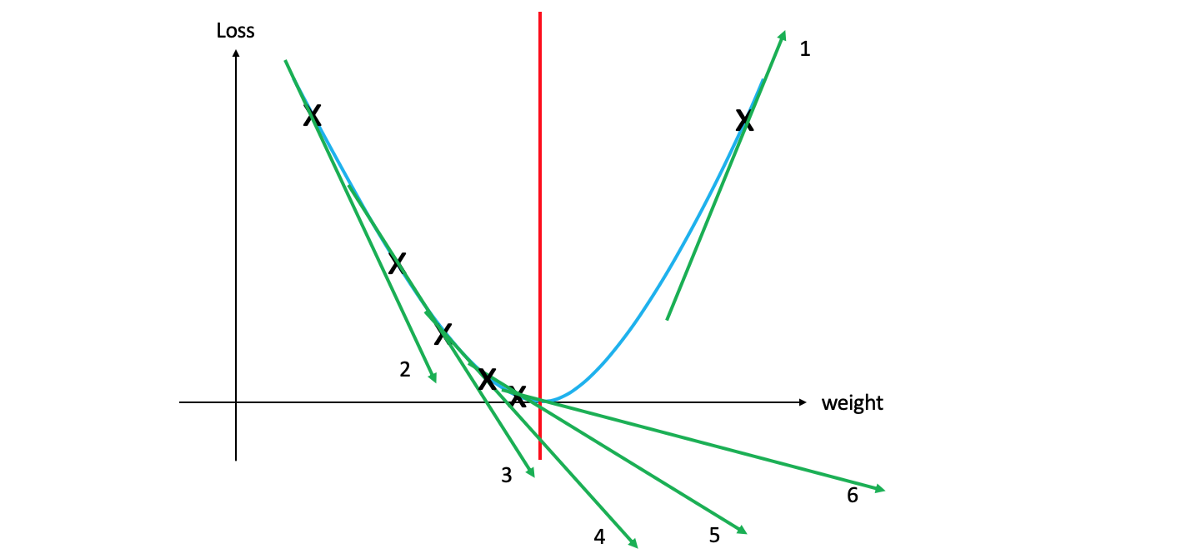
在上图中,您可以看到1号切线的右侧朝上,这意味着它是正斜率。 其余线条朝下,则为负斜率。 另外,请注意,斜率2的斜率大于斜率6的斜率。这就是为什么为什么要知道需要多少重量来更新权重。 梯度越大,该点距最小点越远。
学习率
将点定位到红线的左侧或右侧后,我们需要增加/减小权重以减少损失。 但是,让我们说说对于存在于红线左侧的给定点,我们应该增加多少权重? 请注意,如果您显着增加重量,则该点可能会将最小的损失传递给另一侧。 然后,您必须减轻重量,依此类推。 随机调整重量是没有效率的。 相反,我们添加了一个称为"学习率"的变量,用"η"表示,以控制权重的调整方式。 通常,您从一个小的学习率开始,以避免超过最小的损失。 为什么叫学习率? 嗯,减少损失并做出更好的预测的过程基本上是在模型学习时进行的。 那时,学习率决定着模型学习的速度。
调整权重
最后,我们将斜率乘以学习率,然后从旧的权重中减去该量以获得新的权重。 通过看下面的波纹管方程,您会更好地理解它
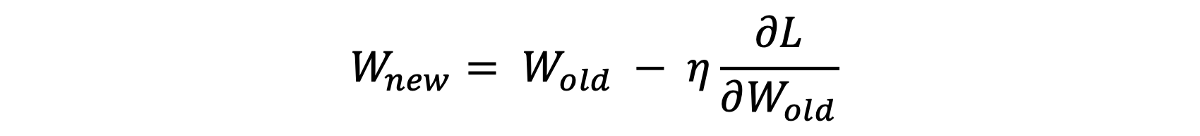
随机梯度下降
虽然梯度下降使用整个数据集来计算梯度,但是SGD在每次迭代时都使用训练数据集的单个示例。 SGD通常比批处理或标准梯度下降更快地达到收敛。 批梯度下降每次迭代使用一批训练示例。
过度拟合
当神经网络很深时,它具有太多的权重和偏差。 发生这种情况时,神经网络往往会过度拟合其训练数据。 换句话说,该模型对于特定的分类任务将如此精确,而无需泛化。 该模型在训练数据上得分很高,而在测试数据上得分很低。 辍学是解决方案之一。
退出
一种简单而有效的避免过度拟合的方法是使用drop out。 对于每一层,都有一个drop out率,这意味着停用与此比例相关的许多神经元。 这些神经元将被随机选择,并在特定的迭代过程中被关闭。 下次迭代时,将停用另一组随机选择的神经元,依此类推。 这有助于概括模型,而不是记住特定功能。
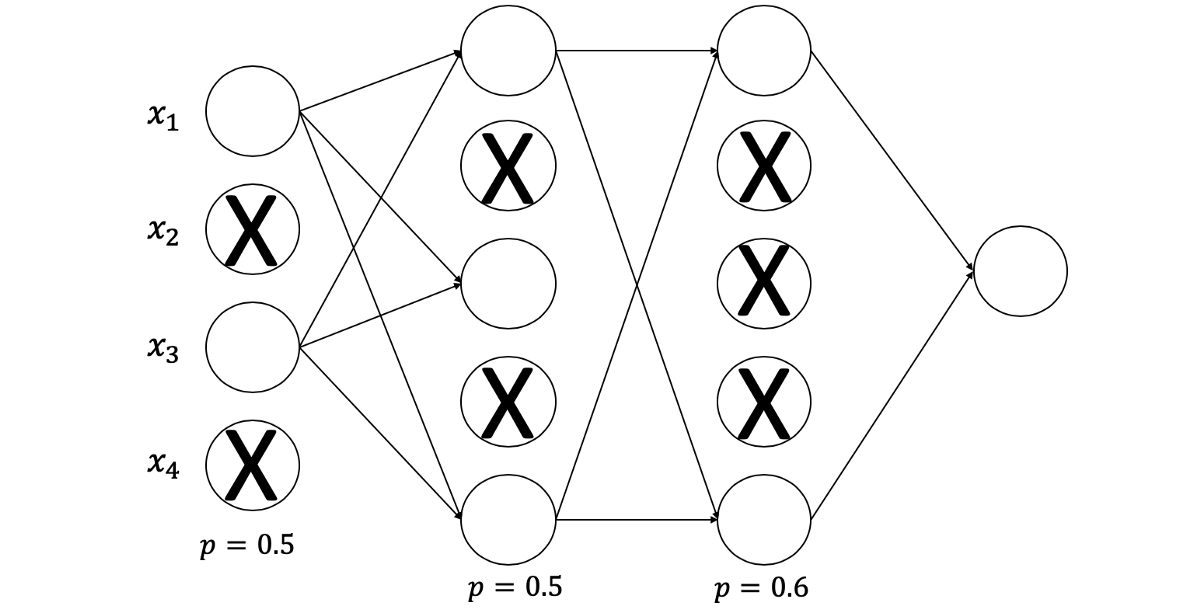
希望这篇文章对您有所帮助。 请让我知道,如果你有任何问题!















 8680
8680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









