







论文:A NEURAL PARAMETRIC SINGING SYNTHESIZER
完整论文:A Neural Parametric Singing Synthesizer Modeling Timbre and Expression from Natural Songs
之前研究过一段时间的wavenet语音合成。第一版wavenet的一个最大的问题是合成非常耗时,但是就有尝试过各种方案,包括了一帧一帧合成的方案。奈何打开方式不对,始终没搞出来。后来看到了这篇用wavenet合成歌声的论文,竟然还是一帧一帧合成的。由于没有开源,而且现在也没事时间去做语音合成的内容,先把论文的思想记录一下。

先看看论文方法的流程图。从图上我们很明显可以看出,模型的输入是语谱图,而语谱图是语音分帧后经过短时傅里叶变换再求得的。在原始的wavenet中,模型的输入是采样点量化到0-255,然后经过一个embeding层,使得一个点变成一个向量。所以说语谱图作为模型的输入跟原始wavenet的输入是很契合的。这里我们先不关心文本特征的输入。模型的输出是一个概率分布,要获取与语音相关的特征可以从这个概率分布中采样而来。
整个模型大致与原始的wavenet一样,只是最后的输出变成了概率分布。还有一点是,论文的整个方案是要预测用于world声码其合成的bap,mgc以及voiced/unvoiced。这些的训练是分开的,也就是每个都有对应的wavenet模型,但是在预测的时候是有一定的依赖关系。这点很重要,具体可以看论文。
ok,现在来看看模型的输出。假设模型预测的是bap,那么模型最终要预测的是4个点。同时假设用的是4个混合高斯函数(每个高斯函数由4个参数描述)来模拟每个点的分布,那么最终的网络输出是4×4×4=64个节点。
论文用的概率密度叫带约束的高斯混合模型:
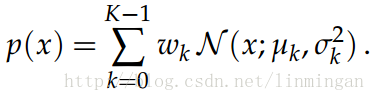
其中, μk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









