







摘要
- 1.受DEX启发: 将年龄预测回归问题变为多分类问题
- 2.由粗到细策略,每个阶段执行部分年龄分类,任务量少(Stagewise):每个阶段预测类别少,产生更小参数和更紧凑的模型
- 3.解决量化年龄问题,引入动态范围,让每个bin可以平移和缩放(Soft ):允许bin根据输入来进行平移和缩放
- 4.模型大小可以达到0.32M
损失函数
在训练时,最小化平均误差函数,这里,年龄预测
逐步回归
在DEX网络中,将年龄区间分为互不重叠的子区间bin,所以每一个bin的宽度
为
,我们假设第i段bin所代表的年龄为
.
, DEX将网络作为s个类别年龄分类问题。给定输入图像x,输出分布向量
来表示x属于每个年龄组的可能性。年龄的期望值为
为了进一步减少参数量,我们加入coarse-to-fine strategy,假设我们有K个阶段,第k个阶段有个bins。对于每个阶段我们训练网络
输出分布向量
,预测出的年龄阶段为
其中每一个bin的宽度,这里i是bin的索引.
动态范围
将年龄区间统一划分为非重叠区间在处理年龄组不平衡和年龄连续性方面不够灵活,粗粒度问题更严重。引入动态范围:允许每个bin可以根据输入图像进行移位(shifted,调整bin的索引i)和缩放(scaled,调整).
- 为了调整
,我们引入
,
,
.
- 为了实现偏移,对每个bins添加偏移量
,
,由此得到索引改变
模型结构

上图所示采用2-stream 结构: 不同的激活函数和池化方式可以提取不同特征,提高融合特征的丰富度。在每个阶段,来自两个流的特征被送入融合块。融合块负责产生分段输出,
- 对于
,两个获得的特征图通过逐元素乘法
融合,经过Tanh激活函数,将输出限制为[-1,1]
都是向量,经过全连接层,Relu保证分布概率
为正值,
输出限制为[-1,1]
在给定网络分段输出参数,后
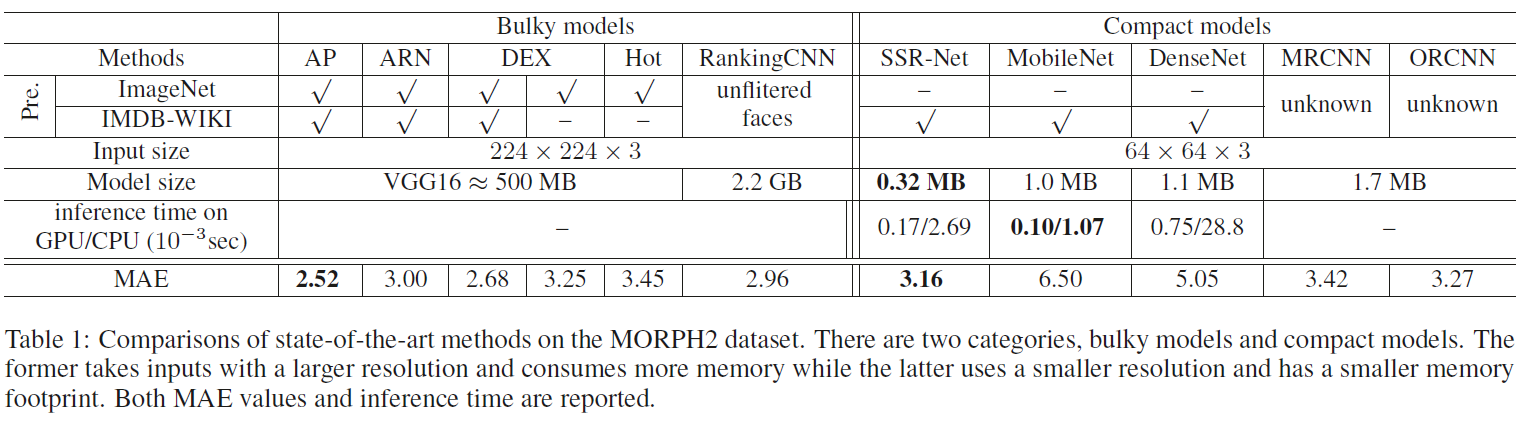
结果分析
紧凑模型中表现最好。















 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









