







 本文解释了为何Q learning、DQN和DDPG等off policy强化学习算法在更新时不使用importance sampling。通过直观理解、数学分析和图形展示,阐述这些算法中target policy的选择过程,指出由于直接采用greedy策略,因此不需要importance sampling进行采样误差校正。
本文解释了为何Q learning、DQN和DDPG等off policy强化学习算法在更新时不使用importance sampling。通过直观理解、数学分析和图形展示,阐述这些算法中target policy的选择过程,指出由于直接采用greedy策略,因此不需要importance sampling进行采样误差校正。
最近有同学问我为什么Qlearning,DQN,DDPG等off policy的算法不需要importance sampling。
我看了一下网上的资料很少,仅有的资料虽然解释得还算清晰,但是基本上也是只有懂的人才看得懂,不懂的人还是得消化很久。从ADEPT(Analogy / Diagram / Example / Plain / Technical Definition)的学习规律出发,本人尝试一下给出直观理解、数学方法、图形表达、简单例子和文字解释。
首先为什么需要off policy,off policy是什么,大家可以看一下我之前的回答,这里就直入正题。
强化学习1:彻底分清On-Policy&Off-Policy
强化学习2:Q-learning与Saras?流程图逐步解释
我们先看一下Q learning的update公式:
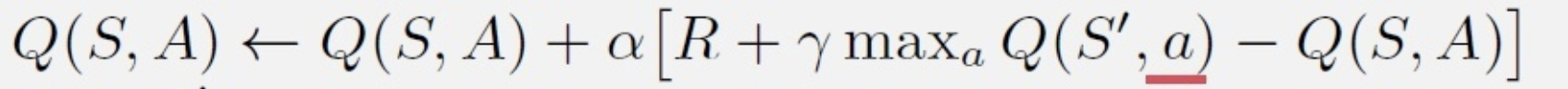 很明显可以知道,这里之所以是off policy,我们选得next action不是通过behavior policy来选择的,而是直接从target policy 选择的(即greedy/argmax)。那么这里需要imporce sampling的ratio来矫正差异吗
很明显可以知道,这里之所以是off policy,我们选得next action不是通过behavior policy来选择的,而是直接从target policy 选择的(即greedy/argmax)。那么这里需要imporce sampling的ratio来矫正差异吗
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









