







本讲内容:
Seq2seq model,以Transformer模型为例(Encoder-Decoder架构)
应用: 语音辨识、语音翻译、语音合成、 聊天机器人、NLP、文法剖析、multi-label classification、object detection、摘要
2021 - Transformer (上)_哔哩哔哩_bilibili
(作业五)
变形金刚的英文就是Transformer,那Transformer也跟我们之后会,提到的BERT有非常强烈的关係,

Sequence-to-sequence (Seq2seq)
Transformer就是一个,Sequence-to-sequence的model,(缩写:Seq2seq),那Sequence-to-sequence的model,又是什麼呢
我们之前在讲input是一个sequence的,case的时候,我们说input是一个sequence,那output有几种可能
- 一种是input跟output的长度一样,这个是在作业二的时候做的
- 有一个case是output只,output一个东西,这个是在作业四的时候做的
- 那接来作业五的case是,我们不知道应该要output多长,由机器自己决定output的长度,即Seq2seq

-
举例来说,Seq2seq一个很好的应用就是 语音辨识
在做语音辨识的时候,输入是声音讯号,声音讯号其实就是一串的vector,输出是语音辨识的结果,也就是输出的这段 声音讯号,所对应的文字
输入跟输出的长度,当然是有一些关係,但是却没有绝对的关係,输入的声音讯号,他的长度是T,我们并没有办法知道说,根据大T输出的这个长度N一定是多少。
输出的长度由机器自己决定,由机器自己去听这段声音讯号的内容,自己决定他应该要输出几个文字,他输出的语音辨识结果,输出的句子裡面应该包含几个字,由机器自己来决定,这个是语音辨识
-
还有很多其他的例子,比如说作业五、我们会做机器翻译
让机器读一个语言的句子,输出另外一个语言的句子,那在做机器翻译的时候,输入的文字的长度是N,输出的句子的长度是N',那N跟N'之间的关係,也要由机器自己来决定
输入机器学习这个句子,输出是machine learning,输入是有四个字,输出有两个英文的词汇,但是并不是所有中文跟英文的关係,都是输出就是输入的二分之一,到底输入一段句子,输出英文的句子要多长,由机器自己决定
-
甚至可以做更复杂的问题,比如说做语音翻译
语音翻译就是,你对机器说一句话,比如说machine learning,他输出的不是英文,他直接把他听到的英文的声音讯号翻译成中文文字
你对他说machine learning,他输出的是机器学习
為什麼我们要做,Speech Translation这样的任务,為什麼我们不直接先做一个语音辨识,再做一个机器翻译,把语音辨识系统跟机器翻译系统,接起来 就直接是语音翻译?
因為世界上有很多语言,他根本连文字都没有,世界上有超过七千种语言,有超过半数其实是没有文字的,对这些没有文字的语言而言,你要做语音辨识,可能根本就没有办法,因為他没有文字,所以你根本就没有办法做语音辨识,但我们有没有可能对这些语言,做语音翻译,直接把它翻译成,我们有办法阅读的文字
语音辨识(台语声音讯号--->繁体中文文字)
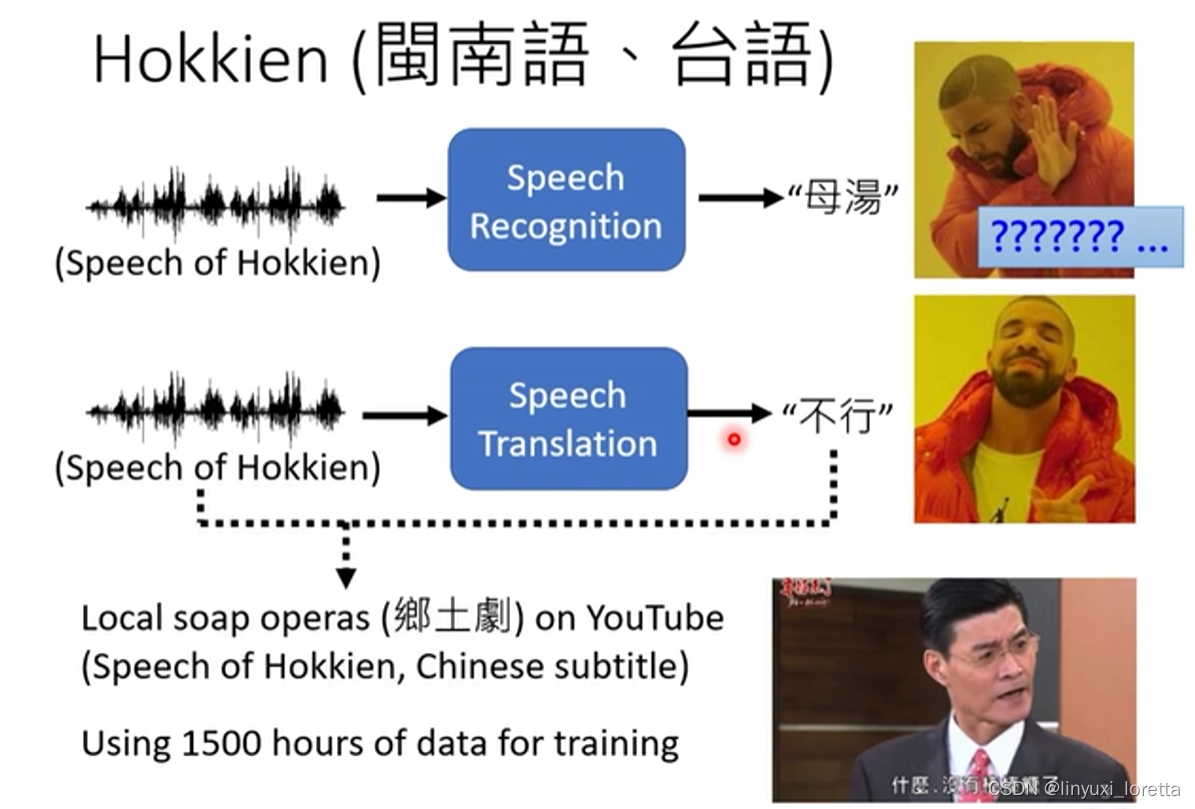
一个很好的例子也许就是,台语的语音辨识, 台语是有文字的,并没有那麼普及,现在听说小学都有教台语的文字了,但台语的文字,并不是一般人能够看得懂的
(可以做猫语翻译吗,哈哈.....猫语言要有训练集才行)
我们可以训练一个类神经网路,这个类神经网路听某一种语言 的声音讯号,输出是另外一种语言的文字。
今天你要训练一个neural network,你就需要有input跟output的配合,你需要有台语的声音讯号,跟中文文字的对应关係,那这样的资料是比较容易收集的。比如说YouTube上面,有很多的乡土剧
乡土剧就是,台语语音 中文字幕,所以你只要它的台语语音载下来,中文字幕载下来,你就有台语声音讯号,跟中文之间的对应关係,你就可以硬train一个模型,你就可以train一个transformer,然后叫机器直接做台语的语音辨识,输入台语 输出中文
那你可能会觉得这个想法很狂,而且好像听起来有很多很多的问题,那我们实验室就载了,一千五百个小时的乡土剧的资料,然后 就真的拿来训练一个,语音辨识系统

你可能会觉得说,这听起来有很多的问题
- 乡土剧有很多杂讯,有很多的音乐,---->不要管它
- 乡土剧的字幕,不一定跟声音有对起来,---->不要管它
- 台语还有一些,比如说台罗拼音,台语也是有类似音标这种东西,也许我们可以先辨识成音标,当作一个中介,然后在从音标转成中文,---> 也没有这样做
直接训练一个模型,输入是声音讯号,输出直接就是中文的文字,这种没有想太多 直接资料倒进去,就训练一个模型的行為,就叫作硬train一发
那你可能会想说,这样子硬train一发到底能不能够,做一个台语语音辨识系统呢,其实 还真的是有可能的,以下是一些真正的结果
机器在听的一千五百个小时的,乡土剧以后,你可以对它输入一句台语,然后他就输出一句中文的文字,以下是真正的例子
机器听到的声音是这样子的

- 前两个ok
- 比如 听到四个音节 没代没誌(台语),但它知道说 也许应该输出 没事,
- 但机器其实也是蛮容易犯错的,
- (有时候从台语,转成中文句子需要倒装)如果台语跟中文的关係需要倒装的话,看起来学习起来还是有一点困难
这个例子想要告诉你说,直接台语声音讯号转繁体中文,不是没有可能,是有可能可以做得到的,那其实台湾有很多人都在做,台语的语音辨识,如果你想要知道更多有关,台语语音辨识的事情的话,可以看一下下面这个网站
Text-to-Speech (TTS) Synthesis 语音合成
台语语音辨识反过来,就是台语的语音合成,我们如果是一个模型,输入台语声音 输出中文的文字,那就是语音辨识,反过来 输入文字 输出声音讯号,就是语音合成
这边就是demo一下台语的语音合成, 只要google 台湾媠声,就可以找到这个资料集, 裡面就是台语的声音讯号,
不过这边是需要跟大家说明一下,现在还没有真的做End to End的模型,这边模型还是分成两阶,他会先把中文的文字,转成台语的台罗拼音,就像是台语的KK音标,在把台语的KK音标转成声音讯号,
不过从台语的KK音标,转成声音讯号这一段,就是一个像是Transformer的network,其实是一个叫做echotron的model,它本质上就是一个Seq2Seq model,大概长的是这个样子 (右上角图)

所以你真的是可以,合出台语的声音讯号的,就用我们在这一门课裡面学到的,Transformer或者是Seq2Seq的model
Seq2seq for Chatbot 聊天机器人
刚才讲的是跟语音比较有关的,那在文字上,也很广泛的使用了Seq2Seq model
举例来说你可以用Seq2Seq model,来训练一个聊天机器人

聊天机器人就是你对它说一句话,它要给你一个回应,输入输出都是文字,文字就是一个vector Sequence,所以你完全可以用Seq2Seq 的model,来做一个聊天机器人
你就要收集大量人的对话,像这种对话你可以收集,电视剧 电影的台词 等等,
假设在对话裡面有出现,某一个人说Hi,和另外一个人说,Hello How are you today,那你就可以教机器说,看到输入是Hi,那你的输出就要跟,Hello how are you today,越接近越好
那就可以训练一个Seq2Seq model,那跟它说一句话,它就会给你一个回应
Question Answering (QA) NLP
那事实上Seq2Seq model,在NLP的领域,在natural language processing的领域的使用,是比你想像的更為广泛,其实很多NLP的任务,都可以想成是question answering,QA的任务
所谓Question Answering,就是给机器读一段文字,然后你问机器一个问题,希望他可以给你一个正确的答案。而很多你觉得跟QA没什么关系的任务,都可能可以想象成是QA。举例来说:
- 假设你今天想做的是翻译,那机器读的文章就是一个英文句子,问题就是这个句子的德文翻译是什麼,然后输出的答案就是德文
- 自动摘要,摘要就是给机器读一篇长的文章,叫他把长的文章的重点节录出来,那你就是给机器一段文字,问题是这段文字的摘要是什麼,然后期待他答案可以输出一个摘要
- 或者是你想要叫机器做Sentiment analysis, 就是机器要自动判断一个句子,是正面的还是负面的;假设你有做了一个產品,然后上线以后,你想要知道网友的评价,但是你又不可能一直找人家ptt上面,把每一篇文章都读过,所以就做一个Sentiment analysis model,看到有一篇文章裡面,有提到你的產品,然后就把这篇文章丢到,你的model裡面,去判断这篇文章,是正面还是负面。你就给机器要判断正面还负面的文章,问题就是这个句子,是正面还是负面的,然后希望机器可以告诉你答案
所以各式各样的NLP的问题,往往都可以看作是QA的问题,而QA的问题,就可以用Seq2Seq model来解

具体来说就是有一个Seq2Seq model输入,问题跟文章把它接在一起,输出就是问题的答案,就结束了;你的问题加文章合起来,是一段很长的文字,答案是一段文字
Seq2Seq model只要是输入一段文字,输出一段文字,只要是输入一个Sequence,输出一个Sequence就可以解,所以你可以把QA的问题,硬是用Seq2Seq model解,叫它读一篇文章读一个问题,然后就直接输出答案,所以各式各样NLP的任务,其实都有机会使用Seq2Seq model

必须要强调一下,对多数NLP的任务,或对多数的语音相关的任务而言,往往為这些任务客製化模型,你会得到更好的结果
但是各个任务客製化的模型,就不是我们这一门课的重点了,如果你对人类语言处理,包括语音 包括自然语言处理,这些相关的任务有兴趣的话呢,可以参考一下 课程网页的链接(如图),就是去年上的深度学习与人类语言处理,这门课的内容裡面就会教你,各式各样的任务最好的模型,应该是什麼
举例来说在做语音辨识,我们刚才讲的是一个Seq2Seq model,输入一段声音讯号,直接输出文字,今天啊 Google的 pixel4,Google官方告诉你说,Google pixel4也是用,N to N的Neural network,pixel4裡面就是,有一个Neural network,输入声音讯号,输出就直接是文字
但他其实用的不是Seq2Seq model,他用的是一个叫做,RNN transducer的 model,像这些模型他就是為了,语音的某些特性所设计,这样其实可以表现得更好。
Seq2seq for Syntactic Parsing 文法剖析
刚才我们讲了很多Seq2Seq model,在语音还有自然语言处理上的应用, 其实有很多应用,你不觉得他是一个Seq2Seq model的问题,但你都可以硬用Seq2Seq model的问题硬解他
举例来说文法剖析,给机器一段文字,机器要做的事情是產生,一个文法的剖析树

那今天文法剖析要做的事情,就是產生这样子的一个Syntactic tree,所以在文法剖析的任务裡面,假设你想要用deep learning解的话,输入是一段文字,他是一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









