







 本文介绍了一个使用Python爬虫批量下载FTP服务器上SPSS Modeler相关文件的实战案例。通过观察文件URL规律,查找并提取.pdf文件名,结合FTP目录构造完整文件链接进行下载。
本文介绍了一个使用Python爬虫批量下载FTP服务器上SPSS Modeler相关文件的实战案例。通过观察文件URL规律,查找并提取.pdf文件名,结合FTP目录构造完整文件链接进行下载。
今天在查有关spss modeler的参考资料时,发现了这个网站:
ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/14.2/zh_CN/
里面包含了许多有关spss modeler的文件,于是想用爬虫把它们都爬取下来。
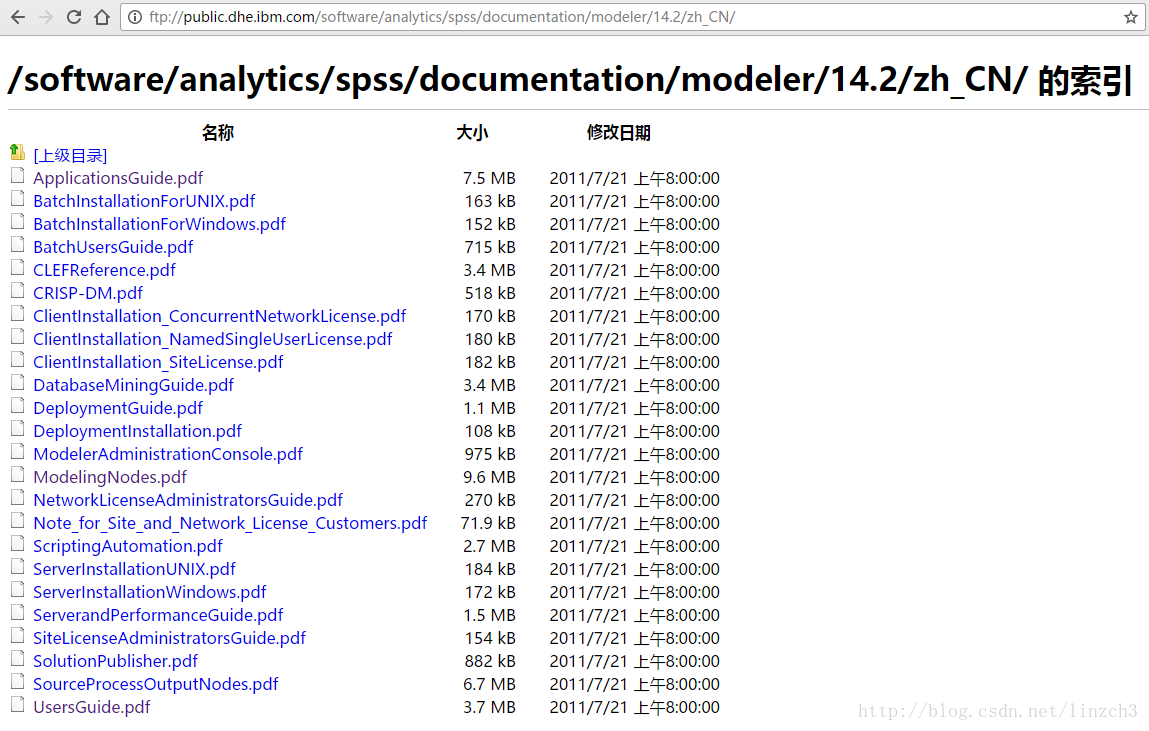
文件不多,但是想到以后可能会遇到文件比较多的情况,到时候再根据这个程序拓展一下便可以了(虽然又要分析一次源代码~囧)。
废话少说,干活~
首先,观察文件的链接,对于第一个文件,它的url为:

对于第二个文件,它的url为ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









