






导读:AI大模型日报,爬虫+LLM自动生成,一文览尽每日AI大模型要点资讯!
目前采用“文心一言”(ERNIE-4.0-8K-latest)、“智谱AI”(glm-4-0520)生成了今日要点以及每条资讯的摘要。欢迎阅读!
《AI大模型日报》今日要点:智谱AI在KDD 2024上展示了其全新大模型GLM-4-Plus,该模型在多任务上逼近甚至超越GPT-4o,并推出了支持中英双语的对话机器人等功能,巩固了中国在全球大模型领域的领先地位。而阿里发布的开源多模态模型Qwen2-VL则支持实时视频对话,并在多项指标上超越了GPT-4o。此外,阿里通义推出了一键生成PPT的新产品,提升工作效率的同时也提醒用户警惕AI生成的错误。然而,在行业发展的同时,Runway突然删除HuggingFace库并停止维护,引发业内关注。 另一方面,米哈游创始人蔡浩宇的新AI公司Anuttacon曝光,旨在用AI为游戏玩家创造新体验,吸引了多位技术大牛加入。在AI技术应用上,人大北邮上海AI Lab等提出了让AI更懂物理世界的多模态分割新方法Ref-AVS,谷歌也升级了其Gemini AI平台,推出全新AI定制助手Gems,图像生成模型Imagen 3也支持生成人物图像,标志着个性化AI体验的转变。
标题: 一手实测结果出炉!智谱「超大杯」模型全家桶亮相KDD,部分任务超越GPT-4o

摘要: 智谱AI发布全新大模型GLM-4-Plus,在多任务上逼近甚至超越GPT-4o,同时推出视频通话功能。在KDD 2024上,智谱AI展示了支持中英双语的对话机器人ChatGLM和基础模型的重大升级。新模型在语言理解、指令遵循等方面性能全面提升,达到国际领先水平。此外,智谱还发布了文生图模型CogView-3-Plus和图像/视频理解模型GLM-4V-Plus,后者是国内首个通用视频理解模型API。智谱清言也升级为首个可以通过文本、音频、视频和图像多模态互动的AI助手,开放给部分用户。这些进展巩固了中国在全球大模型领域的领先地位。
网址: 一手实测结果出炉!智谱「超大杯」模型全家桶亮相KDD,部分任务超越GPT-4o | 机器之心
标题: 6小时视频,一键转成PPT,赵晓卉们再也不用发疯了
摘要: 阿里通义推出最新PPT产品,主打一键生成功能,包括音视频转PPT,可大幅提高工作效率。同时,该产品还支持一句话生成PPT和上传文档生成PPT。与Kimi的PPT助手相比,通义PPT模板较少但设计排版高级,内容准确性高,不过生成速度稍慢,且存在内容错误和配图问题。因此,在使用AI生成PPT时,需要警惕其错误,将其视为提高效率的工具而非完全依赖。
网址: 6小时视频,一键转成PPT,赵晓卉们再也不用发疯了 | 机器之心
标题: Runway突然删除HuggingFace库!网友:真跑(Run)路(Way)了
摘要: Runway突然删除在HuggingFace上的所有内容,并声明不再维护,引发网友热议。其之前的项目如Stable Diffusion v1.5也无法访问。此事在Reddit、Twitter上引起关注,网友猜测原因并分享替代资源。截至发文,官方未给出解释。欢迎读者留言讨论。
网址: Runway突然删除HuggingFace库!网友:真跑(Run)路(Way)了 | 机器之心
标题: 米哈游蔡浩宇新AI公司曝光,挖Llama 3科学家坐镇大模型

摘要: 米哈游创始人蔡浩宇的新AI公司Anuttacon曝光,该公司旨在用AI为游戏玩家创造新体验。Anuttacon与米哈游关联紧密,注册地点相同,且招聘地点与蔡浩宇领英账号标注地点一致。新公司吸引了微软图形学大佬童欣等技术大牛加入,团队包括大模型研究负责人和互联网基础设施老将。蔡浩宇认为AI将改变游戏行业格局,Anuttacon或成为行业前0.0001%的精英团队。米哈游则可能负责打造“人人都可以制作游戏的平台”,服务于剩余的99%。
网址: 米哈游蔡浩宇新AI公司曝光,挖Llama 3科学家坐镇大模型 | 量子位
标题: 让AI更懂物理世界!人大北邮上海AI Lab等提出多模态分割新方法

摘要: 要点提炼: 人大高瓴GeWu-Lab、北邮、上海AI Lab等机构的研究人员提出了一种名为Ref-AVS的多模态分割新方法,该方法整合文本、音频和视觉模态,让AI更懂真实物理世界。相关论文已入选ECCV2024,数据集和代码已开源。Ref-AVS通过构建包含多样指代表达式的数据集Ref-AVS Bench,并设计端到端框架高效处理多模态线索,实现了对动态视听场景中对象的精准分割。该方法在定量和定性实验中均表现出色,具有可泛化性和准确性。
网址: 让AI更懂物理世界!人大北邮上海AI Lab等提出多模态分割新方法 | 量子位
标题: 超越GPT-4o!阿里发布最强开源多模态模型Qwen2-VL,支持实时视频对话
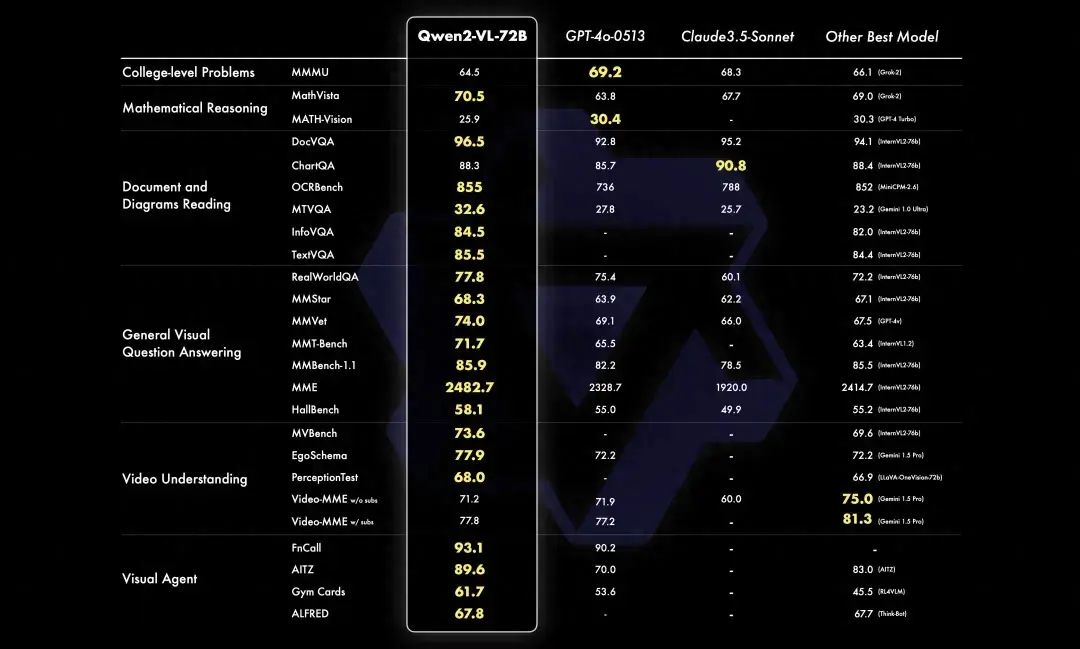
摘要: 阿里发布了新的开源多模态模型Qwen2-VL,该模型在图像和视频理解任务上取得了SOTA,并且在多项指标上超越了GPT-4o等闭源模型。Qwen2-VL支持实时视频对话,并能操纵手机和机械臂。该模型有三个版本,其中2B和7B版本可免费商用,而72B版本通过API提供。Qwen2-VL的创新之处包括对原生动态分辨率的全面支持以及多模态旋转位置嵌入,这些创新提升了模型的多模态处理和推理能力。
网址: 超越GPT-4o!阿里发布最强开源多模态模型Qwen2-VL,支持实时视频对话 | 量子位
标题: Imagen 3支持人物生成,人人可用!谷歌Gemini AI重大升级来了
摘要: 谷歌升级了Gemini AI平台,并推出全新AI定制助手Gems,面向150多个国家。同时,其图像生成模型Imagen 3也支持生成人物图像,并向公众开放。Imagen 3可以根据文本提示创建高质量图像,并采取了安全措施以避免生成不准确或具有误导性的内容。此外,Gems助手可以为企业和商业用户提供定制化的AI解决方案,标志着个性化AI体验的转变。这一新功能可能对多个行业产生深远影响,同时也引发了关于数据隐私、工作替代和潜在滥用的问题。
网址: Imagen 3支持人物生成,人人可用!谷歌Gemini AI重大升级来了|ai|gemini|imagen|人物生成|微软|语音助手功能|谷歌_手机网易网
欢迎阅读《AI大模型每日早报》
- 每天上班前5分钟,一文览尽AI大模型最新资讯!(每个工作日早9点前更新)
- 基于Python爬虫+LLM以及多年资深科技编辑(前《程序员》编辑部主任、前北京智源人工智能研究院《AI每日资讯》主笔)合作完成。
- 应用AI技术、传播AI动态的典型范例。


















 5176
5176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











