







环境部署
背景
手里面新到一台老电脑,重新安装了系统之后,想开始学习点东西,准备先将环境部署完毕。预计会安装科学上网、WSL,Windows Terminal,VSCode,Everything, PyCharm,Anaconda,Oh my zsh,git,jupyter,ollama,OpenWebUI,docker,go等
- 基本配套工具系列
- 搜狗输入法,Everything,Chrome,科学上网工具
- Anaconda系列:傻瓜式部署机器学习环境
- 包括Anaconda,jupyter,PyCharm,windows git
- WSL系列:linux命令行,操作丝滑
- 包括WSL,windows terminal ,oh my zsh,vscode,go
- Ollama:体验使用大模型
- 包括ollama,OpenWebUI,DockerDesktop
聊以本文记录安装的过程,以及学习的过程,如果学习的内容越来越多,会另开一个来记录。使用CPT代表Chat GPT
安装科学上网工具,Chrome、微信、输入法、Everything
- 科学上网工具请自行学习搜索
- Chrome登录Google账户
- 输入法登录个人账户,删除微软拼音输入法,只保留搜狗和英文
- Everything设置快捷键:Alt+A
配置CPT4
- 前期准备
- 海外的Apple ID:我是通过科学上网切换VPN地址到海外,然后直接用手机申请的海外Apple ID
- 手机购买卡券(https://www.163.com/dy/article/ITMC7PRF05502J8M.html)
- 支付宝切换到美国-旧金山
- 搜索Pocky Shop
- 找到 App Store& iTunes,显示可以购买2-500 US
- 输入想购买的金额,使用支付宝付款
- 稍等几分钟,会收到邮件(第一次购买需要配置邮件地址),邮件中会有Gift Card Number,用于向海外Apple账户充值
- 通过卡券号码向海外Apple ID账户充钱
- 手机登录海外Apple ID
- 手机打开软件 AppStore
- 点击个人账户-》选择兑换充值卡或代码
- 输入邮件中收到的礼品卡号进行兑换
- CPT订阅CPT Plus
- 手机下载CPT,登录账户
- 点击个人订阅
- 选择升级CPT Plus,使用Apple账户进行支付。
安装WSL
参考文档:https://learn.microsoft.com/zh-cn/windows/wsl/install
- Windows打开PownerShell,输入
wsl --install - 设置WSL版本为version 2
- 我一般使用Ubuntu18.04,输入
wsl --install -d Ubuntu-18.04- 可以使用
wsl -l -o查看支持的发行版本,也可以直接通过Microsoft Store来搜索安装
- 可以使用
安装windows terminal
个人感觉在Winodws下还挺好用,支持分屏操作,多窗口Tab,但是感觉搜索高亮功能不够完善
- 打开Microsoft Store,搜索windows Terminal
- 安装Terminal,我一般安装的Preview尝鲜版本
- 打开Terminal,选择Ubuntu 18.04 LTS
- 修改Root的password:
sudo passwd root - 设置默认登录为root:
ubuntu1804 config --default-user root ctrl+,打开配置,选择Appearence中的Language,选择中文
安装oh my zsh
- sudo apt install zsh -y
- apt-get -y install build-essential nghttp2 libnghttp2-dev libssl-dev
- 安装oh my zsh:https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh
- 安装语法高亮以及自动提示
git clone https://github.com/zsh-users/zsh-autosuggestions $ZSH_CUSTOM/plugins/zsh-autosuggestions
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git $ZSH_CUSTOM/plugins/zsh-syntax-highlighting
安装vscode
- 安装各种C++插件,打开terminal,使用
code .确认可以切换到WSL的terminal环境 - 安装
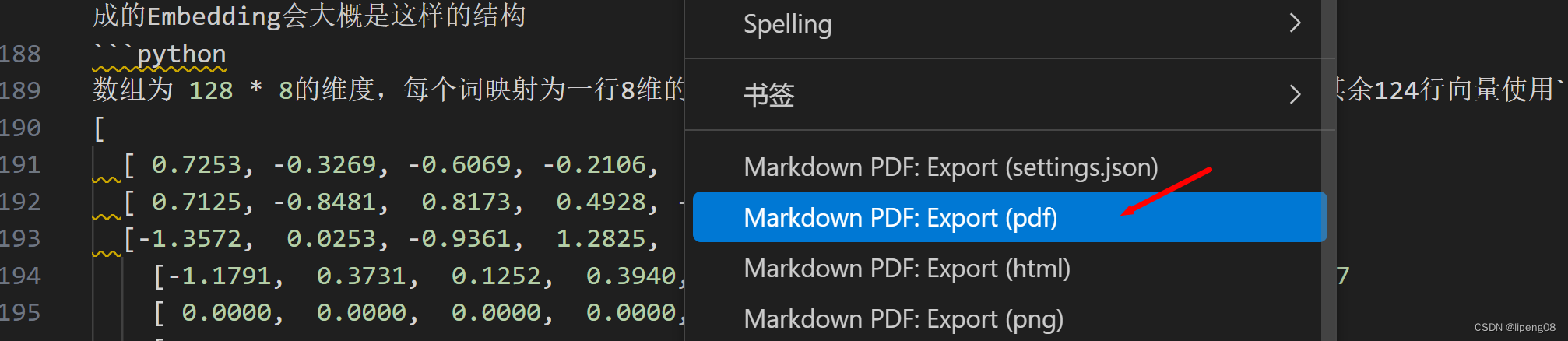
Markdown PDF插件:对于打开的PDF文档,右键Markdown PDF:Export(pdf)即可将md文档导出为PDF文件,默认放到windows账户的下载目录
安装Anaconda&Jupyter
使用Windows版本,小白必备,不折腾WSL中的Anaconda
- 下载Anaconda & 安装它
- 启动Anaconda Navigator
- 点击Environment,创建虚拟环境,注意选择python 3.10版本(刚开始选的3.11有问题)
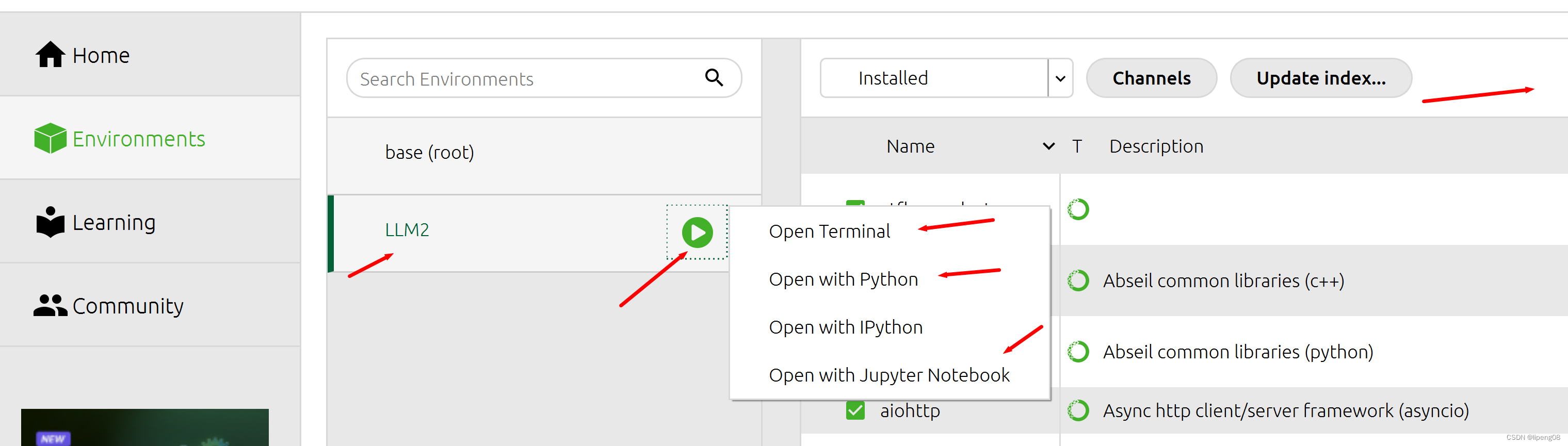
- 虚拟环境LLM2,可以通过界面右上角的搜索来给该虚拟环境安装需要的各种Python库
- 可以通过菜单
Open With Jupyter Notebook来启动Jupyter
- 在该虚拟环境中安装jupyter notebook(点击Navigator->Home->Jupyter NoteBook)
- 安装完毕,点击 Launch 启动 jupyter
- 自动打开网址:
http://localhost:8888/tree,端口可能不一致 - 默认打开的目录是Windows下的主账户Home目录,可以自定义目录
- 设置jupyter的启动路径:
https://www.cnblogs.com/pgzhang/p/9144090.html - a. 生成配置文件:
jupyter notebook --generate-config,配置文件默认路径在:C:\Users\Admin\.jupyter\jupyter_notebook_config.py,Admin为Windows当前账户名 - b. 修改jupyter_notebook_config.py文件中的:
c.NotebookApp.notebook_dir = '期望路径如本文的C:\workspace\llm目录',注意删除注释
- 设置jupyter的启动路径:
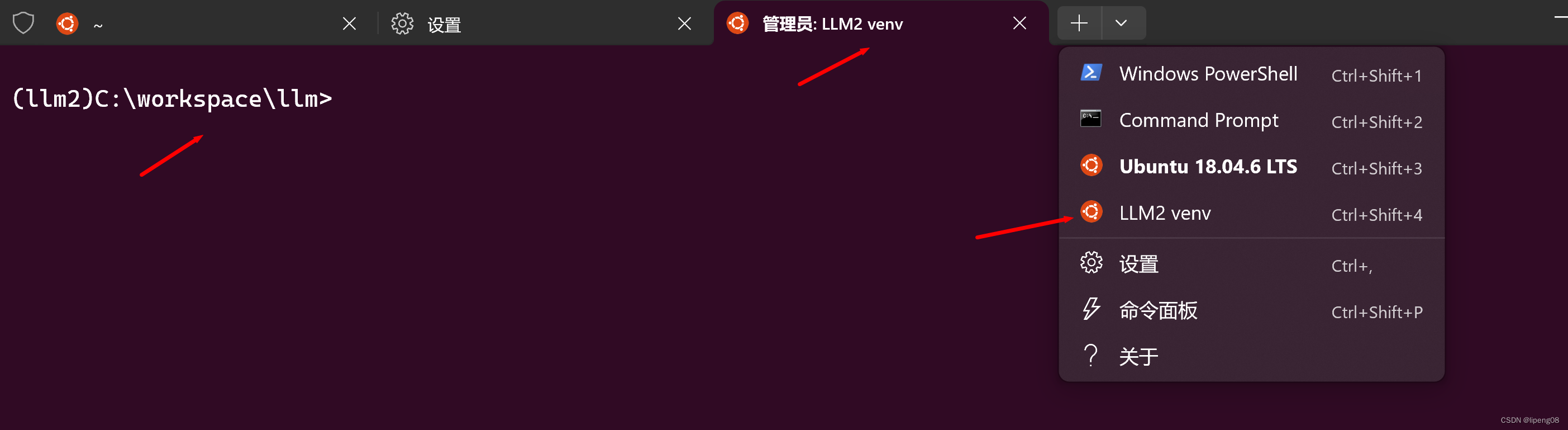
Windows Terminal增加LLM2虚拟环境的打开菜单
- 如下图所示,配置
LLM2 venv的菜单,并默认进入到c:\workspace\llm目录中
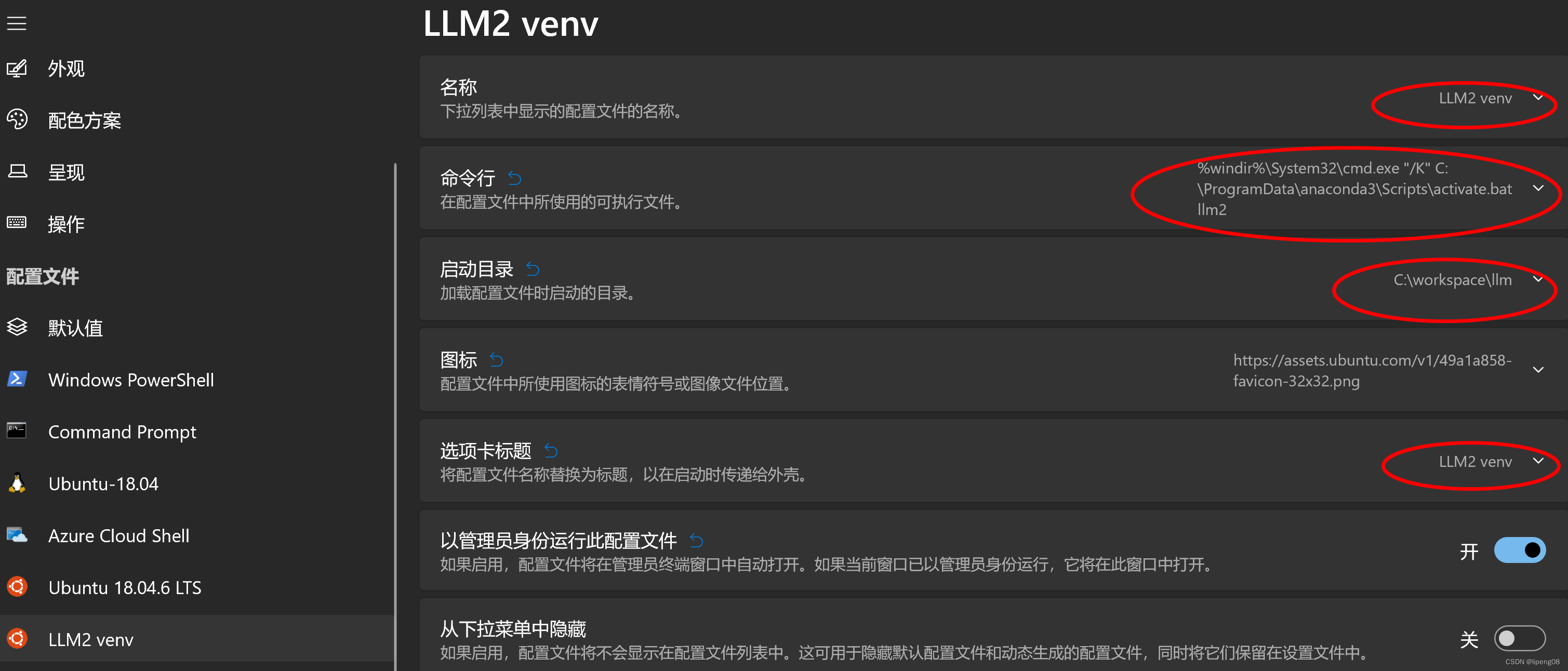
- 打开配置,新建配置文件,填对
命令行和启动目录,即可增加新的下拉菜单,方便快速打开LLM2虚拟环境
安装PyCharm
- 下载
Windows Pycharm并安装 - 设置PyCharm的解释器为
LLM2虚拟环境的解释器(如果没有,先添加LLM的Python解释器)- 创建一个Python project,进入设置->项目->Python解释器
- 我这边将PyCharm的语言修改为中文,英文对照即可
- PyCharm会自动根据设置的python解释器进行解析,构建LLM2虚拟环境安装的各种库的索引,用于Python代码的自动补全等辅助编程的工作
- 创建一个Python project,进入设置->项目->Python解释器
安装windows git
有WSL环境,为何还需要安装git.exe?这是用于和PyCharm进行更亲密的配合。有了它,可以在PyCharm中利用windows git查看代码的更新diff等,当然这只是方便界面操作,我依然更习惯切换到WSL命令行进行各种git命令,更熟悉些。
- PyCharm打开Terminal,快捷键:
Alt+F12 - 在终端的下拉中选择设置,进入到工具->终端,将WSL作为默认终端(方便命令行,当前默认是
powershell.exe)- 配置默认标签页名称:
Ubuntu18-04 - 配置Shell路径:
wsl.exe - 当然,你可以随自己喜好配置其它命令,例如git bash:
"C:\Program Files\Git\bin\bash.exe" --login -i
- 配置默认标签页名称:
机器学习
本文的目标是为了对大模型有个基本的认识,为了快速达成,我们直接跳过统计机器学习的基本路线,计划基于两个角度来切入到大模型:一个是从理论角度,一个是从开发角度,一个从体验角度
- 理论角度:基于很多视频教程、论文、博客等内容,逐步增加对大模型的理解(备注:这里的理论是非系统性的、非周密型的总结,而是一些相对能理解的知识而已)
- 开发角度:基于一个有很多
star的开源代码仓库,逐步抄袭并理解大模型的代码,开发实践 - 体验角度:基于一个可以本地部署并体验大模型的工具
Ollama,来体验各种开源大模型,并在有能力的话进行微调
后文这三个部分的内容会独立演进
理论角度
通过看视频教程,论文以及博客等相关内容,增加自己对大模型的理论理解,将理解的内容缩小下呈现到本文档中。台大的李宏毅Transformer视频教程:
https://www.youtube.com/watch?v=n9TlOhRjYoc
Seq2Seq的应用场景
很多现实的需求都可以看作是QA的问题,可以通过seq2seq模型来解决,举例如下:
- 从英文翻译到德文:这段英文的德文是什么
- 文章总结:这段文字的摘要是什么?
- 文章情感属性:这段文字是否是积极的态度?
这些都可以归类为Question, context -> Seq2Seq -> Anser。不过要注意的是虽然Seq2seq可用来解决很多通用问题,但对各式各样的任务使用特质化的模型往往可以表现得更好
Seq2seq的应用领域
- Seq2seq for 文法解析
- 给一句话,生成一个文法树
- deep learning is very powerful -> (S (NP deep learning) (VP is) (ADJV very powerful) ) )
- Seq2seq for multi-label 分类
- 一个对象可以隶属于多个类别,每个文章对应的类别数目都可能是不一样的
- 输入一篇文章,输出class数组,由机器决定输出多少个类别
- Seq2seq for Object Dection
- https://arxiv.org/abs/2005.12872
Seq2seq模型
将输入序列经过编码器和解码器得到相应的输出,即input sequence -> Encoder -> Decoder -> output sequence,相关论文如下:
- Sequence to Sequence Learning with Neural Networks: arx1409.3215,最早2014年
- Attention is All you need: Transformer, arx1706.03762,最早2017年
Encoder & Decoder
- Nx:表明重复N次,即网络分为多层Block
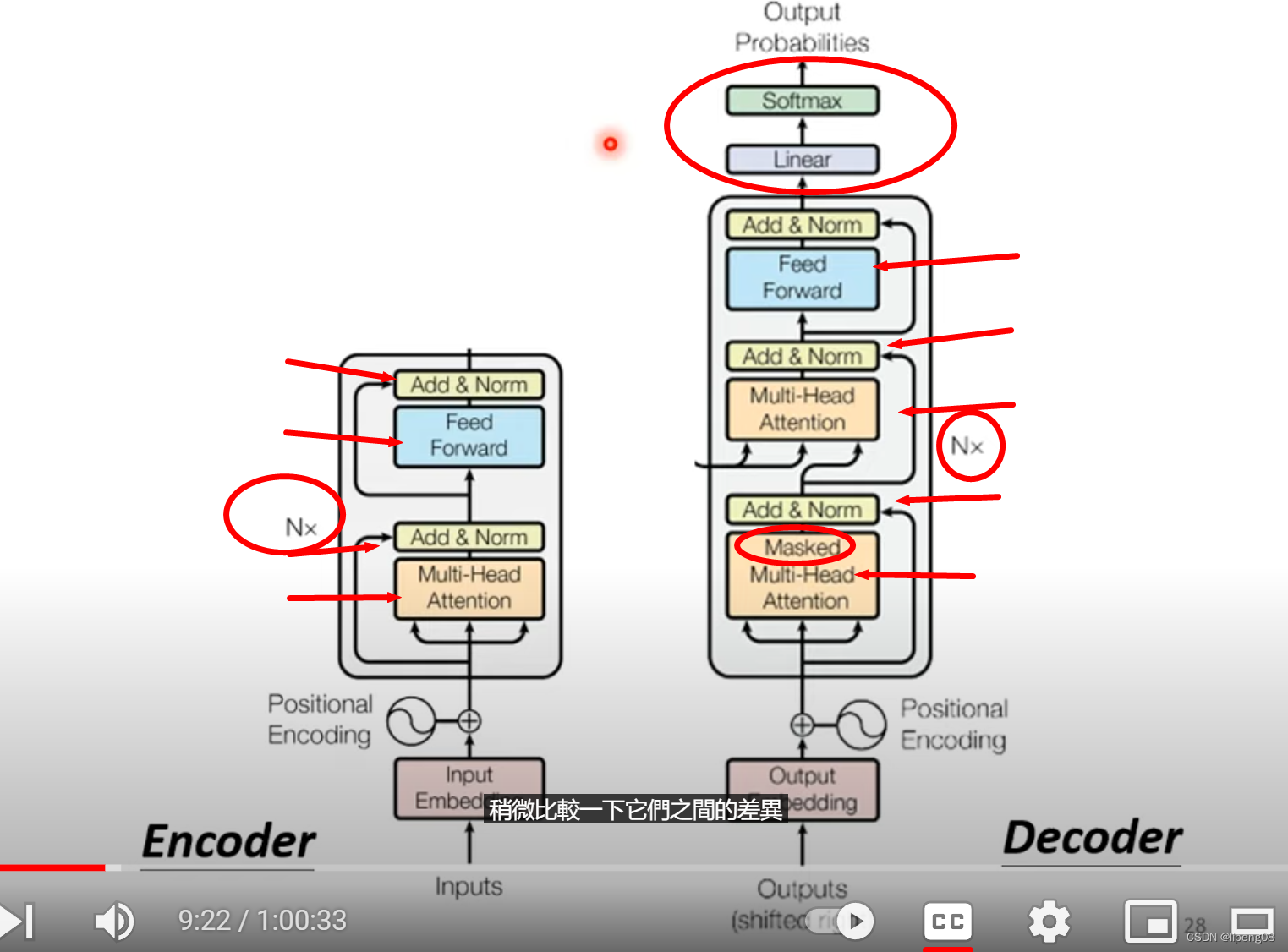
Encoder
李宏毅视频: https://www.youtube.com/watch?v=n9TlOhRjYoc
输入一排向量 经过Encoder, 输出一排向量。Encoder本身是由多层网络Block构成,每层Block又是Attention和FC(Full connected)的组合,如下图:
单个Block层
如下图,左边输入b经过Self-attention得到输出a,该输出a和 输入b相加,得到residuala+b,它继续传递到Layer Norm层归一化(LayerNorm对同一个example里面不同的dimension计算mean和sigma,比较特别),随后它的输出才会左边,即FC层,并同样使用residual,最后输出到新的norm层,这是一个完整的Bock层
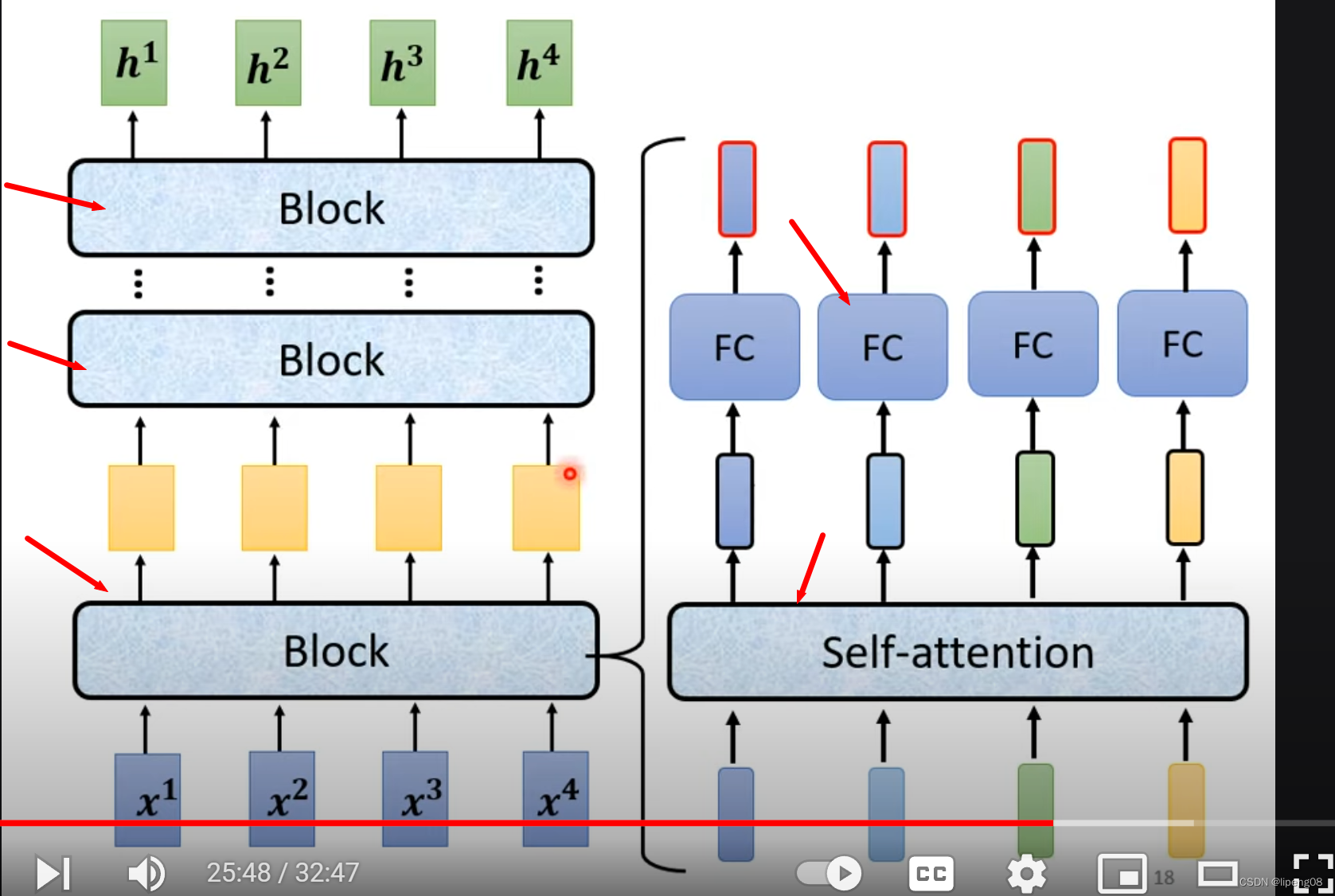
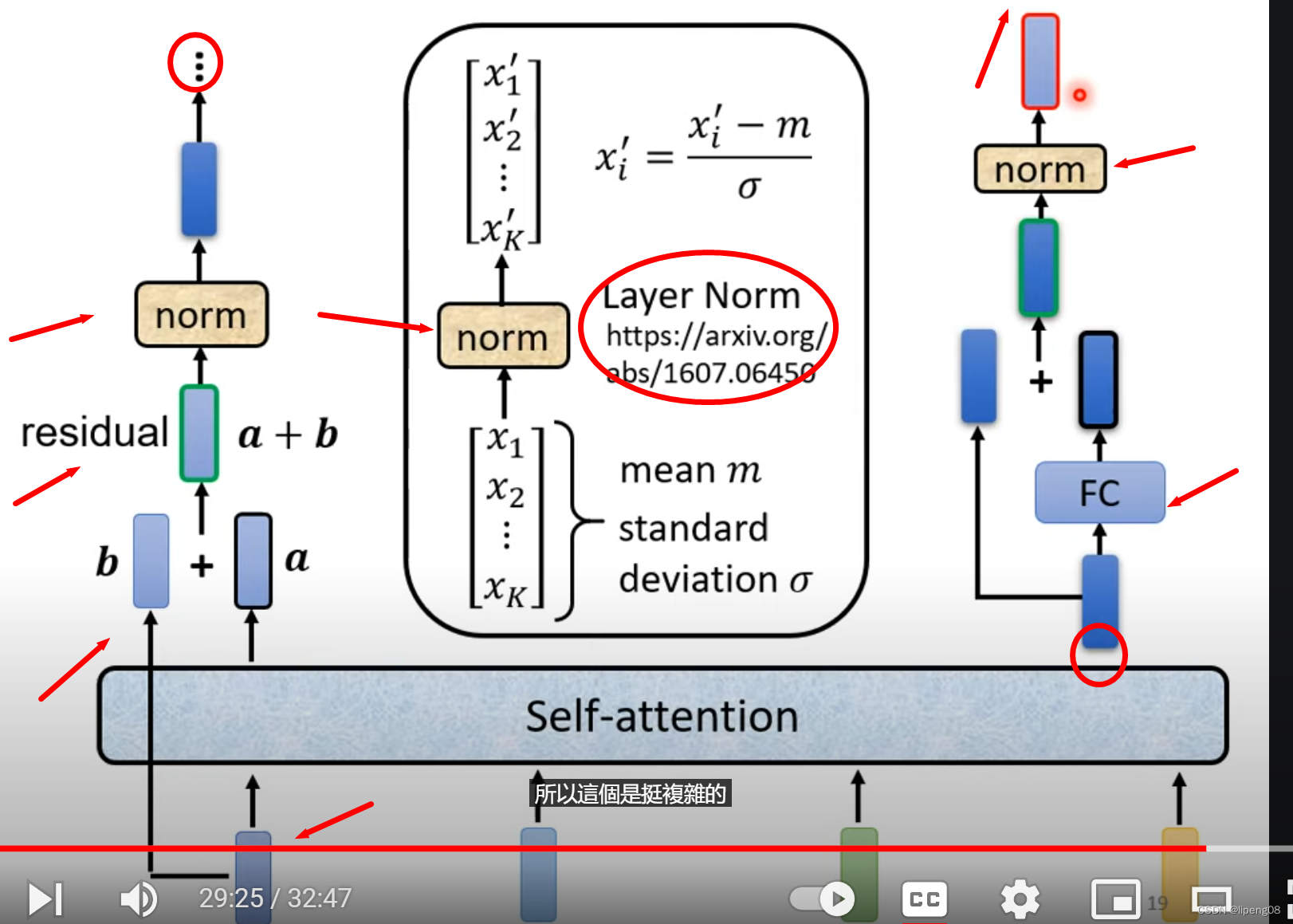
Encoder快速总结
输入 -> MultiHead Attention -> Residual + Layer Norm -> FC -> Residual + Layer Norm -> 上述网络重复N遍 -> 输出
问题
- Residual的价值
Decoder
李宏毅视频: https://www.youtube.com/watch?v=N6aRv06iv2g
不同的模型的输出单位:中文使用的字,英文可以使用word,subword或者字母。BEGIN是一个特殊符号,BEGIN输入之后经过Decoder+Softmax,得到所有token中概率最大的那个token,例如是机,然后将机作为下一个token的输入,继续经过Decoder+Softmax,直到整个序列处理完毕。
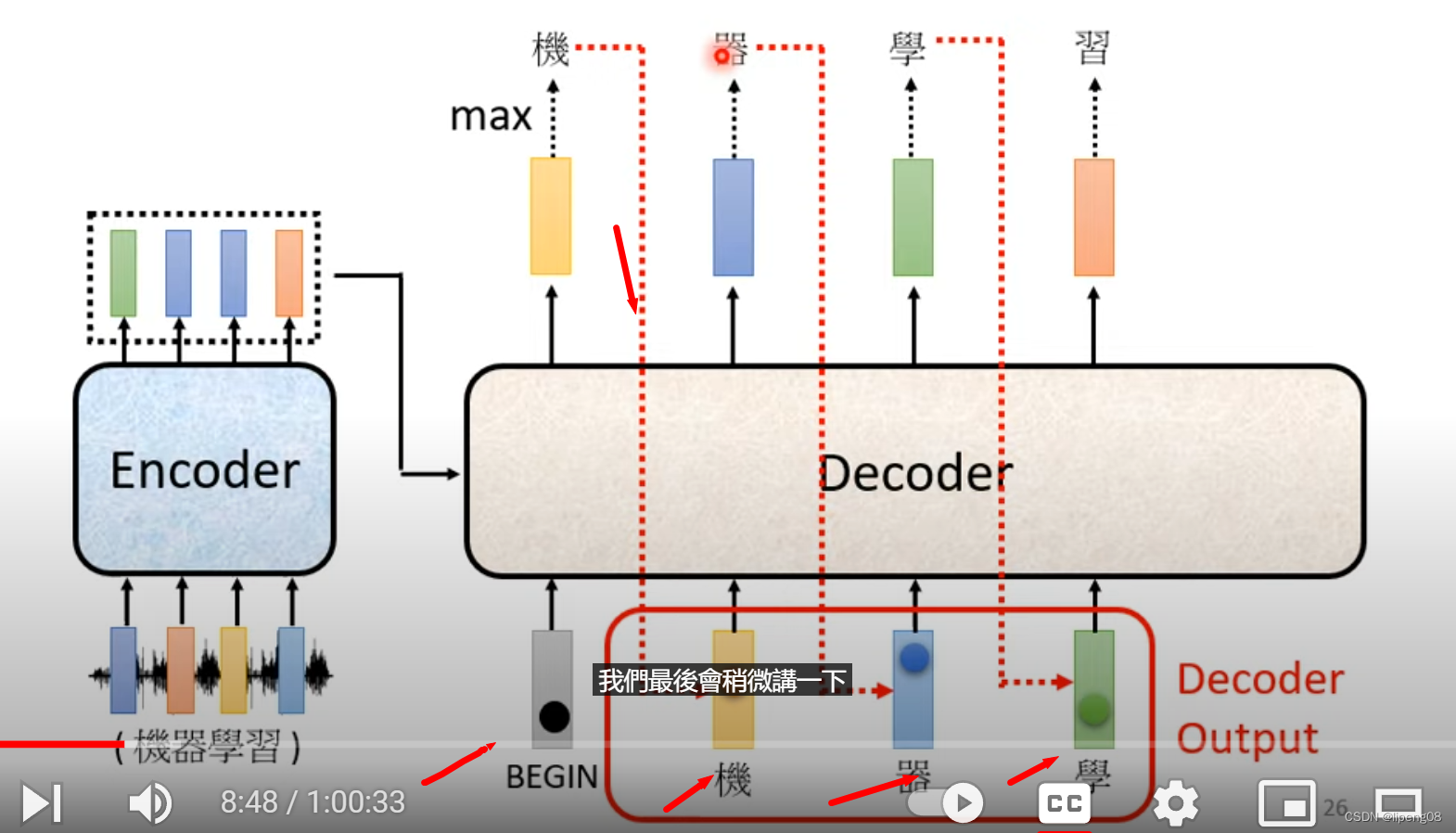
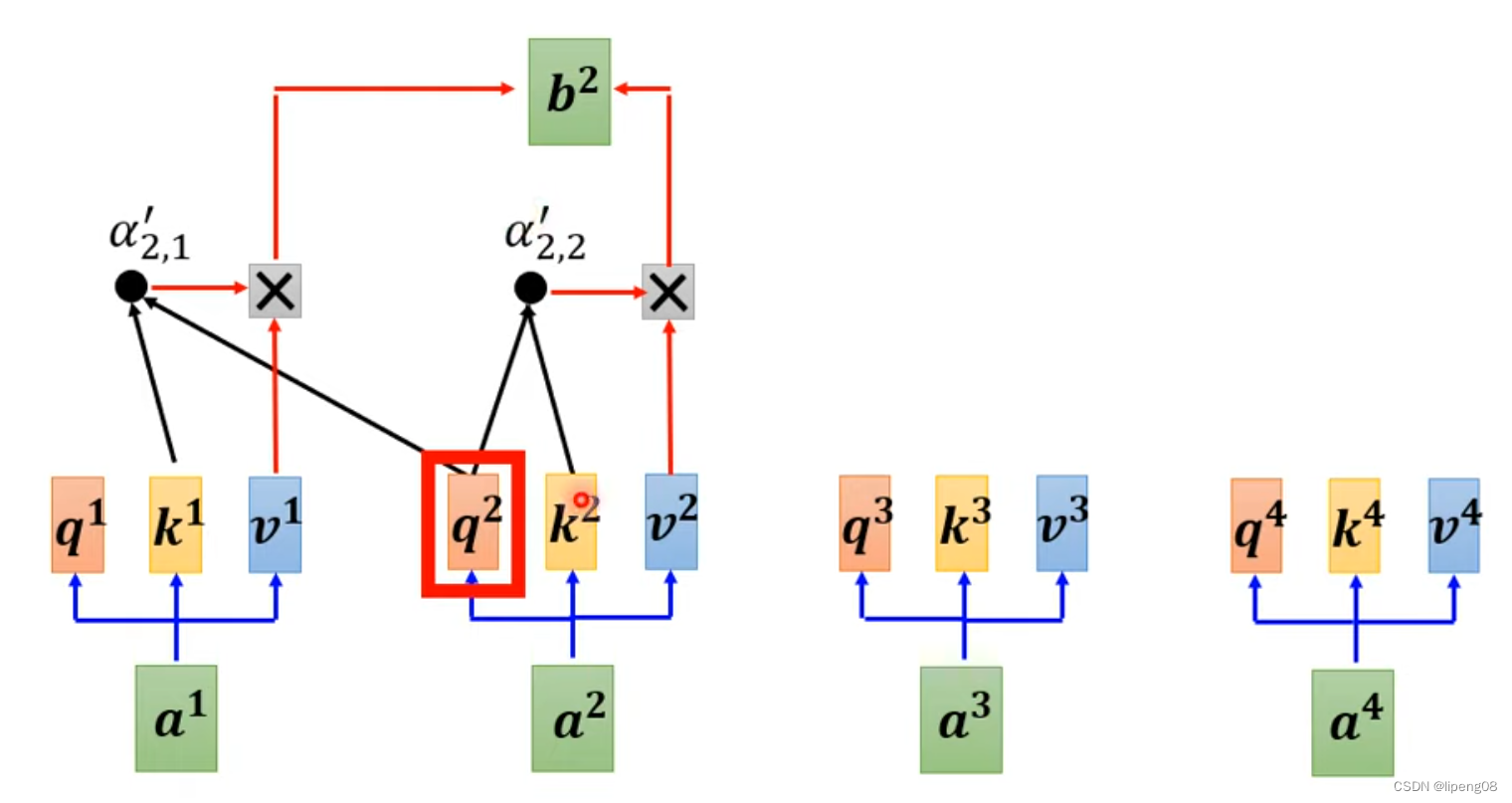
Decoder Attention层
Decoder里面的Attention叫Masked Self Attention,指的是产生b2的时候,只能看a1、a2这几个,不能考虑a3或者a4。为什么需要masked,这是因为Decoder的输出token是逐个产生的,先有a1,a2,才能有a3,a4等。那什么时候停止输出token呢,即END成为概率最大的Token时。
AutoRegression()
AT Decoder:逐个字产生,上一个token的输出作为这个token的输入
NAT Decoder:一组BEGIN作为输入,同时产生多个token输出,并行度好,但是性能差于AT
开发角度
部署代码学习仓库learn-nlp-with-transformers
有两种大模型开发的环境方式,一种是走
WSL+VSCode(linux方式),一种是走PyCharm+Anaconda venv(windows)。比较纠结是基于Windows还是WSL系统进行开发。为了方便自己,先着眼于Windows方案,将Python所需要的所有库都安装在Anaconda venv中,即上面的LLM2虚拟环境。将PyCharm和LLM2解释器结合,在PyCharm中进行代码开发
- 下载仓库:
https://github.com/datawhalechina/learn-nlp-with-transformers.git - 打开PyCharm,open当前仓库作为PyCharm项目
仓库简述
learn-nlp-with-transformers是一个很好的从0到1的代码+讲解仓库,它包含4大篇章,篇章1是前言,篇章2是Transformer原理,篇章3是编写BERT,篇章4是使用Transformers解决NLP任务,从篇章2开始有代码- 每个篇章有多个
md文件,讲述一些原理以及参考文献,有ipynb给出代码交互结果
计划学习方式:利用jupyter打开ipynb文件跟随和理解;利用PyCharm抄袭代码并运行各类test.py
学习篇章2
- Anaconda
- 打开Anaconda Navigator->打开Jupyter Notebook(已经设置默认路径为该仓库目录)
- Jupyter网页打开篇章2的
2.2.1-Pytorch编写Transformer.ipynb - Jupyter在篇章2目录下创建一个新的NoteBook,命名为
2.2.1.ipynb,用于交互式抄袭代码(边抄边理解边验证)
- PyCharm
- Alt+F12打开WSL终端,进入到
篇章2的目录,创建2.py文件 - PyCharm打开
2.py文件,对照Jupyter的网页版理解 - PyCharm打开
test.py文件,用于快速的验证一些代码想法
- Alt+F12打开WSL终端,进入到
代码阅读
- 打开Transformer的图片(没啥说的,太简单)
from IPython.display import Image
Image(filename='pictures/transformer.png')
- 导入一些必要的库
- %matplotlib inline 为IPython的魔法糖,仅在 Jupyter 环境中有效。它可以确保 matplotlib 绘制的图像内嵌在笔记本单元格中。如果您在 PyCharm 或其他 IDE 中运行此代码,应将其删除。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
from torch.autograd import Variable
import matplotlib.pyplot as plt
import seaborn
seaborn.set_context(context="talk")
%matplotlib inline
- 构建一个EncoderDecoder类来搭建一个seq2seq架构
- 这是一个标准的Encoder-Decoder实现
- 包括编码器、解码器、源嵌入(src_embed)、目标嵌入(tgt_embed)和生成器(generator)
- 前向过程
- src进行Embedding:
self.src_embed(src) - 送入到self.encoder:
self.encoder(self.src_embed(src), src_mask) - 再将结果送入到self.decode:
self.decode(self, memory, src_mask, tgt, tgt_mask)- memory: encode的输出,tgt目标,src_mask&tgt_mask
- src进行Embedding:
- src_mask的用途
src_mask(source mask)用于屏蔽输入序列中的填充部分,以确保这些填充部分不会对编码器的计算产生影响。在序列数据处理中,输入序列往往具有不同的长度,为了使批量处理方便,短序列会被填充到相同的长度。这些填充部分没有实际信息,因此在计算时需要屏蔽。 - 自注意力机制中的掩码
在解码器中,每个位置的输出只能依赖于该位置之前的目标序列,而不能依赖于之后的位置。这是通过 tgt_mask 实现的,称为未来信息屏蔽(future masking)。此外,tgt_mask 还用于屏蔽填充部分。
class EncoderDecoder(nn.Module):
"""
基础的Encoder-Decoder结构。
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
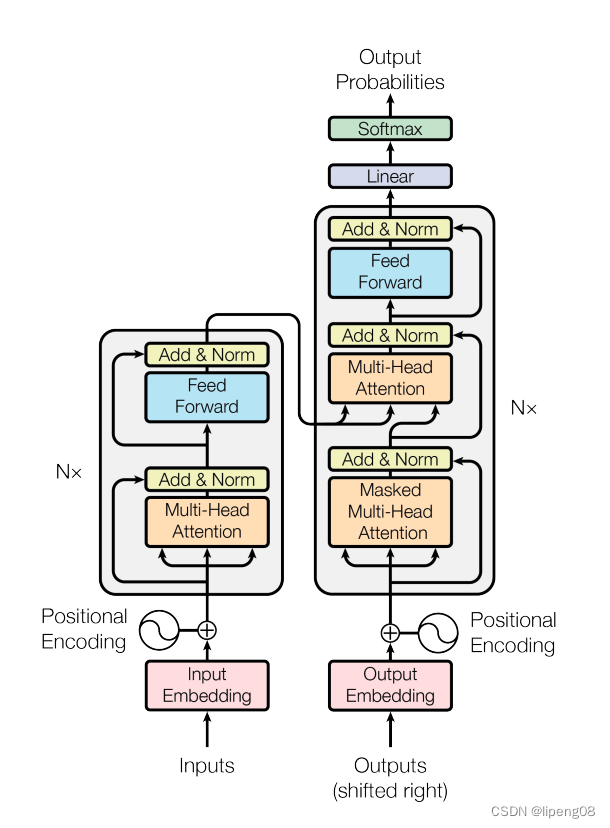
Transformer 经典图
步骤1:词嵌入(Input embedding)
文本切分成句子,句子再进行分词,每个词是不可分割的最小单位(即token)。假设有100个句子,每个句子包含的词的个数不一,为了方便计算机统一处理,假设每个句子包含的最大词个数为128,则该文本的形状为100*128,对应于
batch_size = 100,每批处理的句子数目seq_length = 128,每个句子的序列长度(token词的个数)
词嵌入就是将每个词映射为预先训练好的向量,在torch中通过nn.Embedding(num_embeddings, embedding_dim)来实现,举例来说对于embed = nn.Embedding(10, 8, padding_idx=0) ,参数num_embeddings = 10是词表的总大小(表明一共有10个词,一般会额外空出两个词,用于未知词unknown和不够最大长度的token padding),参数embedding_dim = 8为每个词映射的向量维度,还有一个参数padding_idx为将哪个索引值记录为padding
举一个例子,对于一个句子如何才能学好机器学习,将它分成如何,才能,学好,机器学习这四个词。假设词表一共有2000个词,上述4个词对应于词表的索引位置为[100,353,102,77],每个词映射的维度为8,每个句子的最大长度为128,则该句子生成的Embedding会大概是这样的结构
数组为 128 * 8的维度,每个词映射为一行8维的向量。这个句子只有4个词,对应下述矩阵的前4行,其余124行向量使用`0`进行填充
[
[ 0.7253, -0.3269, -0.6069, -0.2106, 1.5338, 0.9302, -0.4297, -0.7969], // 100
[ 0.7125, -0.8481, 0.8173, 0.4928, -0.2031, 0.4463, 1.7939, -0.0178], // 353
[-1.3572, 0.0253, -0.9361, 1.2825, 0.4064, -0.5263, 1.0806, -0.6430], // 102
[-1.1791, 0.3731, 0.1252, 0.3940, 0.5179, -2.1997, -1.4458, -1.2021], // 77
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000], // 0
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000], // 0
...... // 0
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000], // 0
]
上述例子中词嵌入的demo代码实现
import torch
import torch.nn as nn
# 实例化 nn.Embedding,并指定 padding_idx
embed = nn.Embedding(2000, 8, padding_idx=0) # padding_idx=0 指定索引0用于填充
# 示例输入,包含填充位置
input_indices = torch.tensor([
[100,353,102,77, 0, 0, 0, ..., 0], # 序列1,填充索引为0
)
# 获取词嵌入向量
output_vectors = embed(input_indices)
print(output_vectors)
困惑点
- 每个词向量通过nn.Embedding获得,初始获得的向量应该不具有任何其表达语义才对吧?
- 这个初始向量会不断被迭代?
步骤2:位置编码(Positional Encoding)
在传统的序列模型(如RNN和LSTM)中,序列元素的位置是通过模型的递归结构自然捕获的。而在Transformer中,所有的输入都被同时处理,缺乏自然的位置信息。因此,需要通过位置编码显式地将位置信息注入到输入中,使模型能够区分序列中不同位置的元素。
在位置编码(Positional Encoding)中,pe 是一个二维张量,它存储了所有位置的编码信息。pe 的维度是 (max_len, embedding_dim),其中max_len为句子的最大序列长度,embedding_dim为每个词向量的维度,对应于前文的(128, 8)。pe(i,j)代表第i个位置在第j个维度的编码值,以确保不同位置的编码在不同维度上具有唯一性
以如何才能学好机器学习为例,对于学好这个词,它在句子中是第2个位置(如何是0,才能是1,学好是2,机器学习是3),该词的位置信息为pe矩阵的第2行。如何的位置编码是将前面得到的embedding向量和这里得到位置向量逐个元素相加。
位置编码当前使用的正余弦函数来计算的
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
100
0
2
i
e
m
b
e
d
d
i
n
g
_
d
i
m
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
100
0
2
i
+
1
e
m
b
e
d
d
i
n
g
_
d
i
m
)
\begin{gather*} PE(pos, 2i) &= sin(\frac{pos}{1000^\frac{2i}{embedding\_dim}}) \\ PE(pos, 2i+1) &= cos(\frac{pos}{1000^\frac{2i+1}{embedding\_dim}}) \end{gather*}
PE(pos,2i)PE(pos,2i+1)=sin(1000embedding_dim2ipos)=cos(1000embedding_dim2i+1pos)
这里的pos为一个词的位置索引,2i和2i+1的意思是偶数的维度和奇数的维度使用的正余弦计算公式。
困惑点
- 位置编码的计算公式感觉很随意的,有什么特别的含义吗?
- 为何使用正弦和余弦呢?有其它的计算方法吗?
位置编码的demo代码实现
# 获取词嵌入向量
embedded_input = embedding(input_indices_tensor)
# 定义位置编码类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建一个 max_len x d_model 的位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
# 将位置编码添加到输入张量中
x = x + self.pe[:x.size(0), :]
return x
# 创建位置编码实例
pos_encoder = PositionalEncoding(8, max_len=128)
# 应用位置编码
embedded_with_pos = pos_encoder(embedded_input.unsqueeze(1)).squeeze(1)
# 打印结果
print("词嵌入向量:\n", embedded_input)
print("位置编码后的嵌入向量:\n", embedded_with_pos)
Decoder中的mask机制
在Decoder阶段,防止当前位置看到其后面的位置。在目标序列生成阶段,该机制很重要,因为模型在第i个位置的输出不应该看到i之后的的位置,即生成的每个单词都只关注它之前已经生成的词,而不应该关注它之后的词。如何达到此目标,可以使用一个掩码矩阵来对相应的元素进行掩盖,相当于告知模型哪些位置被掩盖不需要关注,下面的代码示例了如何生成这个掩码矩阵。
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
如果输入的size为5,则输出的结果为一个True的下三角矩阵
tensor([[[ True, False, False, False, False],
[ True, True, False, False, False],
[ True, True, True, False, False],
[ True, True, True, True, False],
[ True, True, True, True, True]]])
它表明对于第一个词,只需要关注自己;对于第4个词,关注它和之前的三个词
体验本地大模型
安装ollama
ollama可以方便进行模型的验证工作,其地址:
https://ollama.com/download
- WSL安装
- 命令
curl -fsSL https://ollama.com/install.sh | sh下载 - 下载速度太慢,放在后台下了几个小时,使用的VPN也没啥加速效果
- 命令
- Windows安装
- Windows下的exe包下载超快,几十秒就下完了。
- 启动ollama
- 双击ollma应用,ollama即可启动,使用链接
127.0.0.1:11434打开可以看到Ollama is running的显示
- 双击ollma应用,ollama即可启动,使用链接
安装Docker Desktop
为了使用类似于CPT方式来体验ollama本地模型,我们可以安装相应的配套界面工具OpenWebUI。OpenWebUI是一个简单的web服务,它支持设置不同的模型,并提供一个友好的问答页面并将各种问题请求转发给ollama服务。安装OpenWebUI有一种最简单的方案,使用Docker镜像。于是,我们先安装Docker来为OpenWebUI铺路
- 安装Docker Desktop,微软出的同时适用于Windows和WSL,
https://learn.microsoft.com/zh-cn/windows/wsl/tutorials/wsl-containers,我使用的github账户登录 - WSL命令行输入
docker --version确认安装成功- 输入
docker run hello-world运行内置镜像
- 输入
- DockerDesktop的界面
- 当前在运行的containers,本地的镜像列表,以及远端的hub
- 当使用
docker run特定的image的时候,会将相应的image自动pull下来,进而可以在Images->Local看到
- Docker图形界面-Images
- Docker图形界面-Containers
- 可以看到容器列表,以及是否正在运行
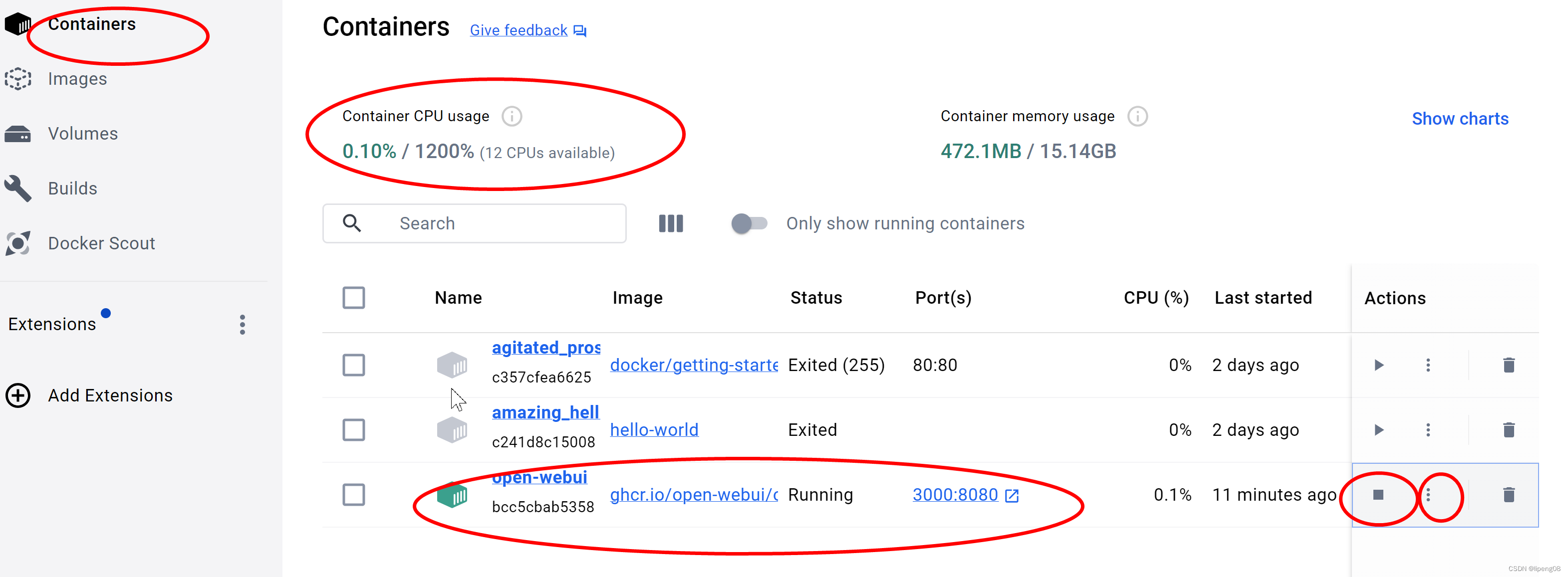
- 可以看到容器列表,以及是否正在运行
其它简单的docker命令行
docker ps -a:查看运行过的容器docker images:列出所有的镜像docker push {DOCKER_ACCOUNT_NAME}/ghcr.io/open-webui/open-webui:latest:将本地的镜像推送到远端账户docker pull ghcr.io/open-webui/open-webui:拉取open-webui镜像到本地docker tag docker/ghcr.io/open-webui/open-webui {DOCKER_ACCOUNT_NAME}/open-webui:将本地容器打一个带账户名的tag,这样才能push到远端docker hub- 进入到容器内部Terminal(也可以通过Desktop界面进入)
- 使用命令
docker exec -it 容器ID /bin/bash docker exec -it bcc5cbab5358 /bin/bash
- 使用命令
安装OpenWebUI
OpenWebUI是一个开源的Web界面,它允许用户通过浏览器来访问和控制Ollama。最简单的模式是通过docker启动webui来和ollama通信。为了更好的理解docker,这次我们使用docker来安装openwebui。
- docker的安装请参考下面的安装
docker in WSL,使用的微软出的Docker Desktop,有界面同时适配Windows和WSL,非常方便。 - 启动webui:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main-d: 将容器以分离(detached)模式运行,即在后台运行。- -p 3000:8080: 将主机的端口 3000 映射到容器的端口 8080。这意味着当访问主机的 3000 端口时,实际上是访问容器内的 8080 端口。
- –add-host=host.docker.internal:host-gateway: 添加一个名为 host.docker.internal 的主机条目到容器的 /etc/hosts 文件中,并将其 IP 地址设置为 Docker 主机的网关地址。这通常用于让容器能够通过 host.docker.internal 访问主机服务。
-v open-webui:/app/backend/data: 将名为 open-webui 的 Docker 卷挂载到容器内的 /app/backend/data 目录。这用于持久化数据,即使容器删除数据也不会丢失。--name open-webui: 为容器指定一个名称 open-webui。这使得可以通过名称而不是容器 ID 来引用容器。
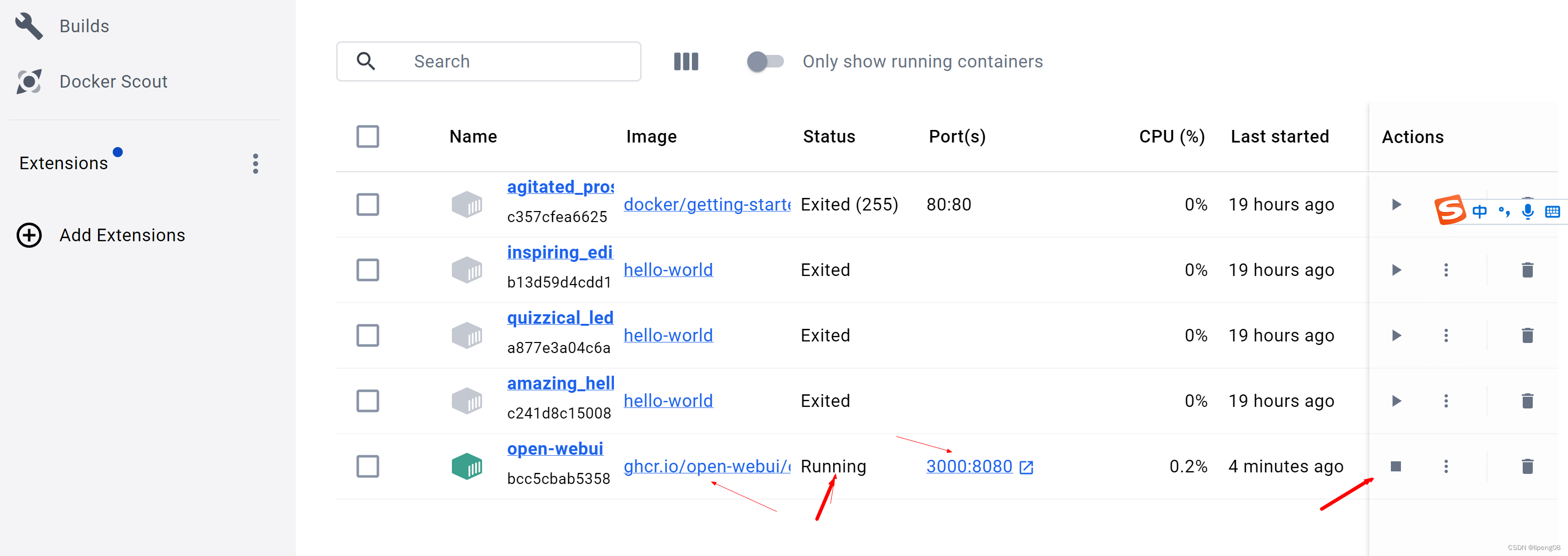
- 查看webui是否启动
- 使用命令
docker ps -a可以看到ghcr.io/open-webui/open-webui:main正在运行 - 也可以通过
DockerDesktop来查看该进程
- 使用命令
- OpenWebUi是如何和Ollama服务交互
- webui docker启动的端口映射是3000:8080,即外部端口3000映射到内部的8080,因此我们才可以从
localhost:3000/访问到WebUI的内部8080端口 - 进入到容器内部:
curl http://localhost:8080/health可以正常返回{"status":true} - 8080转发到ollama的11434
- /app/backend/config.py中配置
OLLAMA_BASE_URL = "http://host.docker.internal:11434" - 依赖启动参数
--add-host=host.docker.internal:host-gateway,这允许容器内的服务通过host.docker.internal访问主机上的服务。 curl http://host.docker.internal:11434可以正常返回Ollama is running- 容器启动
start.sh,它启动uvicorn进程,监听的是8080端口,该API服务又将请求转发给容器外部的ollama 11434服务端口
- /app/backend/config.py中配置
- webui docker启动的端口映射是3000:8080,即外部端口3000映射到内部的8080,因此我们才可以从
体验本地大模型
命令行体验
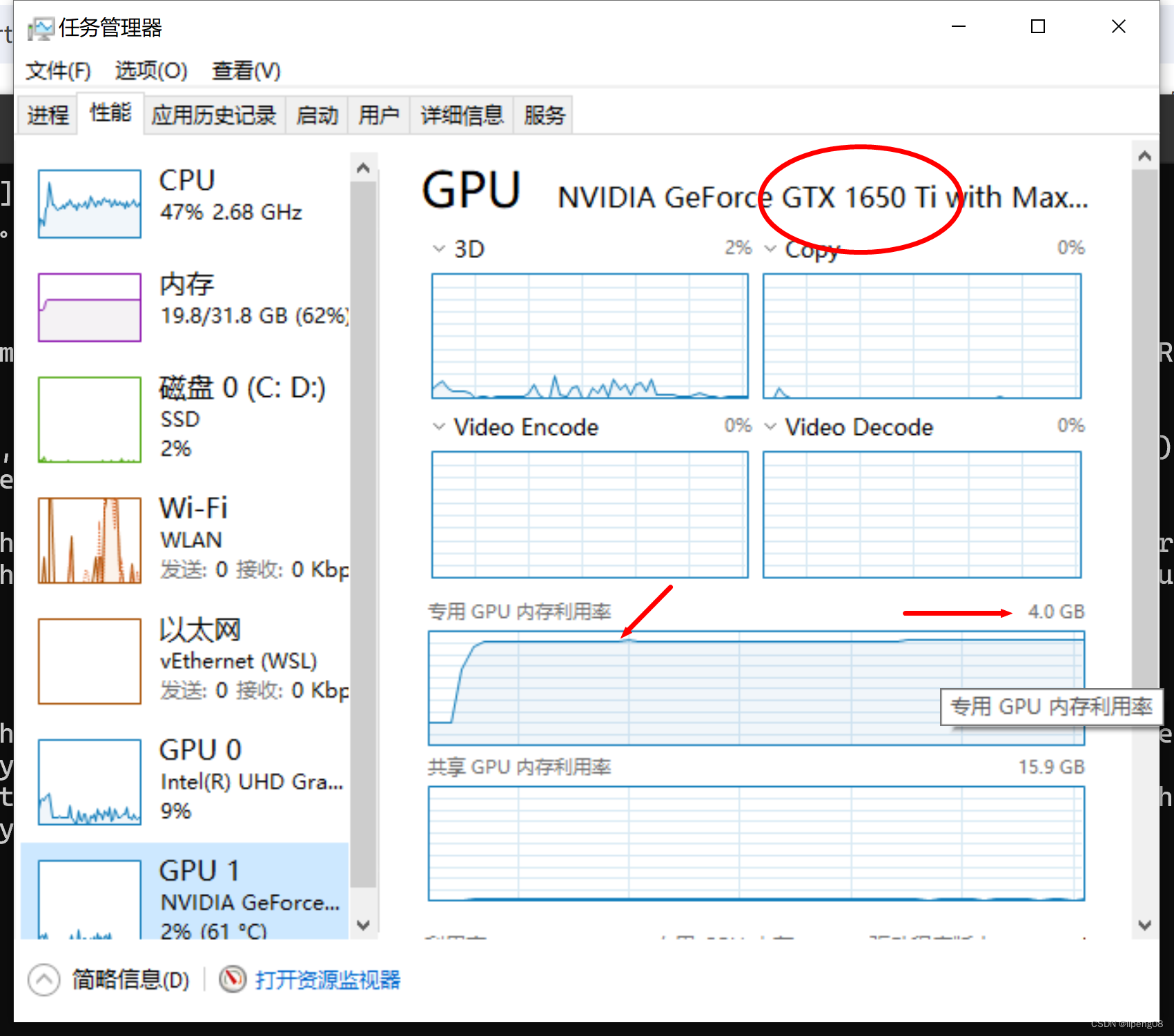
ollama run llama3启动llama3的8b,如果是第一次启动,会自动下载llama3的8B模型,并启动- llama3的8B模型对应的显存:80亿*0.5字节 = 4GB(略小于4GB,1024和1000导致的)
- 8B: 80亿参数
- Q4:代表每个参数使用4bit
- 笔记本的显卡是1650Ti,它的显存是4GB
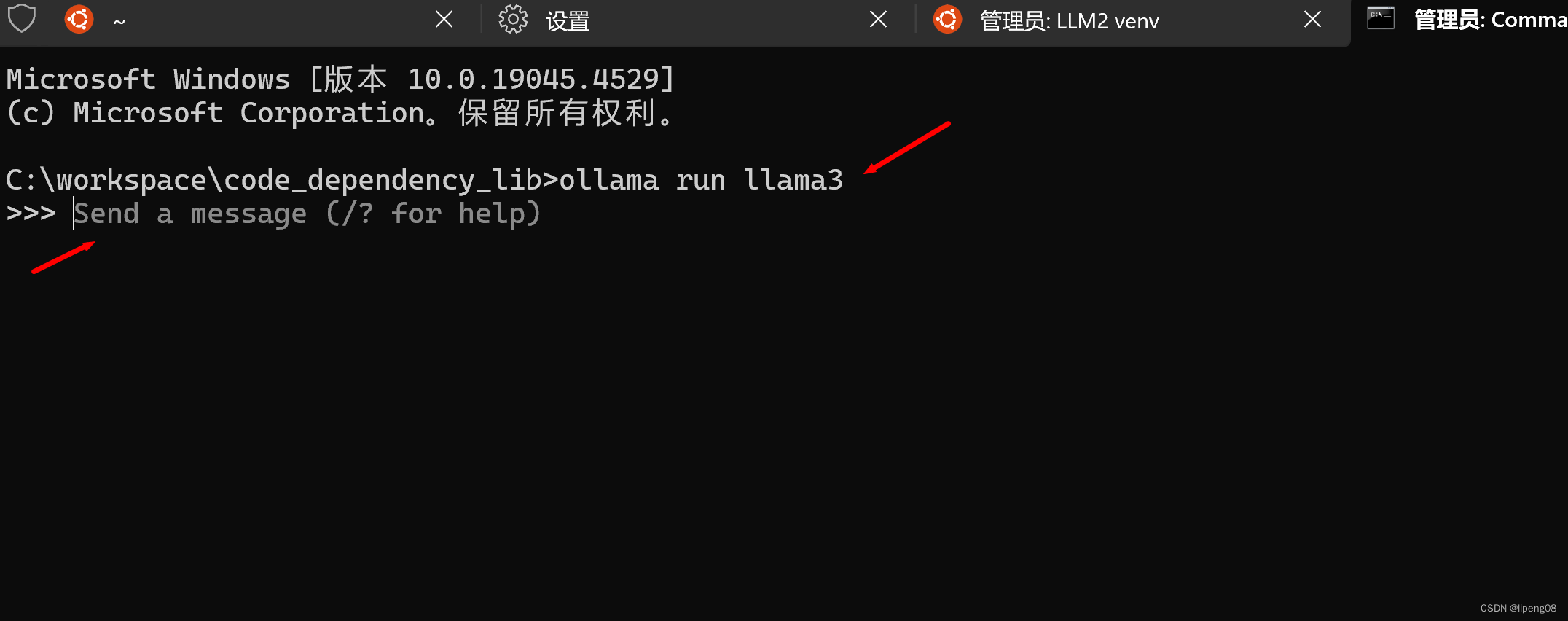
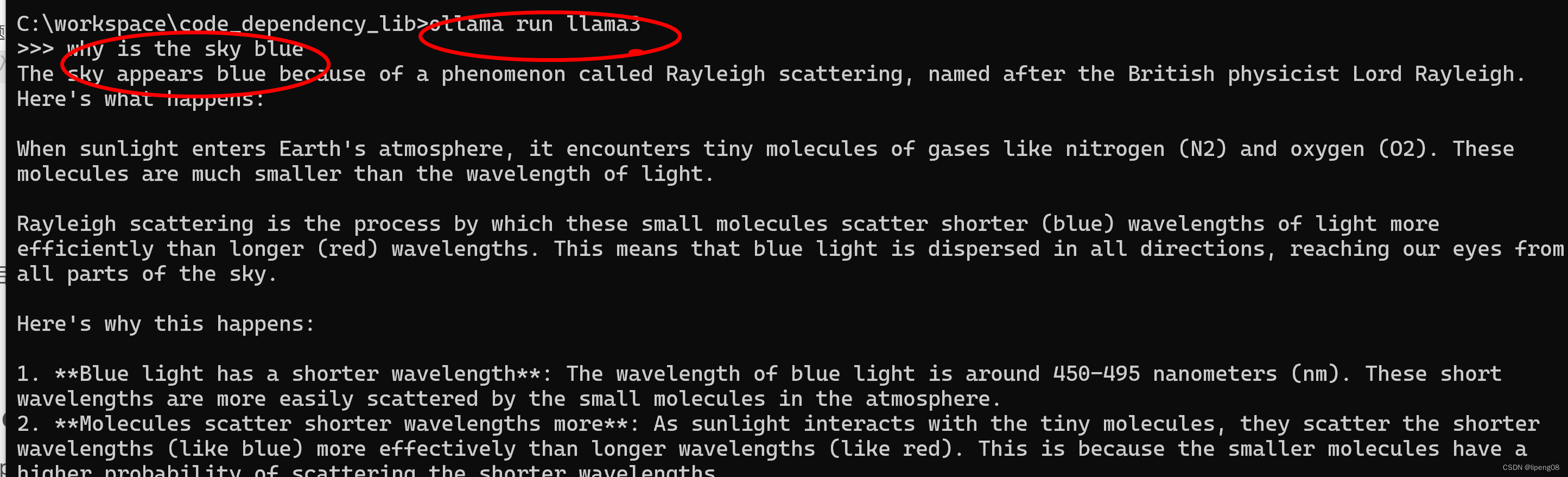
运行一个问答why is the sky blue,查看其资源占用,以及token产生速率
- 显卡和CPU
- 输出
- verbose启动:
ollama run llama3 --verbose
进行查询的时候,可以得到它的token输出速率,每秒3.25个token

问题 - 在评估期间,为何GPU利用率不高,而CPU利用率高,是否GPU在进行有效的评估?
界面体验
启动OpenWebUI的容器,打开其docker的链接:http://localhost:3000/,第一次打开会要求注册,因为是本地版本,直接随便填一些内容即可完成注册
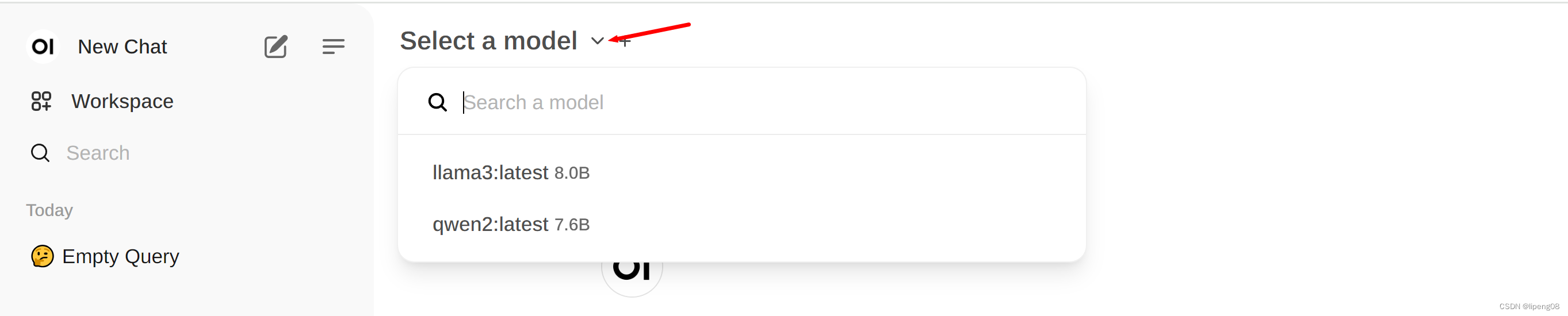
- 点开
Select a model,来选择一个模型,默认为空。我这边已经下载llama3以及qwen2的模型,所以会显示这两个模型,可以直接输入llama3进行搜索,即可下载llama3的默认8B模型
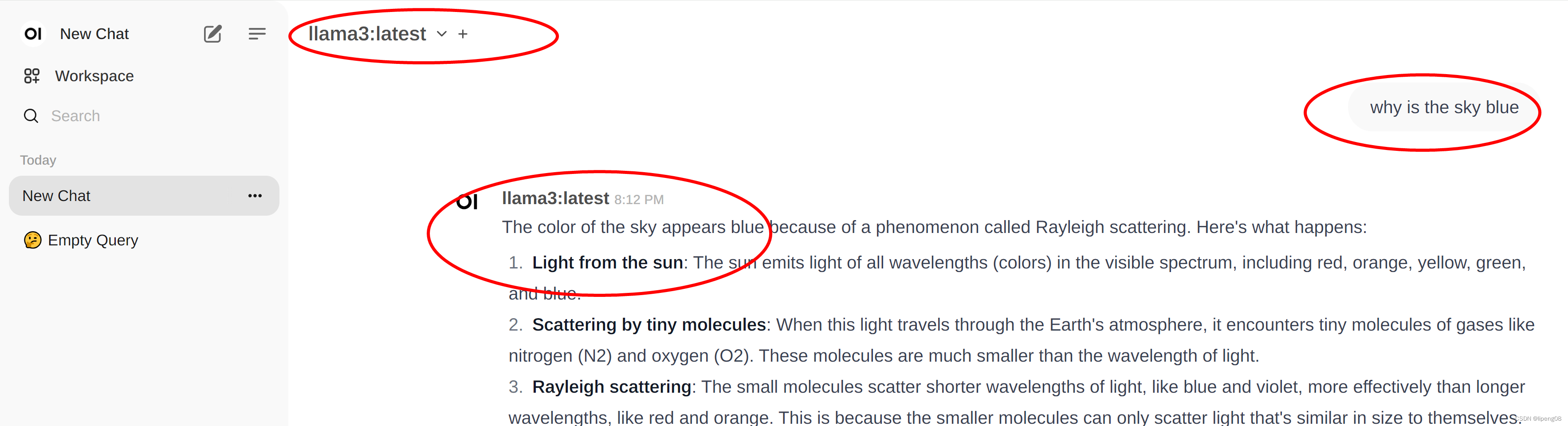
- 选择完毕模型后,即可进行问答,会有PT样式感觉的交互和输出
了解Docker
- 教程:https://dockerdocs.cn/get-started/index.html
- 运行`docker run -d -p 80:80 docker/getting-started
- `-d -以分离模式运行容器(在后台)
- -p 80:80 -将主机的端口80映射到容器中的端口80
- docker/getting-started 要使用的图像
DockerDesktop通过WSL2启动,会自动创建2个子系统,分别对应2个 vhdx 硬盘映像文件
C:\Users\Admin\AppData\Local\Docker\wsl目录下有data和main两个镜像文件ext4.vhd
- data对应于docker-desktop-data
- main对应于docker-desktop
- 使用
wsl.exe --list -v可以查看当前运行的docker子系统
镜像上传
- 显示当前镜像:
docker image ls - 拉取镜像:
docker image pull hello-world - docker push image到远端hub
- 在DockerDescktop页面对images镜像点击push会报告
errors: denied: requested access to the resource is denied unauthorized: authentication required - 重命名镜像:
docker tag docker/welcome-to-docker 你的用户名/welcome-to-docker - 再次push镜像(界面或者命令行),即可从自己的账户中看到docker镜像
- 命令行方式
docker push 你的用户名/welcome-to-docker - docker tag ghcr.io/open-webui/open-webui:latest 你的用户名/open-webui:latest
docker push 你的用户名/open-webui:latest
- 命令行方式
- https://cmakkaya.medium.com/docker-desktop-4-docker-hub-authorization-for-docker-desktop-and-pushing-a-image-from-docker-c2babb61a559
- 在DockerDescktop页面对images镜像点击push会报告
安装go
- WSL中
apt-get install golang-1.18安装go1.8 - 配置环境变量:
/usr/lib/go-1.18/bin - 将这些内容保存到.profile和.zshrc中,不能只保存在.zshrc中
export GOROOT=/usr/lib/go-1.18
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin:$GOROOT/bin
- 打开VSCode,使用命令
code .打开WSL vscode - 安装插件 go
- 安装插件 gopls:go install -v golang.org/x/tools/gopls@latest
- 10+左右的插件
- 创建一个hello的go文件,可以实现提示和自动补全















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









