






关于环境部署请参考: https://blog.csdn.net/lpstudy/article/details/139691642
背景
上一篇文章主要讲了环境部署相关的,其篇幅越来越长。考虑到阅读的方便,将里面涉及到Transformer相关的内容摘取出来,另开一篇文章来好好讲述下小白视角学习Transformer的过程。
本人目的是想在短时间内了解Transformer是如何工作的,学习的资料来源主要有视频、博客和论文。其实对于想进行内部深挖的人来说,系统的看一些书是最好的,我没有太多的时间,只选择精华的东西吞一吞,了解一下。
序列模型
视频课程: https://www.youtube.com/watch?v=pFIzLJfzSJM&list=PLBGvQkBc2Hq_xInrqZ5Vang22P0ceqpNY&index=55
在时间
t
t
t观察到
x
t
x_t
xt,那么可以得到
t
t
t个不独立的随机变量
p
(
X
)
=
p
(
x
1
)
∗
p
(
x
2
∣
x
1
)
∗
p
(
x
3
∣
x
1
,
x
2
)
∗
.
.
.
∗
p
(
x
t
∣
x
1
,
.
.
.
,
x
t
−
1
)
p(X) = p(x_1) * p(x_2|x_1) * p(x_3|x_1,x_2) * ... * p(x_t|x_1,...,x_{t-1})
p(X)=p(x1)∗p(x2∣x1)∗p(x3∣x1,x2)∗...∗p(xt∣x1,...,xt−1)。基于历史数据,即对见过的数据建模,也叫自回归模型
p
(
x
t
∣
x
1
,
.
.
.
,
x
t
−
1
)
=
p
(
x
t
∣
f
(
x
1
,
.
.
.
,
x
t
−
1
)
p(x_t|x_1,...,x_{t-1} ) = p(x_t|f(x_1,...,x_{t-1})
p(xt∣x1,...,xt−1)=p(xt∣f(x1,...,xt−1)
方案1:马尔科夫模型
- 假设 x t x_t xt只跟过去 m m m个数据相关。比如股票预测一般我们只看最近时间的数据,不怎么看几年前的数据
- 可以构建一个MLP来进行处理,对 p ( x t ∣ x 1 , . . . , x t − 1 ) = p ( x t ∣ f ( x t − m , . . . , x t − 1 ) ) p(x_t|x_1,...,x_{t-1} ) = p(x_t|f(x_{t-m}, ..., x_{t-1})) p(xt∣x1,...,xt−1)=p(xt∣f(xt−m,...,xt−1))进行建模
方案2:潜变量模型
- 引入潜变量 h t h_t ht来表示过去的信息 h t = f ( x 1 , . . . , x t − 1 ) h_t = f(x_1,...,x_{t-1}) ht=f(x1,...,xt−1),训练两个模型:
- 根据历史的数据更新潜变量: h t = f ( x 1 , . . . , x t − 1 ) h_t = f(x_1,...,x_{t-1}) ht=f(x1,...,xt−1)
- 根据潜变量也更新当前数据: x t = p ( x t ∣ h t ) x_t = p(x_t | h_t) xt=p(xt∣ht)
序列模型总结
- 时序模型中,当前数据跟之前观察到的数据相关
- 自回归模型是用过去的数据来预测未来
- 马尔科夫模型假设当前只跟最近的少数相关,简化模型
- 潜变量模型是用潜变量来概括历史信息
语言模型
- 给定文本序列 x 1 , . . . , x t x_1, ..., x_t x1,...,xt,语言模型的目标是估计联合概率 p ( x 1 , . . . x t ) p(x_1,...x_t) p(x1,...xt)
- 应用场景
- 预训练模型:BERT,GPT-3
- 生成文本,给定前面几个词,不断使用 x t p ( x t ∣ x 1 , . . . , x t − 1 ) x_t ~ p(x_t|x_1, ..., x_{t-1}) xt p(xt∣x1,...,xt−1)来生成后续文本
- 判断哪个序列更常见,例如打字根据拼音生成更匹配的汉子
编码器和解码器
- 编码器:将输入数据编码乘中间表达形式,即特征抽取
- 解码器:将中间表示解码成期望输出
- 以CNN为例,前面的很多层看作编码器进行特征抽取,最后的输出softmax层(分类器)看作解码器。
- 以RNN为例,前面的Embedding+LSTM可以看作编码器,最后的Dense层可以看作解码器
使用计数来建模
- 假设序列长度为2,我们预测
p ( x 1 , x 2 ) = p ( x 1 ) ∗ p ( x 2 ∣ x 1 ) = n ( x 1 ) n ∗ n ( x 1 , x 2 ) n ( x 1 ) p(x_1, x_2) = p(x_1) * p(x_2|x_1) = \frac{n(x_1)}{n} * \frac{n(x_1,x_2)}{n(x_1)} p(x1,x2)=p(x1)∗p(x2∣x1)=nn(x1)∗n(x1)n(x1,x2) - 即 x 1 , x 2 x_1,x_2 x1,x2同时出现的概率就是它们出现的次数除以单词总个数
- 使用马尔科夫假设可以处理任意长的序列,假设一个词只和前面N个词有关系,这叫做N元语法,二元语法和三元语法用的比较多(两个词或者三个词有关联)
Seqseq
-
编码器是RNN,读取输入句子
- 可以是双向的,因为输入时已知的
-
解码器使用另外一个RNN来输出,只能单向
-
如何连接
- 编码器是没有输出的RNN,最后时间步的隐状态作为解码器的初始隐状态
-
训练:训练时解码器使用目标句子作为输入
-
推理:上一个的输出作为下一个的输入
BLEU
- 衡量预测序列和真实序列匹配程度的值,它越大越好。
- 定义
e x p ( min ( 0 , 1 − L e n ( l a b e l ) L e n ( p r e d ) ) ) ∗ ∏ n = 1 k p n 1 / 2 n exp(\min(0, 1-\frac{Len(label)}{Len(pred)})) * \prod \limits_{n=1}^{k} p_n^{1/{2^n}} exp(min(0,1−Len(pred)Len(label)))∗n=1∏kpn1/2n
这里, L e n ( l a b e l ) Len(label) Len(label)为标签的长度, L e n ( p r e d ) Len(pred) Len(pred)为预测的序列长度, p n p_n pn表达预测序列中连续 n n n个单词在标签序列中匹配的比例。以实际标签序列 ABCDEF和预测序列ABBCD为例,有 p 1 = 4 / 5 , p 2 = 3 / 4 , p 3 = 1 / 3 , p 4 = 0 p_1 = 4/5, p_2=3/4, p_3=1/3, p_4=0 p1=4/5,p2=3/4,p3=1/3,p4=0,这里的 p 2 p_2 p2的计算逻辑如下:预测序列一共有4个连续2个单词的序列,即 A B , B B , B C , C D AB,BB,BC,CD AB,BB,BC,CD,其中有三个序列 A B , B C , C D AB,BC,CD AB,BC,CD在标签序列中可以找到,故而为 p 2 = 3 / 4 p_2 = 3/4 p2=3/4
公式的左半部分是用来惩罚过短的序列,在 L e n ( p r e d ) Len(pred) Len(pred)非常小时, m i n min min函数是个负值,用来拉低左边的结果;公式的右半部分是用来拉高更长匹配的权重,因为 p n 1 / 2 n p_n ^ {1/2^n} pn1/2n在 n n n越大的时候,其值越大,这样更长的匹配的权重值更大。
理论角度
通过看视频教程,论文以及博客等相关内容,增加自己对大模型的理论理解,将理解的内容缩小下呈现到本文档中。台大的李宏毅Transformer视频教程:
https://www.youtube.com/watch?v=n9TlOhRjYoc
Seq2Seq的应用场景
很多现实的需求都可以看作是QA的问题,可以通过seq2seq模型来解决,举例如下:
- 从英文翻译到德文:这段英文的德文是什么
- 文章总结:这段文字的摘要是什么?
- 文章情感属性:这段文字是否是积极的态度?
这些都可以归类为Question, context -> Seq2Seq -> Anser。不过要注意的是虽然Seq2seq可用来解决很多通用问题,但对各式各样的任务使用特质化的模型往往可以表现得更好
Seq2seq的应用领域
- Seq2seq for 文法解析
- 给一句话,生成一个文法树
- deep learning is very powerful -> (S (NP deep learning) (VP is) (ADJV very powerful) ) )
- Seq2seq for multi-label 分类
- 一个对象可以隶属于多个类别,每个文章对应的类别数目都可能是不一样的
- 输入一篇文章,输出class数组,由机器决定输出多少个类别
- Seq2seq for Object Dection
- https://arxiv.org/abs/2005.12872
Seq2seq模型
将输入序列经过编码器和解码器得到相应的输出,即input sequence -> Encoder -> Decoder -> output sequence,相关论文如下:
- Sequence to Sequence Learning with Neural Networks: arx1409.3215,最早2014年
- Attention is All you need: Transformer, arx1706.03762,最早2017年
Encoder & Decoder
- Nx:表明重复N次,即网络分为多层Block
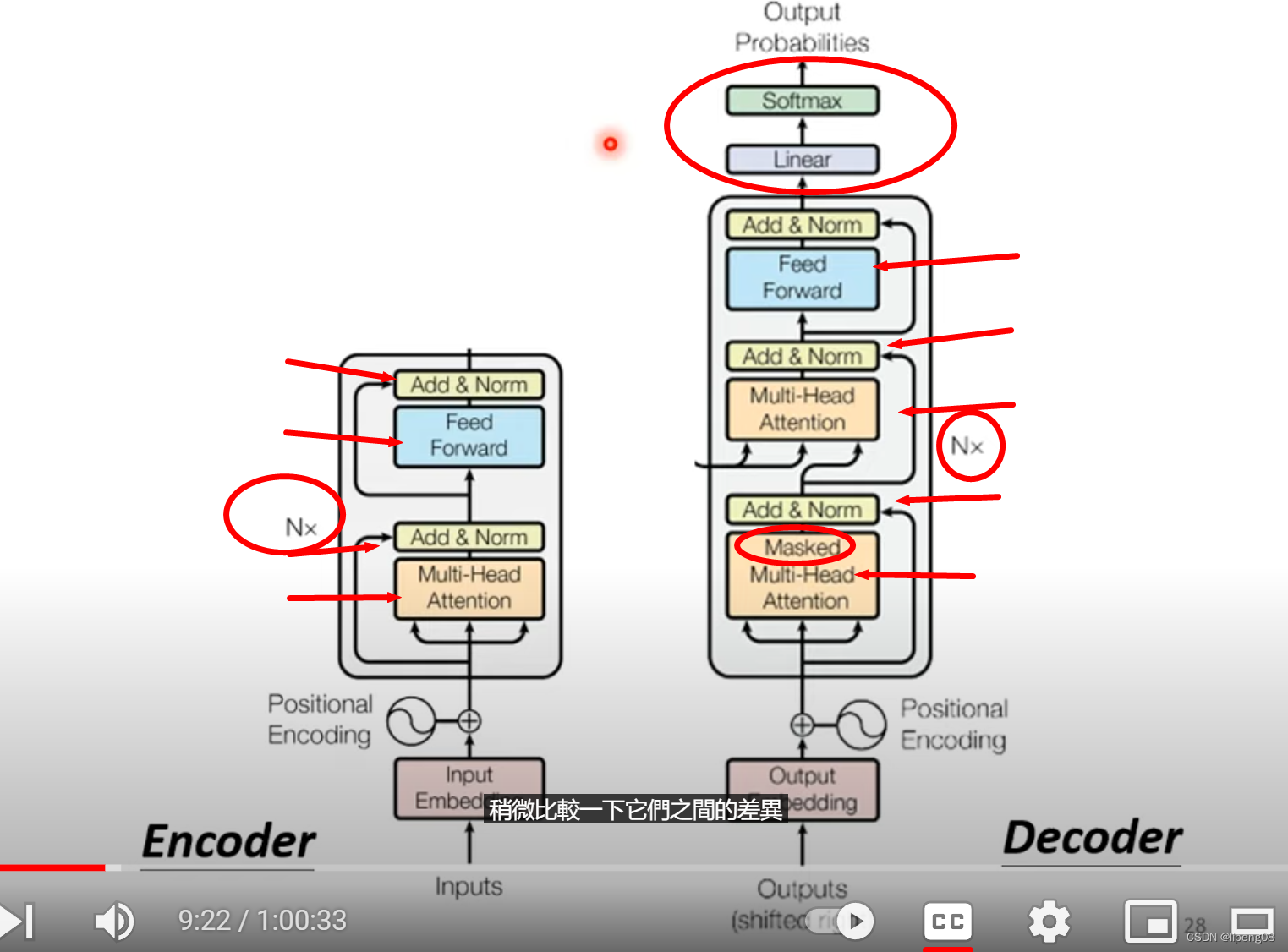
Encoder
李宏毅视频: https://www.youtube.com/watch?v=n9TlOhRjYoc
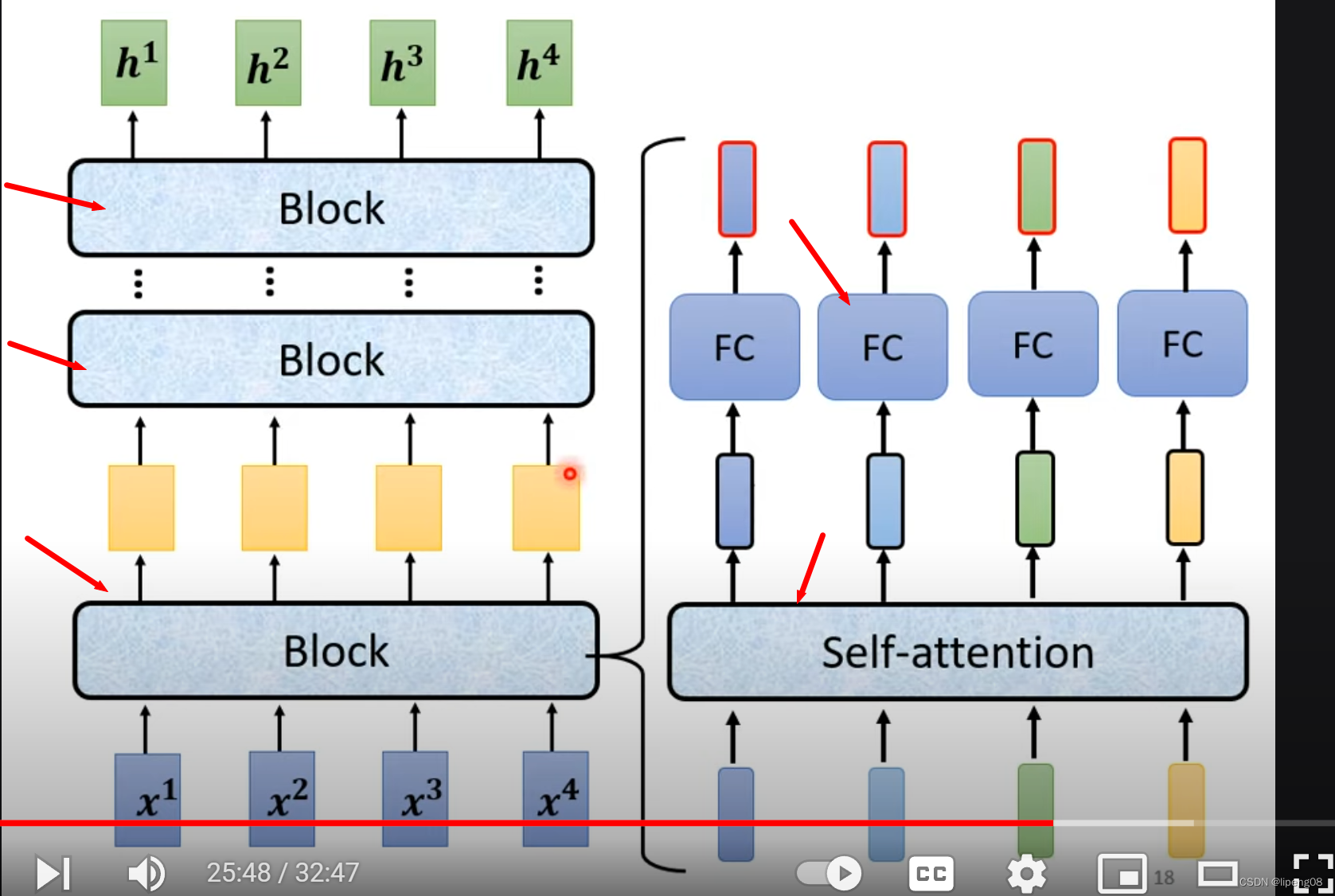
输入一排向量 经过Encoder, 输出一排向量。Encoder本身是由多层网络Block构成,每层Block又是Attention和FC(Full connected)的组合,如下图:
单个Block层
如下图,左边输入b经过Self-attention得到输出a,该输出a和 输入b相加,得到residuala+b,它继续传递到Layer Norm层归一化(LayerNorm对同一个example里面不同的dimension计算mean和sigma,比较特别),随后它的输出才会左边,即FC层,并同样使用residual,最后输出到新的norm层,这是一个完整的Bock层
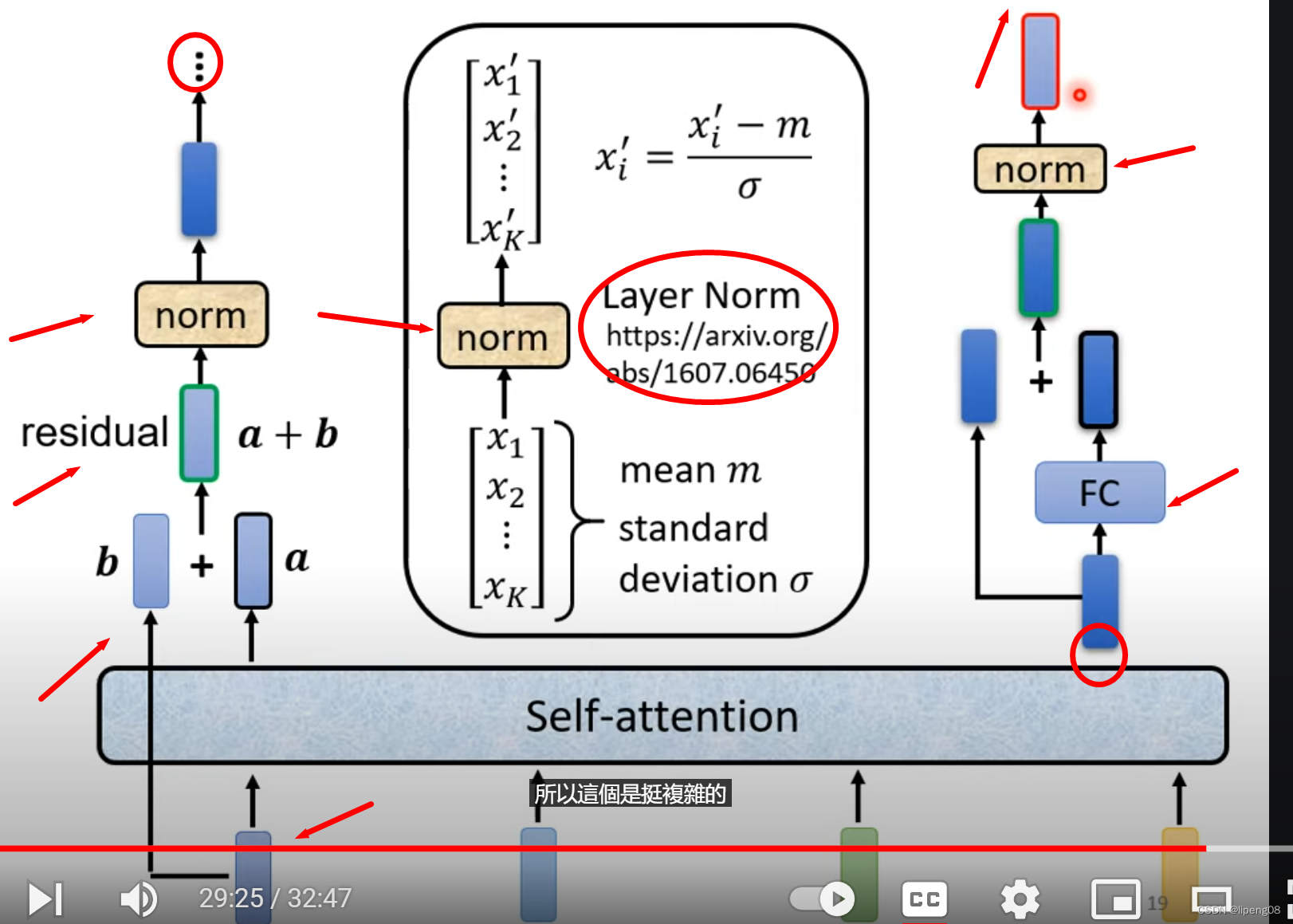
Encoder快速总结
输入 -> MultiHead Attention -> Residual + Layer Norm -> FC -> Residual + Layer Norm -> 上述网络重复N遍 -> 输出
问题
- Residual的价值
Decoder
李宏毅视频: https://www.youtube.com/watch?v=N6aRv06iv2g
不同的模型的输出单位:中文使用的字,英文可以使用word,subword或者字母。BEGIN是一个特殊符号,BEGIN输入之后经过Decoder+Softmax,得到所有token中概率最大的那个token,例如是机,然后将机作为下一个token的输入,继续经过Decoder+Softmax,直到整个序列处理完毕。
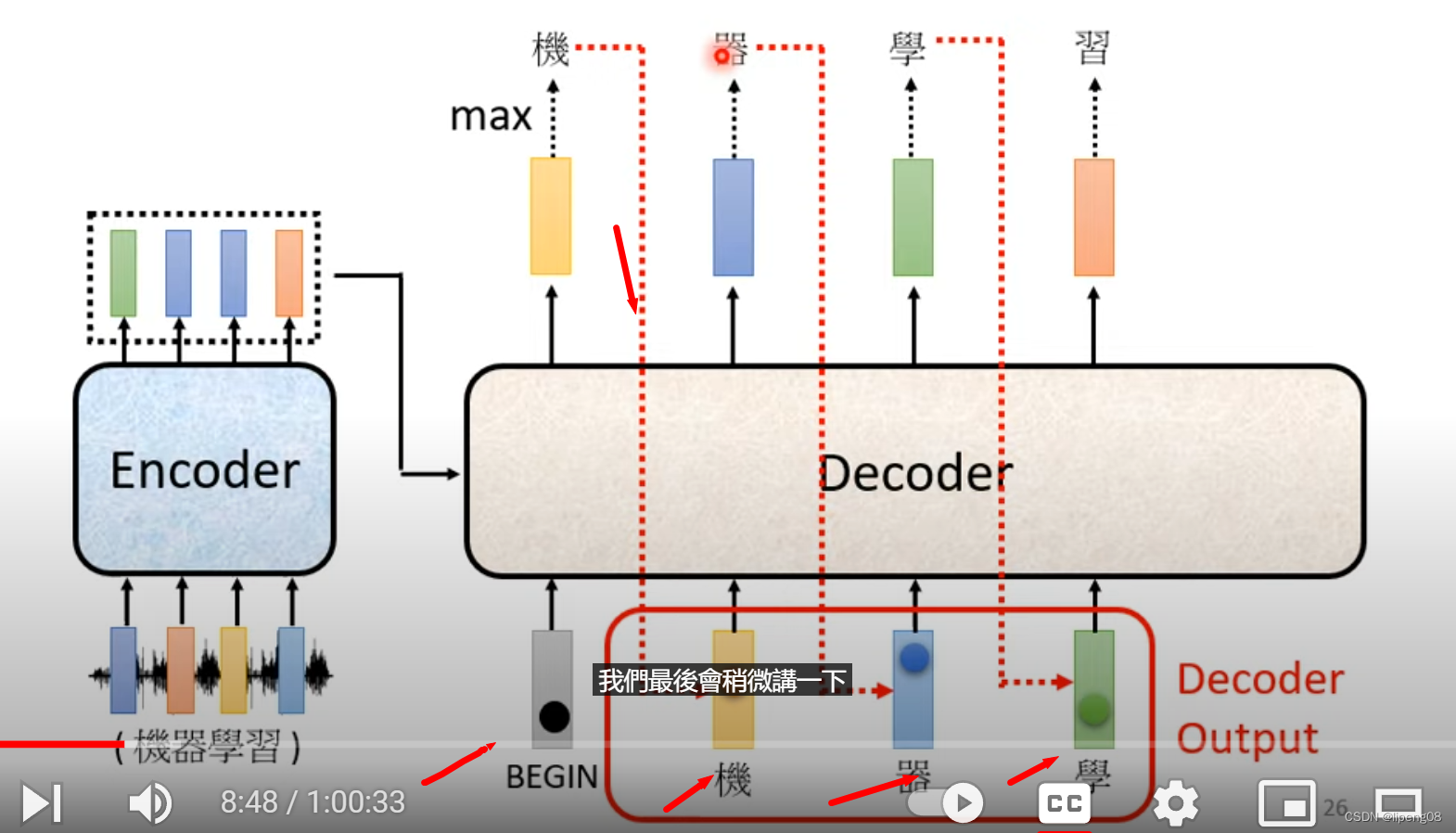
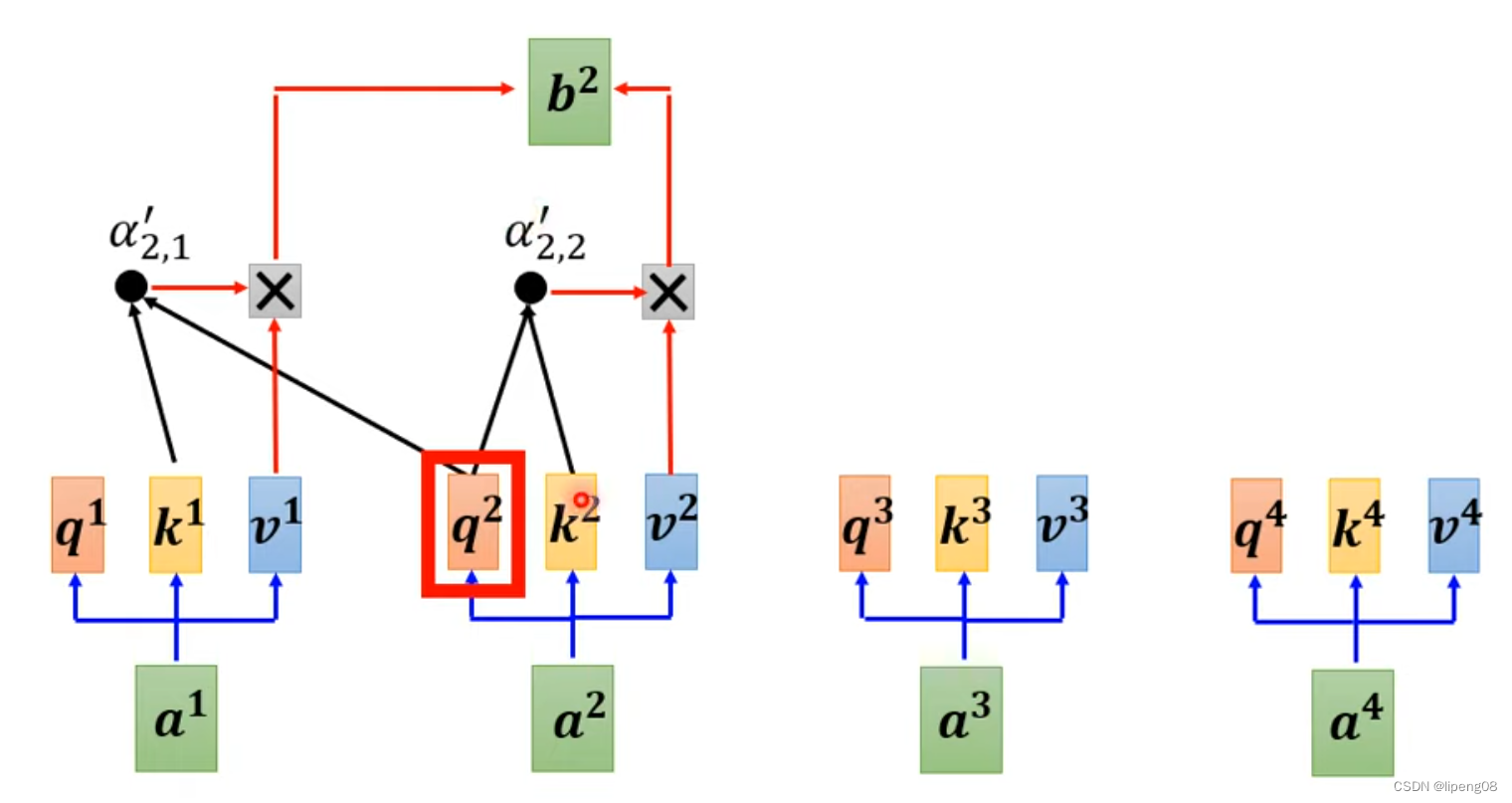
Decoder Attention层
Decoder里面的Attention叫Masked Self Attention,指的是产生b2的时候,只能看a1、a2这几个,不能考虑a3或者a4。为什么需要masked,这是因为Decoder的输出token是逐个产生的,先有a1,a2,才能有a3,a4等。那什么时候停止输出token呢,即END成为概率最大的Token时。
AutoRegression()
AT Decoder:逐个字产生,上一个token的输出作为这个token的输入
NAT Decoder:一组BEGIN作为输入,同时产生多个token输出,并行度好,但是性能差于AT















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









