






 文章介绍了知识图谱在药物发现中的应用,包括药物再利用和药物不良反应预测。它探讨了几种知识表示学习方法,如翻译模型、张量分解和神经网络模型,并强调了图神经网络在捕获实体间关系的重要性。文章还指出,构建高质量的生物医学知识图谱、设计可解释的预测模型以及优化预测策略是未来的关键挑战和发展方向。
文章介绍了知识图谱在药物发现中的应用,包括药物再利用和药物不良反应预测。它探讨了几种知识表示学习方法,如翻译模型、张量分解和神经网络模型,并强调了图神经网络在捕获实体间关系的重要性。文章还指出,构建高质量的生物医学知识图谱、设计可解释的预测模型以及优化预测策略是未来的关键挑战和发展方向。
文章概述
- 关键词:药物发现、知识图谱、药物再利用、药物不良反应预测
- 由于知识表示学习是探索预测问题知识图的常用方法,我们引入了几个具有代表性的嵌入模型,以提供对知识表示学习的全面理解。
文章内容
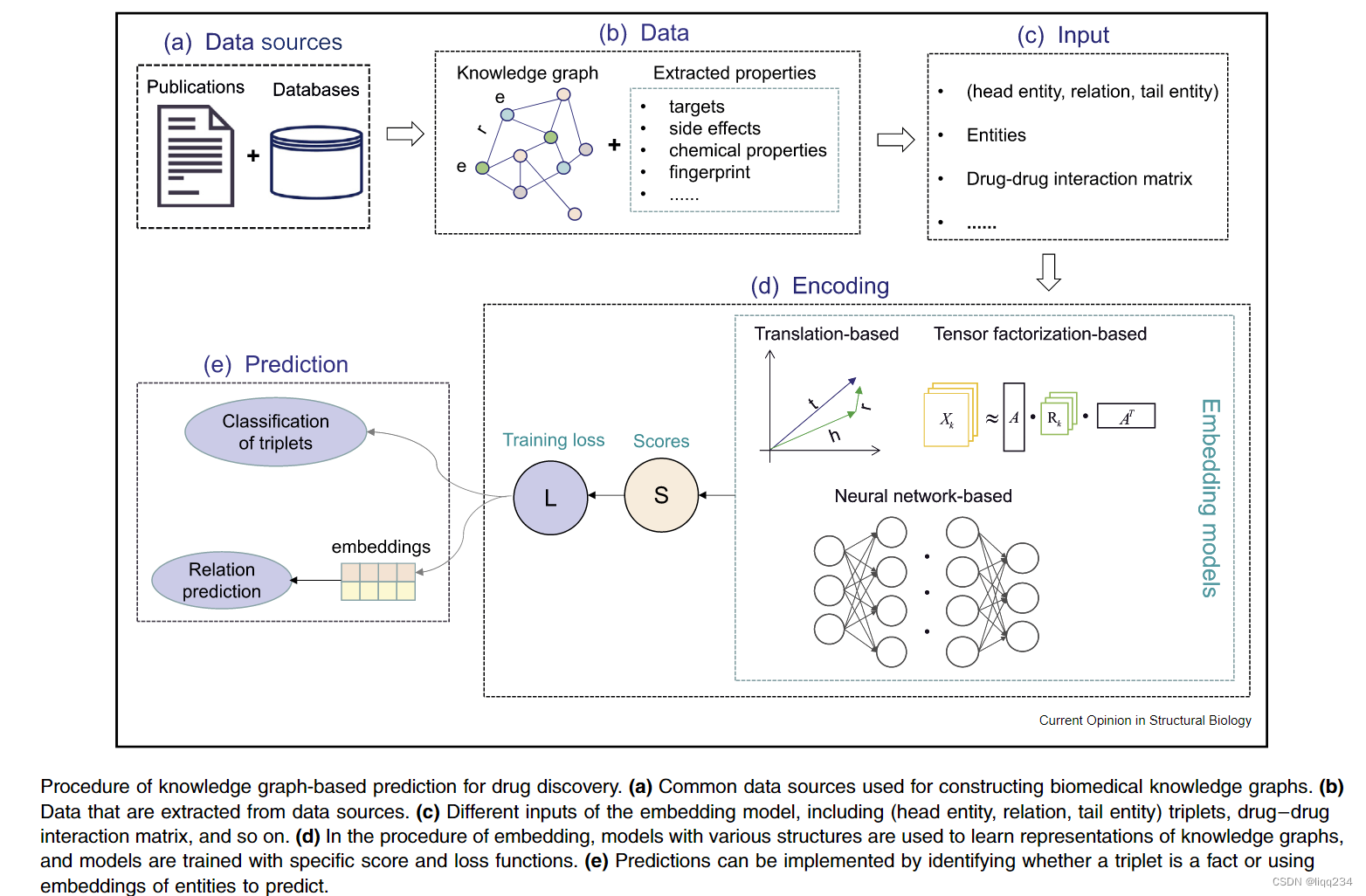
概述:基于知识图的药物发现预测过程。(a)用于构建生物医学知识图谱的常用数据源。(b)从数据源提取的数据。©嵌入模型的不同输入,包括(头部实体、关系、尾部实体)三元组、药物-药物相互作用矩阵等。(d)在嵌入过程中,使用不同结构的模型来学习知识图的表示,并使用特定的分数和损失函数来训练模型。(e)预测可以通过确定三元组是否为事实或使用实体嵌入进行预测来实现。
Construction and embedding of biomedical KGs
-
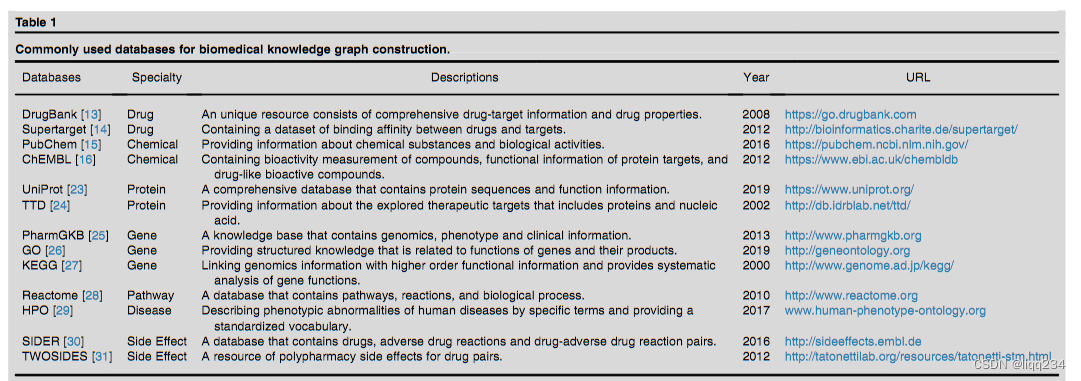
已有的数据库:
- DrugBank、SuperTarget 主要包含药物的属性
- Pubchem、ChEMBL 提供了化学相关的信息例如化合物的生物活性和功能
- GNBR、DRKG 作为两个公开可获取的知识图谱,包含了从许多生物医学文献提取的信息
- Hetionet 是从29个公开可获取的数据源中整合而来的数据库
- CBKH 是从各种生物知识图谱收集整合而来的数据库
-
用于预测任务的知识嵌入方法:

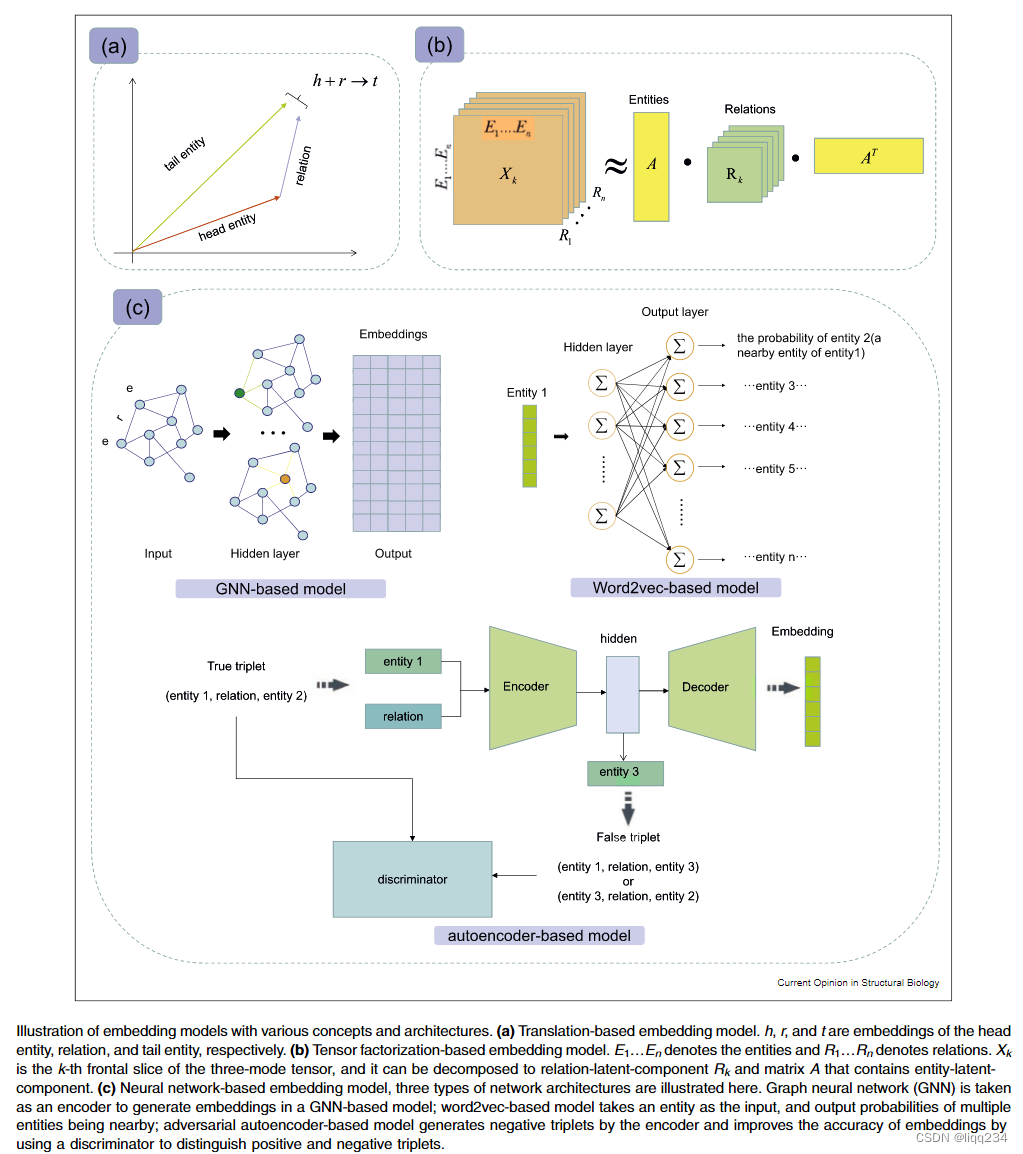
- Translation-based models
- 概念:如何建立简单且易拓展的模型把知识库中的实体和关系映射到低维向量空间中,从而计算出隐含的关系?将实体与关系嵌入到同一低维向量空间。
- 经典模型:基于翻译模型(Trans系列)的知识表示学习
- Tensor factorization-based models
- 概念:基于张量分解的方法可以将关系建模为三模张量X,而不依赖于任何关于KGs的信息。
- 经典模型:知识图谱中的链接预测——张量分解篇
- Neural network-based models
- 概念:嵌入模型通过引入神经网络结构,将KGs的表示形式通过非线性变换编码到向量空间中。对于知识表示学习,图神经网络(graph neural network, GNN)[图2©]是一种有利的架构,因为它能够获得节点之间潜在的远距离相关性。
- 经典模型:KGNN、GCN、RS-GCN
- 发展:卷积神经网络在提高多层表达的同时,又能保持参数的有效性。Dettmers等人提出了ConvE,使用具有卷积和完全连接层的二维卷积来模拟交互。最近的工作是探索平移特性的使用,以及利用神经网络的非线性拟合能力。例如,Dou等人设计了一个基于多任务学习的模型,命名为TransMTL。在该模型中,将平移和神经网络方法相结合,同时学习一个KG的多个嵌入。Che等人提出了ParamE,将关系的嵌入作为模型的参数,模型将头部实体和尾部实体分别作为输入和输出。
- Translation-based models
-
Application of KG in drug discovery
- Drug design and development
- 药物的概念:靶标是生物体内药物的结合位点。 靶标和药物之间的绑定可以改变细胞的功能,从而实现疾病的治疗。药物设计始于靶点鉴定,靶点通常从科学文献中选择或通过实验初步鉴定。一旦选定目标,研究人员就开始寻找可能作用于目标的先导化合物。先导化合物可以从天然产物中获得,也可以根据目标物的空间结构通过计算机模拟合成。通过进一步筛选,确定先导化合物,并通过修饰、优化、构效关系、多轮筛选等方法合成候选药物。
- 药物设计与知识图谱:设计一种对某些疾病有效的药物从目标识别开始,然后是一个漫长的周期。为了提高药物发现的效率,研究人员探索了“旧”药物[60]的再利用,这涉及低风险药物,并使其有可能更早地进入临床阶段。对药物不良反应的评估在药理学分析和临床应用中也是一项至关重要的工作,因此,在安全性药理学分析和III期临床试验阶段,研究人员通常会投入大量资金,通过识别副作用和ddi来评估药物不良反应。从这个角度来看,采用基于KG的药物再利用和ADR预测的互补技术是一种有效的选择。
- KG-based prediction
- Prediction of ADR:不良反应是指不符合预期治疗效果的不良反应,通常会对患者造成伤害[61]。1-Abdelaziz设计了一种基于相似性的模型,名为Tiresias,该模型将DDI建模为KG中的链接,并将DDI预测视为链接预测。构建具有药物属性和关系的生物医学KG,通过计算药物之间的相似度来推断相互作用。训练tiressias来预测从KG得到的具有全局和局部特征的潜在ddi。2-Karim等人没有计算药物之间的相似值来预测DDI,而是尝试学习KG的嵌入,并使用学习到的嵌入来预测DDI。他们通过整合来自各种数据库的1200种药物特征构建了一个KG,并训练ComplEx来学习药物表征。药物之间的关系通过药物对中每种药物的串联嵌入来表示,作者训练了convl - lstm,以基于学习到的关系表示来预测ddi。在本研究中,作者利用长短期记忆来保存长距离药物之间的效果,这与Abdelaziz等研究中利用“全局特征”的目的相同。3-Dai在没有任何药物性质或结构信息的情况下,使用仅包含各种药物名称和相互作用的kg来训练预测潜在相互作用的模型。设计了一种对抗性自编码器作为嵌入模型,并利用该模型的解码器生成负样本。4-Lin等人使用KG和DDI矩阵作为输入。他们将DDI预测建模为一个二元分类问题,并提出了一个名为KGNN的嵌入模型,KGNN的预测值表明感兴趣的药物对之间是否存在相互作用。作者将KG和GNN结合起来捕捉语义关系和高阶结构,这克服了先前工作中的一个挑战。大多数研究关注的是嵌入模型的有效性和准确性,而忽略了任务的多样性。一般来说,DDI预测被建模为一个二元分类问题,表明是否存在与分类标签的相互作用,而多类型药物相互作用的预测更有意义。5-Yu等人[12]使用多通道神经编码器实现多类型DDI预测。他们提取了包含给定药物对邻域实体的子图,并通过生成基于GNN的途径提供了药物相互作用的机制,从而整合了多样的信息生成药物对表示。6-引起药品不良反应的另一个关键因素是药物的副作用,例如,患者可能对药物中的某些成分过敏。Munoz等[71]没有将重点放在预测ddi上,而是采用多标签排序机制来预测副作用,每个标签代表一种副作用。在这项工作中,生成各种特征来训练多标签排序模型。7-分子结构所包含的信息,以及分子间的关系和拓扑结构信息都很重要。为了整合药物结构和KG中包含的信息,Chen提出了一种名为MUFFIN的DDI预测模型,该模型分别通过消息传递神经网络和TransE学习实体中药物结构和相应知识的表示。药物的最终表示表示为结构表示和知识表示的串联。8-Wang等提出了一种名为MIRACLE的DDI预测模型。在MIRACLE中,药物结构和关系所包含的信息用多视图图建模,其中的节点表示为药物的分子结构。这两项工作为未来基于kg的药物发现方法的发展带来了启发,研究人员可以在未来的工作中以更有效的方式利用现有数据,即通过将拓扑结构和语义关系与分子结构相结合,从数据中投资信息。
- Prediction for drug repurposing:概念-药物再利用是一种策略,用于从已批准的药物中寻找治疗特定疾病的药物(即确定已知药物的新用途),通过确定药物与疾病之间的关联或推断药物与靶标之间的相互作用来实施。因此,预测DDA和DTI是药物发现的重要一步。通常,研究人员致力于开发基于机器学习的药物再利用方法,这些方法将已知的dti作为标签,并使用测量数据(例如分子结构,蛋白质序列,表达谱和分子指纹)作为输入特征。1-Chu等提出了一种名为DTI-MLCD的多标签分类方法。在这种方法中,药物用分子描述符和指纹来描述,靶标用三种不同类型的序列衍生特征来表示。2-Madhukar等人提出了一种基于贝叶斯的方法,称为BANDIT,该模型通过集成多种类型的数据来实现DTI预测,包括生长抑制数据、基因表达数据和生物测定/化学结构。3-Zhao等提出了一种新的工作流程来预测特定疾病的适应症。他们以药物的表达谱为特征,选择具有高再利用概率的药物作为候选药物。4-Alshahrani等人[78]将符号方法与神经网络相结合,生成实体嵌入。使用符号逻辑和自动推理将显式和隐式信息纳入嵌入,使用Word2vec[53]将随机行走生成的语料库作为输入。学习到的表示用于预测可能表明基因与疾病、蛋白质对或药物靶标对之间潜在关系的链接。5-Alshahrani和Hoehndorf的研究使用随机漫步从KG生成语料库,并使用Word2Vec学习表征。6-Mohamed等人提出了基于张量分解的TriModel。在这项工作中,构建了一个由药物和靶点组成的KG,并用TriModel识别实体的表示并用于进一步的相互作用预测。当一种疾病具有共同的治疗方法时,就被认为与另一种疾病相似,因此用于一种疾病的药物可能对疾病对中的另一种疾病有效。因此,一种药物的新适应症可以通过具有相似适应症的另一种药物发现。预测DDAs有助于研究人员推断药物的新适应症,这是寻找罕见病新疗法的有效方法。7-Sang等人提出了GrEDel来学习生物医学KG的表示,并训练了一个长短期记忆模型来预测dda的概率。8-Zhu等人通过整合多个与药物相关的知识库开发了一个KG,提出了一种实现药物再利用的新方法。9-Sosa等关注的是生存率较低的罕见病,旨在利用现有数据生成针对罕见病的药物再利用假设。作者使用了一种称为GNBR[19]的异质KG来支持重新利用假设。在他们的工作中,不仅进行了链接预测,而且还对关系的不确定性进行了建模,这有利于产生令人信服的结果。10-Himmelstein等人构建了一个名为Hetionet的集成KG,并使用社会网络分析算法来识别KG中的网络模式。网络模式表明一种药物是否是一种特定疾病的治疗方法。11-Mc-cusker等人[85]试图使用概率KG来寻找候选药物,并开发了一个系统ReDrugS,用于检查药物靶向疾病网络并寻找支持的药物黑素瘤。值得注意的是,他们宣布通过计算候选药物的置信度分数来提高候选药物的准确性。COVID-19成为全世界关注的焦点;基于药物再利用,为COVID-19提供可能的治疗策略的机会越来越多。 12-Zeng等人构建了一个包含表达、基因、通路、疾病、药物的综合性KG,命名为DRKG。作者确定了41种可能治疗COVID-19的药物。13-最新工作进一步使用了DRKG,其中提出了一个耦合张量-矩阵嵌入框架,以提取kg的简明表示,并在抗击COVID-19的斗争中实现药物重新利用。14-此外,Wang等人开发了基于知识的框架COVID-KG,从文献中获取知识元素,并构建了多媒体kg,用于生成科学报告和回答药物再利用相关问题。
- Drug design and development
未来展望
以kg为基础的方法协助药物发现是一个相对较新的和有价值的方向。该领域的工作使得通过从中提取语义信息和结构化关系来有效地利用现有数据源成为可能。值得注意的是,KG带来了新的挑战,也带来了好处。在本节中,我们将从以下三个方面讨论基于kg的药物发现工作目前面临的挑战和未来的发展方向。
- Biomedical KG:基于生物医学千克数的药物发现在很大程度上依赖于KGs的质量,因此构建高质量的综合性生物医学KGs至关重要。在构建KGs时,除了使用数据库中的数据外,研究人员还利用自然语言处理(NLP)技术从生物医学文献中提取实体和关系。然而,由于NLP模型不可避免的不准确性,可能会带来噪声,例如,可能会产生不存在的关系和不准确的实体命名[88]。此外,生物医学课程总是涵盖广泛的学科领域。对于上述问题,我们认为开发针对生物医学领域的强大的自动化错误检测方法可以从数据源方面帮助提高kg的质量。此外,研究者不应局限于不断建立新的KGs,而应关注现有KGs的更新和维护,在KGs中加入从最新发表的文献中获得的知识,反驳以往研究结论的新证据,以及制药公司和研究机构产生的新数据,使KGs更加全面。多方以统一的格式共同构建KG可能会使维护KG更容易。最后但并非最不重要的是,KG的质量仍然难以测量,而质量估计可以帮助进一步提高KG的质量,Zhao等人[89]的研究工作可以给我们带来启示,他们用逻辑规则估计了KG中三胞胎的概率。设计有效的质量评价方法是今后工作的一个有价值的方向。
- Design of model:现有用于药物发现预测的模型大多是基于嵌入模型构建的,并被证明具有一定的有效性。然而,由这些模型产生的预测仍然缺乏对药物再利用和ADR预测至关重要的可靠解释。通常,现有的模型只能预测相互作用是否存在,而不能解释药物如何起作用或提供治疗的药理作用的机制。没有可解释性,很难说服人们相信结果。从这方面来看,需要能够为预测生成解释的模型。值得注意的是,一些工作已经作出了初步努力。例如,Kang等人[90]使用最重要的事实对预测进行解释,Zhang等人[91]使用基于嵌入的路径搜索生成解释。此外,嵌入模型在有效学习表征方面仍然面临挑战。例如,通常通过用随机实体替换正样本中的实体来生成负样本。由于KGs的不完备性,部分阴性样品实际上可能是阳性的。为了解决这一问题,以适当的方式生成负样本是具有重要意义的优化。另一种优化可以通过引入评估机制来计算预测的三元组的合理性,从而提供更可靠的结果。此外,由于在大型和稀疏的生物医学知识库上训练嵌入模型耗时长,且对内存的要求高,因此期望在生物医学领域建立通用的预训练嵌入模型。
- Strategies for better prediction:现有的工作主要集中在通过预测兴趣实体对之间是否存在交互来实现交互预测,即将预测任务视为一个二分类问题。两个实体之间的关系类型是多种多样的,但很少有作品努力推断预测关系的类型。推断这些关系的类型可能有助于确定ddi的影响,并找到治疗疾病的新方法。例如,华法林(一种抗凝剂)和头孢定(一种抗生素)联合使用可引起出血相关的ddi,包括胃肠道出血和抑制凝血[58]。很自然地推断氟康唑(也是一种抗生素)与华法林的相互作用更可能与出血有关。鉴于此,推断与指示性标签的相互作用是一种潜在的方法。在未来,我们也期待着从单模态学习向多模态学习的转变。分子图和分子序列中包含的视图间信息以及KGs中包含的视图内关系和语义信息都很重要,从这个角度来看,多模态学习有利于学习信息更全面的表征,从而实现更准确的预测。因此,设计基于多模态学习的新方法,充分利用KGs、分子图像、序列和分子图,是药物发现领域更好地预测的一个有前途的方向。
总结
通过使用KGs来辅助数据驱动的药物研究,可以加速药物发现的过程。受此应用的启发,最近的研究将KG引入到基于KG嵌入模型和生物医学KG的各种药物发现预测问题中。在本文中,我们总结了用于KG构建的常用数据库,并概述了药物发现领域中具有代表性的知识嵌入模型和基于KG的预测。最后,我们谨慎地总结,未来仍有一些挑战需要解决,并对这些挑战进行了详细的讨论,旨在为该领域的未来提供清晰的前景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









