







MLib 机器学习算法的标准API可以很方便的把多个算法整合到一个pipeline中,并可以把整个过程形象的比如机器学习算法流;
Pipeline包括三个阶段:
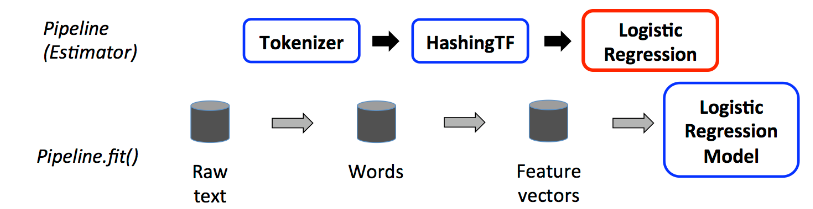
第一阶段:Tokenier会把每个一个文件分成word
第二阶段:把word转化为特征向量
第三阶段:用特征向量和列别训练模型
下面就以一个简单的逻辑回归为例说明使用Pipeline开发;
定义一个类:
public class Person implements Serializable{
public static final long serialVersionUID = 1L;
public long id;
public String text;
public double label;
public Person(){};
public Person(long id, String text) {
this.id = id;
this.text = text;
}
public Person(long id, String text, double label) {
super();
this.id = id;
this.text = text;
this.label = label;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public double getLabel() {
return label;
}
public void setLabel(double label) {
this.label = label;
}
@Override
public String toString() {
return "Person [id=" + id + ", text=" + text + ", label=" + label + "]";
}
}public static void main(String[] args) {
SparkSession sparkSession = SparkSession
.builder()
.appName("loi").master("local[1]")
.getOrCreate();
// Create an RDD of SparkIn objects from a text file
JavaRDD<String> dataRDD = sparkSession
.read()
. textFile("E:/sparkMlib/sparkMlib/src/mllib/testLine.txt")
.javaRDD();
JavaRDD<Person> dataPerson = dataRDD.map(new Function<String,Person>(){
public Person call(String line) throws Exception {
String[] parts = line.split(",");
Person sparkIn = new Person();
sparkIn.setId(Long.parseLong(parts[0]));
sparkIn.setText(parts[1]);
sparkIn.setLabel(Double.parseDouble(parts[2]));
return sparkIn;
}
});
// Apply a schema to an RDD of JavaBeans to get a DataFrame
Dataset<Row> training = sparkSession.createDataFrame(dataPerson, Person.class);
//把document组成words
Tokenizer tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words");
//words特征向量化
HashingTF hashigTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol())
.setOutputCol("features");
//选择模型
LogisticRegression lr = new LogisticRegression()
.setMaxIter(30)
.setRegParam(0.001);
//组建pipeline流
Pipeline pipeline =new Pipeline()
.setStages(new PipelineStage[]{tokenizer,hashigTF,lr});
//训练模型
PipelineModel model = pipeline.fit(training);
//组织预测数据
Dataset<Row> test =sparkSession.createDataFrame(
Arrays.asList(
new Person(4,"spark i j k"),
new Person(5,"l m n"),
new Person(6,"spark hadoop spark"),
new Person(7,"apache hadoop")),
Person.class);
Dataset<Row> predictions =model.transform(test);
for(Row r:predictions.select("id", "text", "probability", "prediction").collectAsList()){
System.out.println(r.get(0)+":"+r.get(1)+":"+r.get(2)+":"+r.get(3));
}
}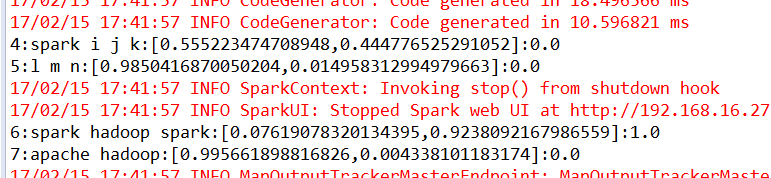
以上就是用P ipeline实现的一个简单的逻辑回归模型;















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









