







参考 Coursera上斯坦福大学Andrew Ng教授的“机器学习公开课”:
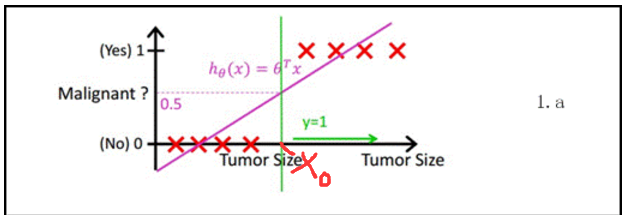
逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数;回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系,逻辑分类是两元分类;我们将因变量(dependant variable)可能属于的两个类分别称为负向类(negative class)和正向类(positive class) ,其中 0 表示负向类,1 表示正向类。比如有如下图所示,X为数据点——肿瘤的大小,Y为观测值——是否是恶性肿瘤。通过构建线性回归模型,如h θ (x)所示,构建线性回归模型后,即可以根据肿瘤大小,预测是否为恶性肿瘤h θ (x)≥.05为恶性,h θ (x)<0.5为良性。故可以判断当size>X0点为恶性肿瘤;
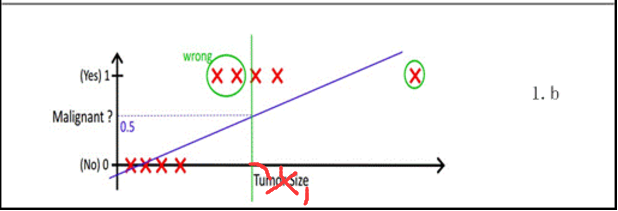
但是当出现噪点后(某个肿瘤很大的时候),就会出现问题,现在按h θ (x)=0.5的标准去判断时候获取X₁点为size判断点,这样就会出现判断错误现象;
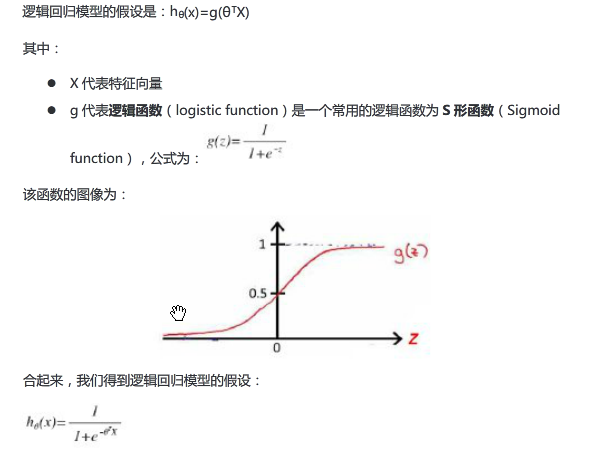
现在引入了一个新的模型,逻辑回归该模式输出变量始终在0和1之间;逻辑回归模式的假设是

逻辑回归的代价函数:


然后用梯度下降法计算代价函数

上面简单的描述了逻辑回归的原理,详细可以参考公开课;下面就用sparkMlib实现一个逻辑回归训练模型;
public static void main(String[] args) {
SparkSession sparkSession = SparkSession
.builder()
.appName("JavaLinearRegressionWithElasticNetExample").master("local[2]")
.getOrCreate();
//生产List<row>
List<Row> dataTraining = Arrays.asList(
RowFactory.create(1.0,Vectors.dense(0.0,1.1,0.1)),
RowFactory.create(0.0,Vectors.dense(2.0,1.0,-1.0)),
RowFactory.create(0.0, Vectors.dense(2.0, 1.3, 1.0)),
RowFactory.create(1.0, Vectors.dense(0.0, 1.2, -0.5))
);
StructType schema = new StructType(new StructField[]{
new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("features", new VectorUDT(), false, Metadata.empty())
});
//创建dataset
Dataset<Row> training = sparkSession.createDataFrame(dataTraining, schema);
LogisticRegression lr =new LogisticRegression();
//打印参数描述
System.out.println("目前lr的参数描述"+lr.explainParams());
//设置循环参数
lr.setMaxIter(10).setRegParam(0.01);
LogisticRegressionModel model1 = lr.fit(training);
System.out.println("Model 1 was fit using parameters: " + model1.parent().extractParamMap());
//也可以用paramMap修改参数
ParamMap paramMap = new ParamMap()
.put(lr.maxIter().w(30))
.put(lr.regParam(), 0.01)
.put(lr.regParam().w(0.2), lr.threshold().w(0.55));
// One can also combine ParamMaps.
ParamMap paramMap2 = new ParamMap()
.put(lr.probabilityCol().w("myProbability")); // Change output column name
ParamMap paramMapCombined = paramMap.$plus$plus(paramMap2);
// Now learn a new model using the paramMapCombined parameters.
// paramMapCombined overrides all parameters set earlier via lr.set* methods.
LogisticRegressionModel model2 = lr.fit(training, paramMapCombined);
System.out.println("Model 2 was fit using parameters: " + model2.parent().extractParamMap());
// Prepare test documents.
List<Row> dataTest = Arrays.asList(
RowFactory.create(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
RowFactory.create(0.0, Vectors.dense(3.0, 2.0, -0.1)),
RowFactory.create(1.0, Vectors.dense(0.0, 2.2, -1.5))
);
Dataset<Row> test = sparkSession.createDataFrame(dataTest, schema);
// Make predictions on test documents using the Transformer.transform() method.
// LogisticRegression.transform will only use the 'features' column.
// Note that model2.transform() outputs a 'myProbability' column instead of the usual
// 'probability' column since we renamed the lr.probabilityCol parameter previously.
Dataset<Row> results = model2.transform(test);
Dataset<Row> rows = results.select("features", "label", "myProbability", "prediction");
for (Row r: rows.collectAsList()) {
System.out.println("(" + r.get(0) + ", " + r.get(1) + ") -> prob=" + r.get(2)
+ ", prediction=" + r.get(3));
}
}















 4763
4763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









