







写在前面
并行线程执行(Parallel Thread eXecution,PTX)代码是编译后的GPU代码的一种中间形式,它可以再次编译为原生的GPU微码。CUDA 手册传送门:Parallel Thread Execution ISA Version 4.3
利用PTX来进行试验,我们可以解决一些在写代码时遇到的不确定问题。下面举几个例子:
- 核函数的参数是直接放到寄存器中么?
- 一个算法在核函数里面即可以用for来实现也可以用if判断来实现,这两个的执行效率,谁更快一些?
- 核函数里面有75个变量,为什么编译的时候显示寄存器用量是60个?
- CPU中二进制比乘除法效率高,GPU是否也是这样?
问题1、3可以直接通过看PTX代码得出结论,2、4还需要我们继续做一个验证性试验。下面将给出问题4的解法。
实验中重点分为两部分,第一部分是判断nvcc编译器到底能智能到什么程度(我们都知道编译器在编译的时候会自己做一些优化,比如舍去一些你不用的变量和简化计算等等);如果第一部分的答案是编译器编译乘除法和位移计算得到的ptx指令是相同的(就代表着相当智能了),那么结果很明显就是没有区别,就没有继续的必要。但是如果不一样,那么我们还需要做一个实验判断哪个更快一些了。
1. 根据问题写出测试代码,得到测试代码的PTX代码
首先第一部分,我写了一段简易的测试代码,如下:
__global__ void mul(int *di)
{
int n = *di;
n = n * 2;
*di = n;
}
__global__ void div(int *di)
{
int n = *di;
n = n / 2;
*di = n;
}
__global__ void shl(int *di)
{
int n = *di;
n = n << 1;
*di = n;
}
__global__ void shr(int *di)
{
int n = *di;
n = n >> 1;
*di = n;
}编译测试代码,编译时加 -keep参数,得到ptx文件内容如下(只摘取重要部分),顺序为乘法、除法、左移、右移:
mul.lo.s32 %r2, %r1, 2; ld.global.s32 %r1, [%rd1+0]; // 将参数赋给寄存器 r1
shr.s32 %r2, %r1, 31; // 将r1右移31位,即将符号位移到最低位
mov.s32 %r3, 1; // r3 = 1
and.b32 %r4, %r2, %r3; // 用 与运算 获取最低位,即获取r1的符号位
add.s32 %r5, %r4, %r1; // 原数加上符号位赋给r5
shr.s32 %r6, %r5, 1; // r5 右移一位赋给 r6
st.global.s32 [%rd1+0], %r6; // 将计算结果重新赋值到 global memory中这里仔细解释一下除法的PTX代码
经过分析,该计算过程能更加健壮地实现除法运算。对于所有正整数和所有非 -1 负整数,除法运算和右移的结果是没有差别的!但是对于 -1,
-1/2的结果是0(正确结果),-1 >> 1的结果是-1(错误结果)!
shl.b32 %r2, %r1, 1;shr.s32 %r2, %r1, 1;根据ptx code 我们可以看出,乘法运算被翻译为mul指令,除法运算被翻译成了5条指令, 位移运算被翻译为shl(左移位)或shr(右移位)指令。故第一部分我们得出的结论为nvcc编译器在编译阶段对乘除法运算和位移运算的编译结果是不同的。
2. 验证试验
因此,进行第二部分实验,验证乘除运算和位移运算哪个速度更快一些。
为了排除其他因素的影响,我选用了NVIDIA_CUDA-5.0_Samples里的vectorAdd(矩阵相加)源代码,对其进行了一些改动,如下:
__global__ void vectorMul(const int *A, int *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
C[i] = A[i] * 2;
}
__global__ void vectorDiv(const int *A, int *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
C[i] = A[i] / 2;
}
__global__ void vectorShl(const int *A, int *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
C[i] = A[i] << 1;
}
__global__ void vectorShr(const int *A, int *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
C[i] = A[i] >> 1;
}测试数据量大小为256,1024,4096, 16384, 65536, 262144, 1048576,进行了10000次循环计算后取速度平均值,结果分别如下:
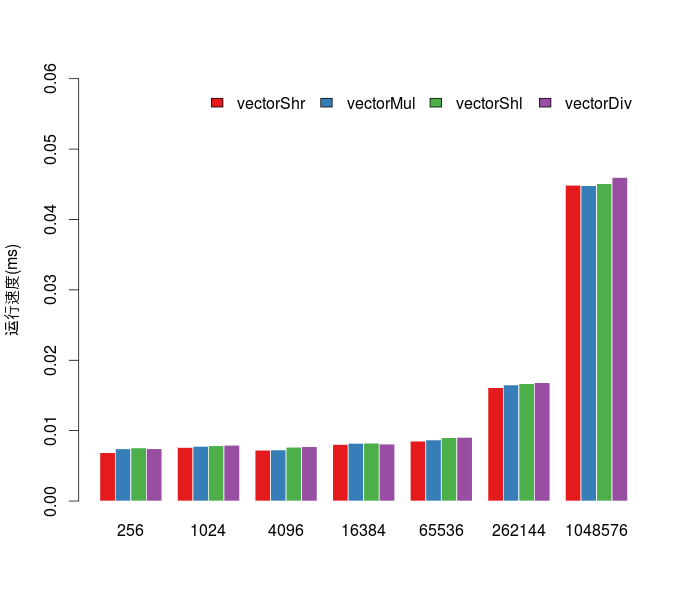
从图中可以看出,除了在数据量较大(>65536)的情况下,除法运算会慢一点(慢不到0.001,大部分的时间都花在了数据传输上),四种运算方式的运行时间是没有绝对的规律。
尽管除法运算会被翻译成较复杂的ptx指令,但GPU的执行速度非常快,所以为了保证代码的可读性,并不建议在核函数中用位移运算代替乘除运算!
写在后面
OpenCUDA:CUDA图像算法开源项目,算法内都有详细的注释,大家一起学习。
私人接各种CUDA相关外包(调试、优化、开发图像算法等),有意向请联系,加好友时请注明。
















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









