






TL;DR
一图胜千言。如果显示的比较小,请右键,点击“在新标签页中打开图像”!
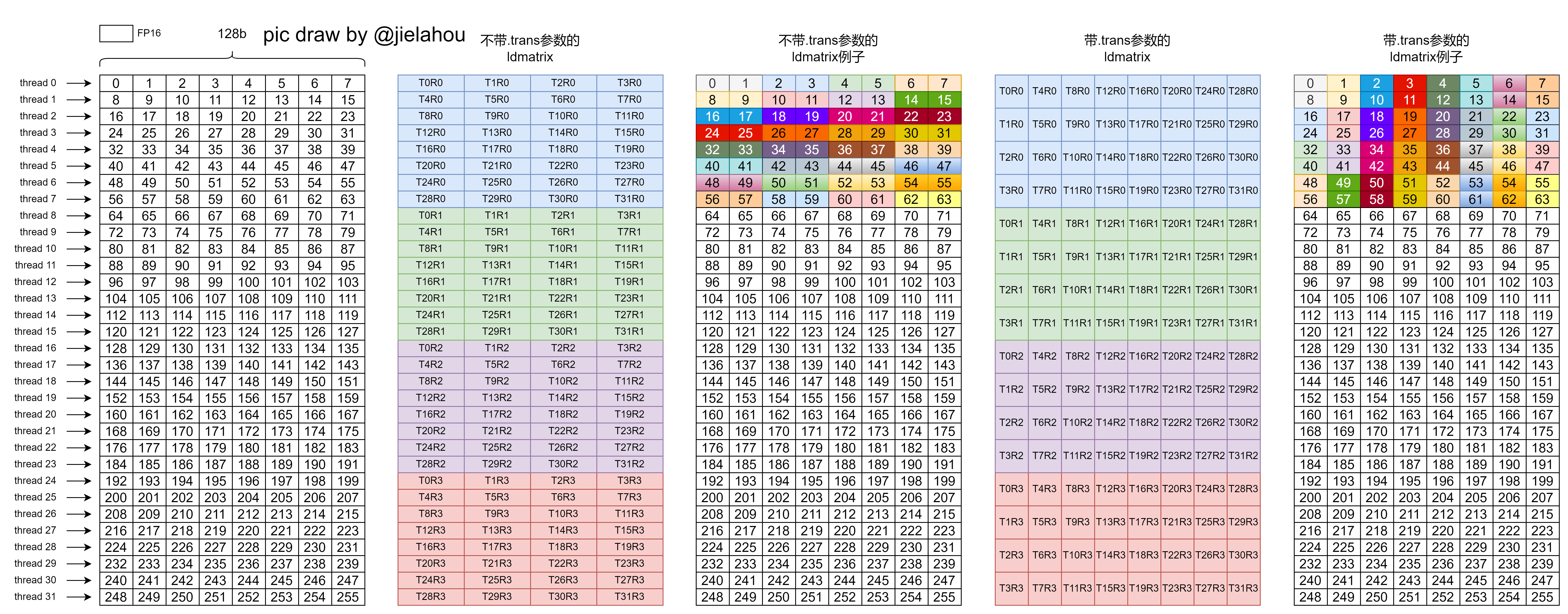
2025.03.31 备注:这个图是我自己用Draw.io结合自己写的脚本画出来的。在网络冲浪过程中,无意中发现cutlass/cute已经内置了画分布的能力,代码片段可参考:https://gist.github.com/66RING/2e188b73fdf703e9f9dfc7371814dd15
2024.08.05 Update 另一个视角:对于不带Trans参数的ldmatrix,一个线程的128b数据仅分配给4个线程;对于带Trans参数的ldmatrix,一个线程的128b数据会分配给8个线程。
前言
笔者在试图使用mma指令进行m16n8k16实现FP16矩阵乘法时,发现其要求每个线程以类似列优先的方式提供B的两个操作数(官方文档)。然而众所周知,我们在存储矩阵时,一般都是以行优先去存的。此时,若直接使用ldmatrix指令去加载,每个线程无法提供mma指令所要求的B矩阵中的数字。
好在,ldmatrix指令有一个trans修饰符。但网络上关于此修饰符的资料较少,所以做了个实验测试下。
实验代码
大致思路是生成4个8*8的矩阵(值依次为0~254,便于反过来定位指令行为),然后使用带trans的ldmatrix去读。将读的结果写回主机,根据每个线程读到的数字,反推指令的行为。
#include "cuda_runtime.h"
#include <iostream>
#include <cuda_fp16.h>
using namespace std;
//Github @jielahou
__global__ void test_ldmatrix_trans(half* read, half* write){
__align__(16) __shared__ half smem [8*8*4];
uint32_t reg[4];
//global --> shared
//32 threads 每个thread需负责读入8个half 可以用128bit向量指令一口气读入
const int start_id = threadIdx.x * 8;
(reinterpret_cast<float4*>(&smem[start_id]))[0] = (reinterpret_cast<float4*>(&read[start_id]))[0];
//use ldmatrix.trans
asm("ldmatrix.sync.aligned.m8n8.x4.trans.b16 {%0, %1, %2, %3}, [%4];\n\t"
: "=r"(reg[0]), "=r"(reg[1]), "=r"(reg[2]), "=r"(reg[3])
: "l"(&smem[start_id]));
//reg --> global
(reinterpret_cast<float*>(&write[start_id + 0]))[0] = (reinterpret_cast<float*>(®[0]))[0];
(reinterpret_cast<float*>(&write[start_id + 2]))[0] = (reinterpret_cast<float*>(®[1]))[0];
(reinterpret_cast<float*>(&write[start_id + 4]))[0] = (reinterpret_cast<float*>(®[2]))[0];
(reinterpret_cast<float*>(&write[start_id + 6]))[0] = (reinterpret_cast<float*>(®[3]))[0];
}
template<typename T,int N> void init_mem(T (&ptr)[N]){
for(int i=0;i<N;i++){
ptr[i] = i;
}
}
int main(){
//FP16, (8*8) * 4个
half host_send[8*8*4];
half host_receive[8*8*4];
half* device_read;
half* device_write;
init_mem(host_send);
constexpr int data_size = 8*8*4 * sizeof(half);
cudaMalloc(&device_read, data_size);
cudaMalloc(&device_write, data_size);
cudaMemcpy(device_read, host_send, data_size, cudaMemcpyHostToDevice);
test_ldmatrix_trans<<<1, 32>>>(device_read, device_write);
cudaDeviceSynchronize();
cudaMemcpy(host_receive, device_write, data_size, cudaMemcpyDeviceToHost);
for(int i=0;i<32;i++){
cout << "thread " << i << " holds: ";
for(int j=0;j<8;j+=2){
cout << "(" << j/2 << ")" << " " << __half2float(host_receive[i*8 + j]) << ", " << __half2float(host_receive[i*8 + (j + 1)]) << ",";
}
cout << endl;
}
return 0;
}
输出结果:
thread 0 holds: (0) 0, 8,(1) 64, 72,(2) 128, 136,(3) 192, 200,
thread 1 holds: (0) 16, 24,(1) 80, 88,(2) 144, 152,(3) 208, 216,
thread 2 holds: (0) 32, 40,(1) 96, 104,(2) 160, 168,(3) 224, 232,
thread 3 holds: (0) 48, 56,(1) 112, 120,(2) 176, 184,(3) 240, 248,
thread 4 holds: (0) 1, 9,(1) 65, 73,(2) 129, 137,(3) 193, 201,
thread 5 holds: (0) 17, 25,(1) 81, 89,(2) 145, 153,(3) 209, 217,
thread 6 holds: (0) 33, 41,(1) 97, 105,(2) 161, 169,(3) 225, 233,
thread 7 holds: (0) 49, 57,(1) 113, 121,(2) 177, 185,(3) 241, 249,
thread 8 holds: (0) 2, 10,(1) 66, 74,(2) 130, 138,(3) 194, 202,
thread 9 holds: (0) 18, 26,(1) 82, 90,(2) 146, 154,(3) 210, 218,
thread 10 holds: (0) 34, 42,(1) 98, 106,(2) 162, 170,(3) 226, 234,
thread 11 holds: (0) 50, 58,(1) 114, 122,(2) 178, 186,(3) 242, 250,
thread 12 holds: (0) 3, 11,(1) 67, 75,(2) 131, 139,(3) 195, 203,
thread 13 holds: (0) 19, 27,(1) 83, 91,(2) 147, 155,(3) 211, 219,
thread 14 holds: (0) 35, 43,(1) 99, 107,(2) 163, 171,(3) 227, 235,
thread 15 holds: (0) 51, 59,(1) 115, 123,(2) 179, 187,(3) 243, 251,
thread 16 holds: (0) 4, 12,(1) 68, 76,(2) 132, 140,(3) 196, 204,
thread 17 holds: (0) 20, 28,(1) 84, 92,(2) 148, 156,(3) 212, 220,
thread 18 holds: (0) 36, 44,(1) 100, 108,(2) 164, 172,(3) 228, 236,
thread 19 holds: (0) 52, 60,(1) 116, 124,(2) 180, 188,(3) 244, 252,
thread 20 holds: (0) 5, 13,(1) 69, 77,(2) 133, 141,(3) 197, 205,
thread 21 holds: (0) 21, 29,(1) 85, 93,(2) 149, 157,(3) 213, 221,
thread 22 holds: (0) 37, 45,(1) 101, 109,(2) 165, 173,(3) 229, 237,
thread 23 holds: (0) 53, 61,(1) 117, 125,(2) 181, 189,(3) 245, 253,
thread 24 holds: (0) 6, 14,(1) 70, 78,(2) 134, 142,(3) 198, 206,
thread 25 holds: (0) 22, 30,(1) 86, 94,(2) 150, 158,(3) 214, 222,
thread 26 holds: (0) 38, 46,(1) 102, 110,(2) 166, 174,(3) 230, 238,
thread 27 holds: (0) 54, 62,(1) 118, 126,(2) 182, 190,(3) 246, 254,
thread 28 holds: (0) 7, 15,(1) 71, 79,(2) 135, 143,(3) 199, 207,
thread 29 holds: (0) 23, 31,(1) 87, 95,(2) 151, 159,(3) 215, 223,
thread 30 holds: (0) 39, 47,(1) 103, 111,(2) 167, 175,(3) 231, 239,
thread 31 holds: (0) 55, 63,(1) 119, 127,(2) 183, 191,(3) 247, 255,
看枯燥的数字看不出啥,画成图才好理解!图请见本文最开始的部分。

















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









