







参考视频:
CUDA编程入门
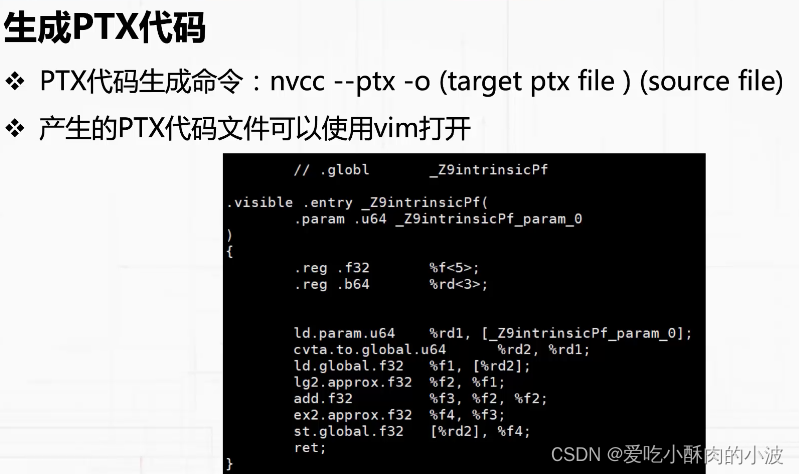
什么时GPU计算



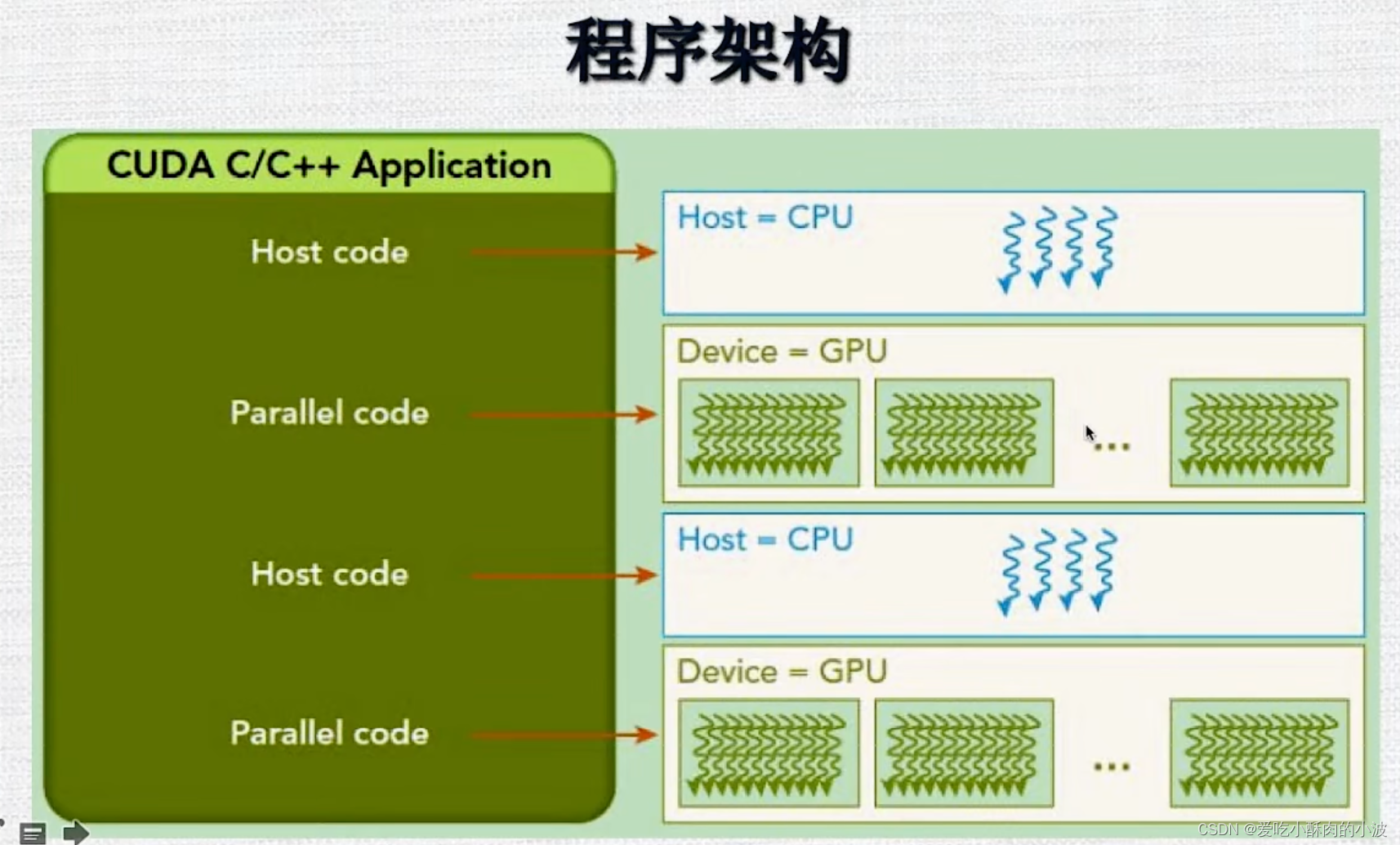

C++在编译成目标文件的时候接口可能因为函数重载而不同,可能会加一些后缀。



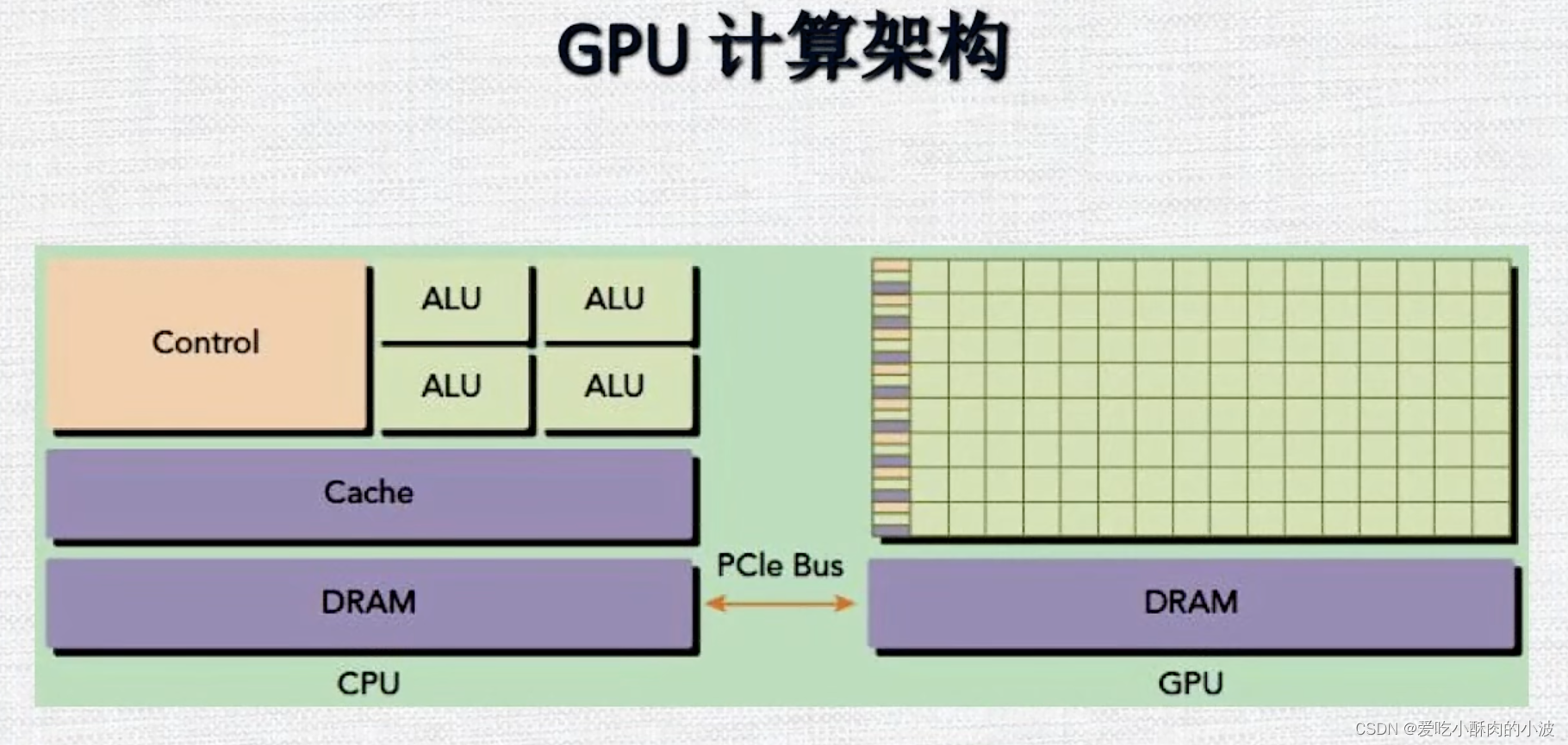
GPU硬件架构综述


SPA:Streaming Processor Array 流处理器序列(可以理解为所有的计算核心组成的一个队列)
TPC/GPC:(相当于把多个流处理器分成小组,但每个GPU的功能会有些不同)
SM:流多处理器(流多处理器是和我们设计程序的时候设计的块是对应起来的,流多处理器有自己的内存单元、作业调度单元,流多处理器包含32or16个流处理器单元)
SP:流处理器,Streaming Processor,也称为CUDA Core
warp是设计程序时特殊的单元。(比如一个程序含有128个线程,把每32个线程称为一个warp,一个warp是一个虚拟的并行计算的单元,warp是最基本的执行单位)
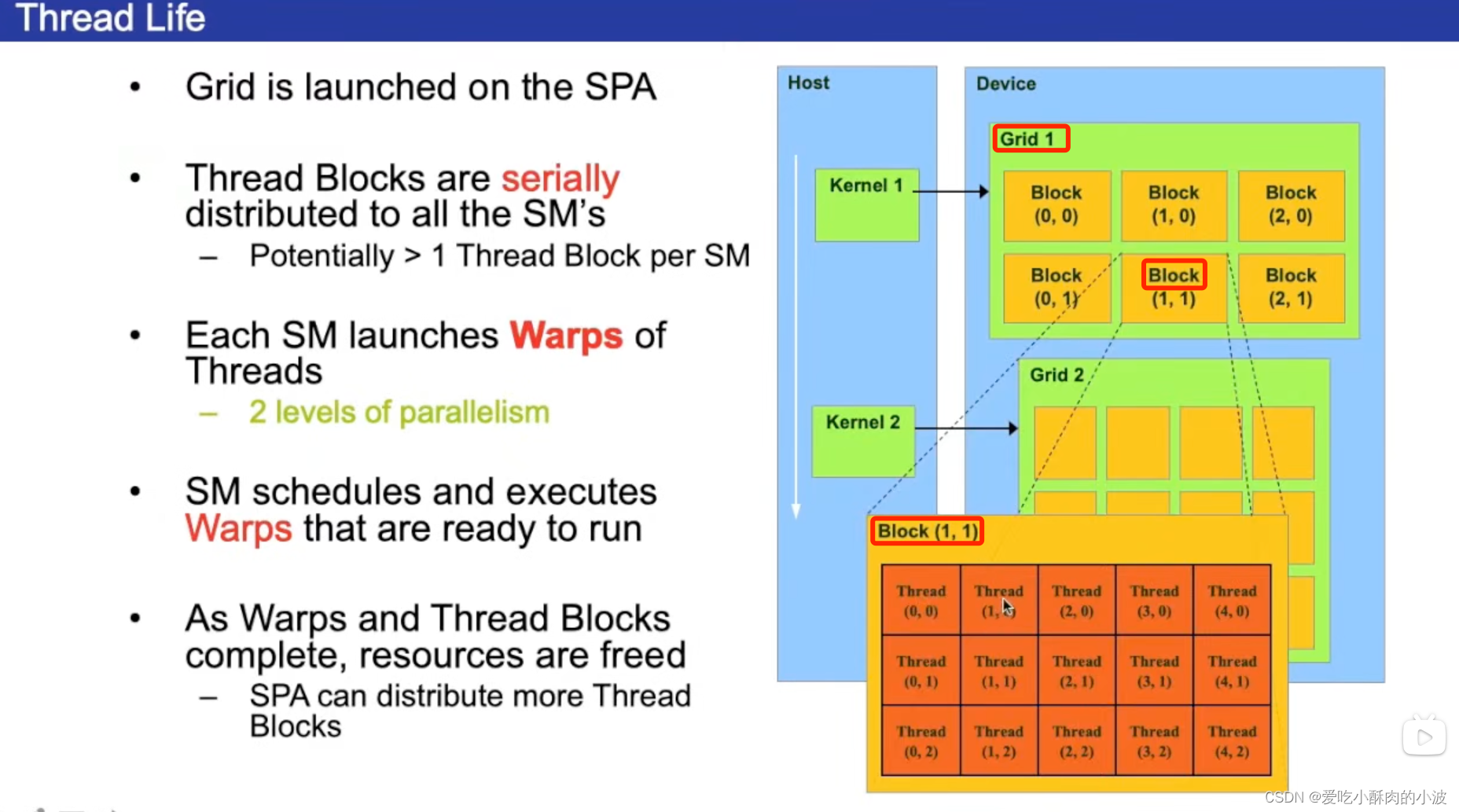
一般在写程序时是三级结构:程序分为一个网格,网格底下有块,块底下有线程。
在CUDA编程中,GPU计算模型以网格(grid)、块(block)和线程(thread)为基本的层次结构。这三个层次的数量限制取决于具体的GPU硬件和架构。
网格(Grid):网格是最大的层次结构,表示整个 GPU 上的计算任务。网格的大小是以块的数量为单位来度量的。
NVIDIA GPUs(例如CUDA架构)的网格大小限制通常是 65,535 个块。
块(Block):块是网格中的一个子集,它包含一组线程。块是调度和同步的基本单元。块内的线程可以协作共享内存,并且在块内的线程之间有较低的通信延迟。
每个块中的线程数量也是有限制的,通常在 512 到 1024 之间,取决于GPU的架构。
线程(Thread):线程是执行计算的最小单元。块内的线程可以协作,它们可以访问共享内存,共享数据,以及通过同步机制进行通信。
每个块中的线程数量取决于硬件架构,通常在 32 到 1024 之间。
需要注意的是,这些数量限制是硬件和架构相关的,不同的GPU型号和架构可能会有不同的限制。为了编写高效的CUDA程序,通常需要根据硬件的特性来优化网格、块和线程的数量。 NVIDIA 提供了一些工具和指南,帮助程序员优化CUDA程序以适应不同的硬件。
Warp(线程束):Warp 是硬件执行的最小单元,它包含一组连续的线程,通常是32个。所有线程在一个 warp 中并行执行相同的指令,这就是SIMD(单指令多数据)的基本单位。
所有线程在一个 warp 中执行的指令是同步的,即它们都执行相同的指令,无论这些线程是否满足条件。这就是为什么在一个 warp 中最好避免条件分支,以充分发挥SIMD的优势。
在GPU编程中warp/Grid/block/Thread有什么联系?
1.多个Thread组成一个Block。多个Warp组成一个Block。
2.多个Block组成一个Grid。
这种层次结构允许在不同层次上利用并行性,以处理不同层次的任务。
例如,一个Grid内的所有Block可以并行执行,而在每个Block内,多个Warp也可以并行执行。在Warp级别,线程是以SIMD的方式执行的。
 块中包含的线程数既不能太多,也不能太少。主要是为了充分利用 GPU 的硬件资源以及确保程序的高效执行。下面是一些相关的原因:
块中包含的线程数既不能太多,也不能太少。主要是为了充分利用 GPU 的硬件资源以及确保程序的高效执行。下面是一些相关的原因:
1️⃣共享内存的大小限制:
每个 block 共享一定大小的共享内存,这是用于线程之间协作和数据共享的一种机制。如果一个 block 中的线程数太多,可能会导致共享内存不足以满足每个线程的需求。因此,适当控制 block 中的线程数量可以更好地管理共享内存的使用。
2️⃣寄存器的限制:
每个线程在执行时使用寄存器来保存变量和中间结果。一个 block 中的线程数增加,可能导致寄存器的需求也增加。如果寄存器需求过多,可能会导致线程块中的线程数受到硬件资源限制。因此,适当控制线程数量有助于避免寄存器资源不足。
3️⃣调度和同步开销:
当 block 中的线程数很大时,调度和同步这些线程可能会引入较大的开销。过多的线程可能导致调度器和同步机制的开销增加,从而影响程序性能。
4️⃣数据并行性:
GPU 是通过执行大量的线程来实现高度并行的计算。然而,线程数量过多可能导致数据并行性不足,因为可能无法充分填充 GPU 的执行单元。
5️⃣硬件架构的限制:
不同的 GPU 架构对于 block 中线程数量有硬件限制。超出这些限制可能会导致性能下降。
综合考虑以上因素,选择适当数量的线程以充分利用 GPU 硬件资源,并避免过多的开销是 GPU 编程中的一个重要优化策略。这通常需要根据具体的硬件架构和任务特性进行调整。
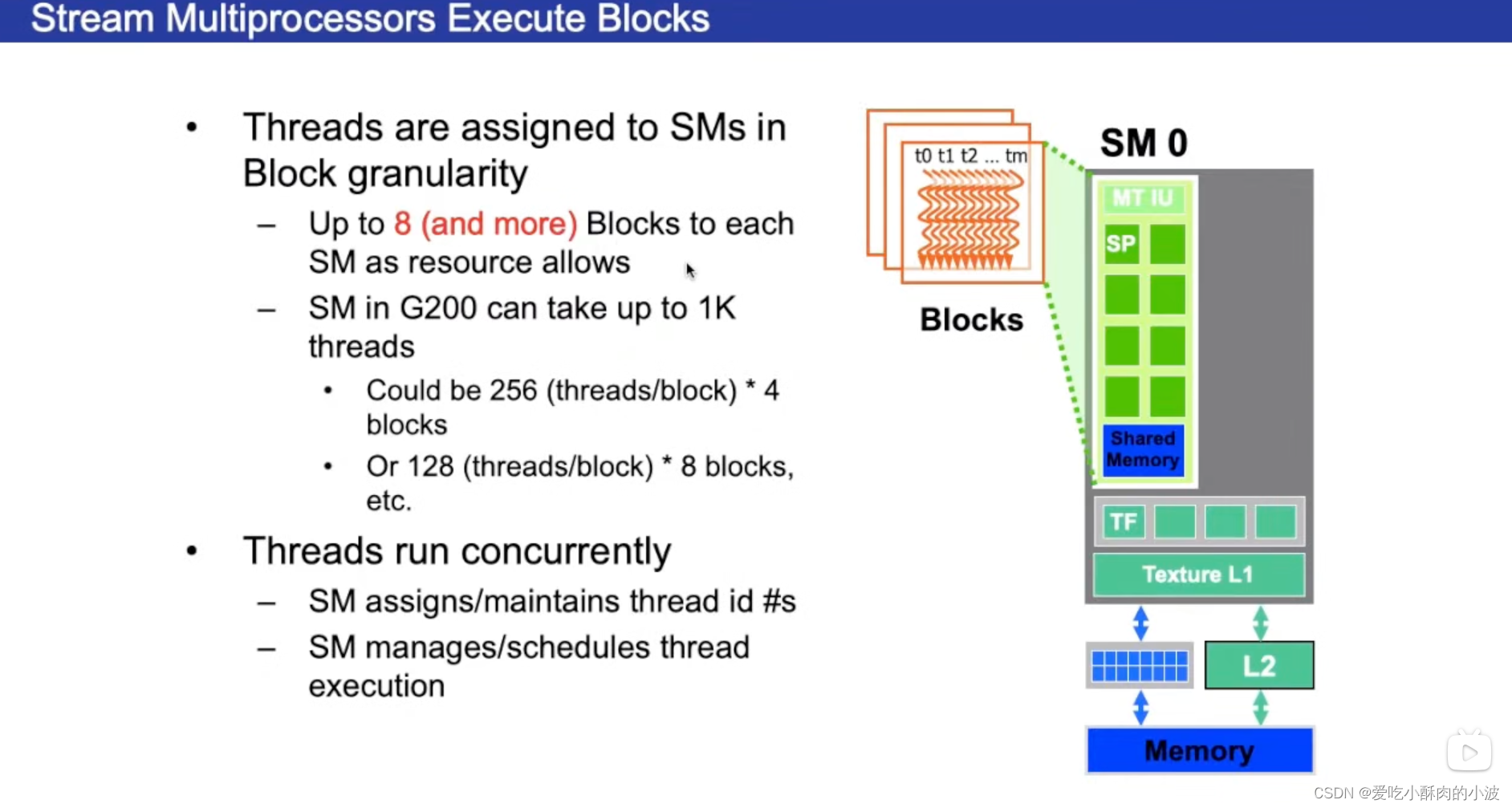
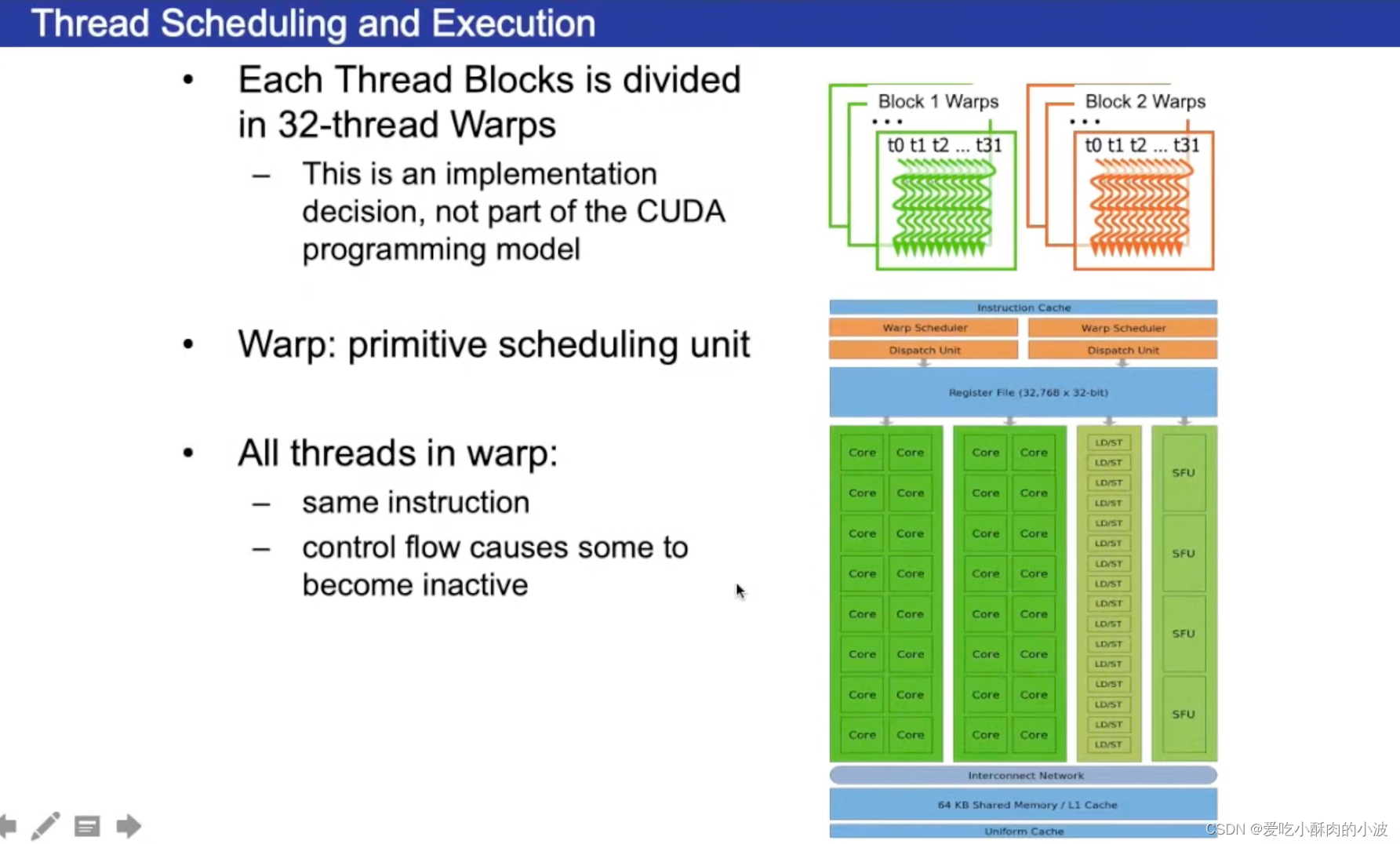
在设计程序时要尽量满足每个warp执行的是相同的指令,否则执行的效率会降低。

warp的切换是没有开销的,它依赖于硬件的调度器和算法的判断,可以执行的warp会被放在可执行的队列中,然后按照优先级进行执行。

写GPU程序时要尽量使它的并行性得到发挥,访问GPU显存时会有一些要求,如内存对齐、避免指令分支等。
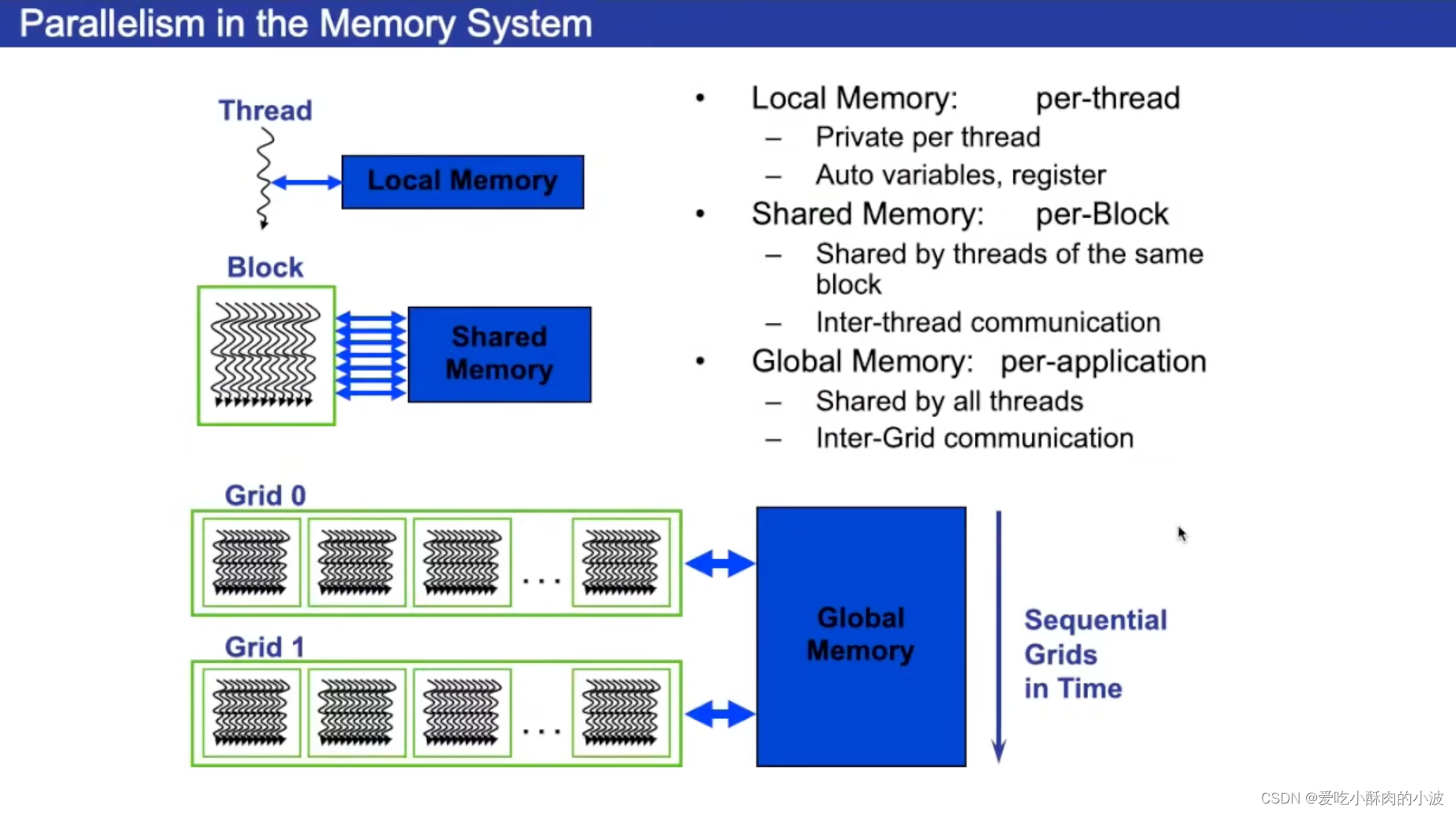


不同的GPU含有的寄存器数量是未知的。如果给GPU总共64KB的寄存器空间,每个block设计4KB的寄存器空间,那最多只能有16个block。
也就是每个块需要的寄存器大小越大,那么能分割的块越小,这样会降低程序的并行度。因此每个块要尽量少使用寄存器,这样让更多的块处于活跃,可以减少块相互切换的开销的。


共享字节有自己的划分方式,每4B划分成一个bank,上图中是16个bank。
如果多个thread访问不同的bank可以并行进行;如果是多个thread访问同一个bank,那么就会有冲突,访问就是顺序进行的。这样的话,原本一个时钟周期能完成的事情,需要多个时钟周期才能完成,性能会有所下降。
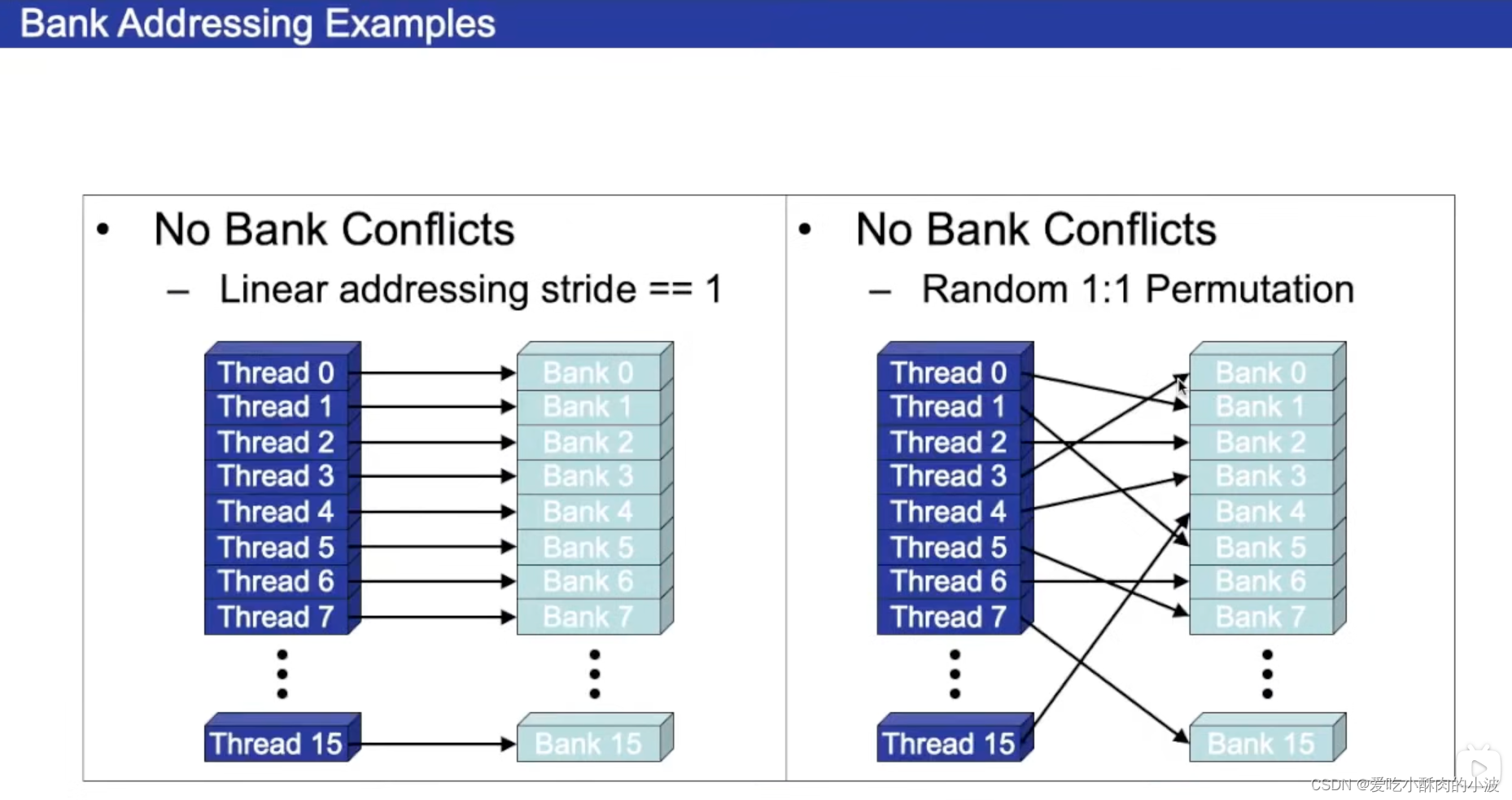
⬆️thread没有冲突的访问bank的情况,一个时钟周期内就能完成所有的访问。
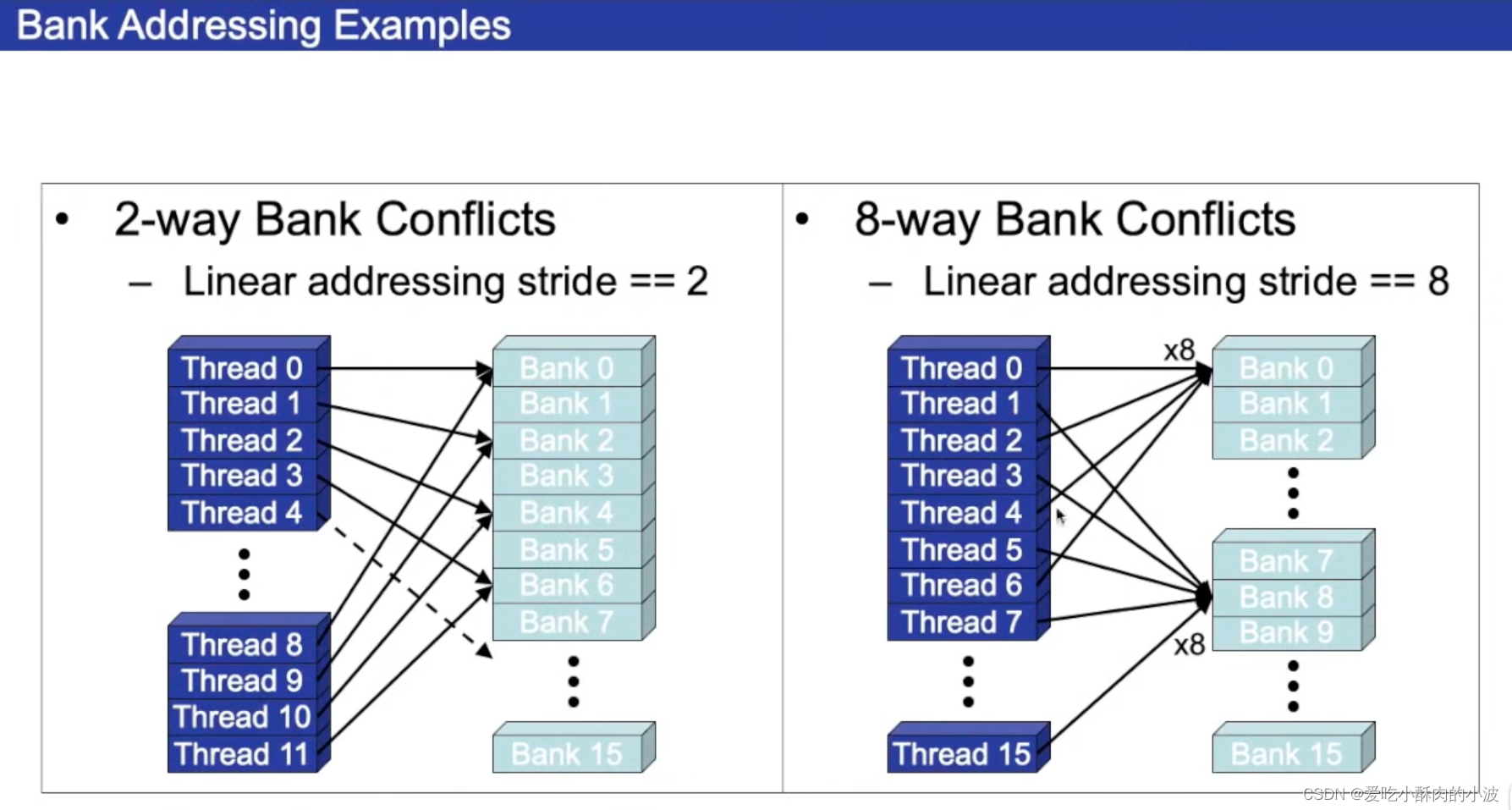
⬆️thread有冲突的访问bank的情况,一个时钟周期内无法完成所有的访问,需要多个时钟周期(左边需要2个时钟周期,右边需要8个时钟周期)。
这是以前的GPU,现在的GPU可以通过一次访问,然后广播访问bank的数据解决,减少访问的时钟周期。

如何实现并行计算的例子
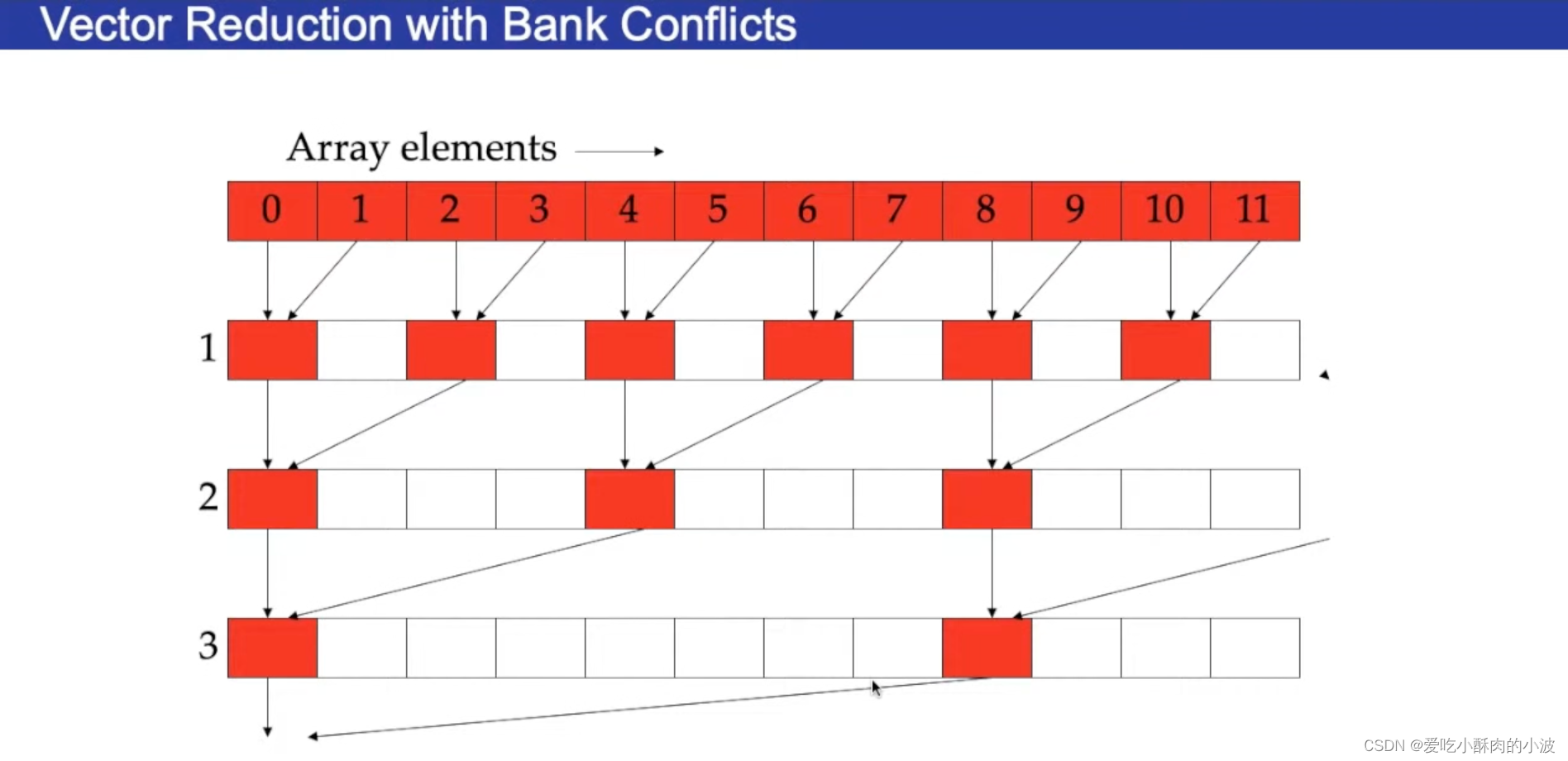
⬆️这种计算的方式有可能造成访问bank时的冲突

⬆️这种计算方式不会造成访问bank时的冲突

















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











