







博客写到一半发现有篇讲的很清楚,直接化缘了
https://www.jianshu.com/p/9f113adc0c50
https://zhuanlan.zhihu.com/p/111068310
Policy gradient
强化学习的目标:学习到一个策略
π
θ
(
a
∣
s
)
\pi\theta(a|s)
πθ(a∣s)来最大化期望回报。
一种直接的方法就是在策略空间中直接搜索来得到最优策略,这种方法称为策略搜索(Policy Search)。策略搜索的本质是优化问题,可以分为基于梯度的优化和无梯度的优化,策略搜索和基于值函数的方法相比,策略搜索可以不需要值函数,直接优化策略。参数化的策略能处理连续状态和动作,可以直接学出随即性策略。策略梯度(Policy Gradient)是一种基于梯度的强化学习方法。假设
π
θ
(
a
∣
s
)
\pi\theta(a|s)
πθ(a∣s)是一个关于θ的连续可微函数,可以用梯度上升的方法来优化参数θ使得目标函数
f
(
θ
)
f(\theta)
f(θ)最大。
简单推导
trajectory
ι
=
{
s
1
,
a
1
,
s
2
,
a
2
,
.
.
.
s
ι
,
a
ι
}
\iota=\{s_1,a_1,s_2,a_2,...s_\iota,a_\iota\}
ι={s1,a1,s2,a2,...sι,aι}
p
θ
=
p
(
s
1
)
p
θ
(
a
1
∣
s
1
)
p
θ
(
s
2
∣
s
1
,
a
1
)
p
θ
(
a
2
∣
s
2
)
p
θ
(
s
3
∣
s
2
,
a
2
)
.
.
.
=
p
(
s
1
)
∑
ι
t
=
1
p
θ
(
a
ι
∣
s
ι
)
p
(
s
ι
+
1
∣
s
ι
,
a
ι
)
p_\theta=p(s_1)p_\theta(a_1|s_1)p_\theta(s_2|s_1,a_1)p_\theta(a_2|s_2)p_\theta(s_3|s_2,a_2)...=p(s_1)\underset{t=1}{\overset{\iota}{\sum}}p_\theta(a_\iota|s_\iota)p(s_{\iota+1}|s_\iota,a_\iota)
pθ=p(s1)pθ(a1∣s1)pθ(s2∣s1,a1)pθ(a2∣s2)pθ(s3∣s2,a2)...=p(s1)t=1∑ιpθ(aι∣sι)p(sι+1∣sι,aι)
这里的 p θ p_\theta pθ表示的是策略,也就是在什么状态下该做什么动作,而 p p p是状态转移概率。
For each trajectory: Reward
R
θ
=
R
(
ι
)
R_\theta=R(\iota)
Rθ=R(ι)
Expeted Reward:
R
θ
‾
=
∑
ι
R
(
ι
)
p
θ
\overline{R_\theta}={\overset{\iota}{\sum}}R(\iota)p_\theta
Rθ=∑ιR(ι)pθ
我们希望最大化期望,使用梯度上升的方法。

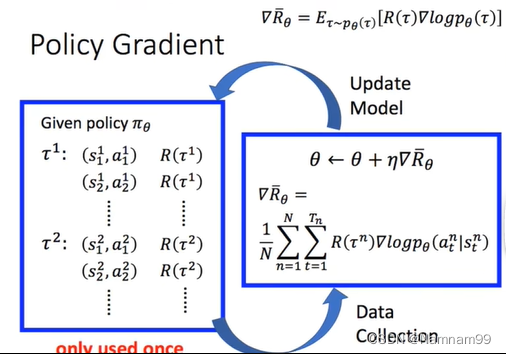
给定一个策略,在和环境互动之后产生多条轨迹,以及奖励,之后将数据集收集起来之后,求
R
θ
‾
\overline{R_\theta}
Rθ的梯度,之后更新参数,得到新的策略。















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









