






前言
上一片文章对LSS进行了解析,自LSS诞生至今,已有相当多针对其进行改进的工作,本文将进行解析的BEVDepth就是其中之一,其整体框架与LSS保持一致,在一些关键点上进行了改进,下面将一一进行剖析。
论文:BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
代码:https://github.com/Megvii-BaseDetection/BEVDepth
相关解析文章:
【BEV】学习笔记之BEVDepth(原理+代码)
概述
BEVDepth整体架构如下图所示:
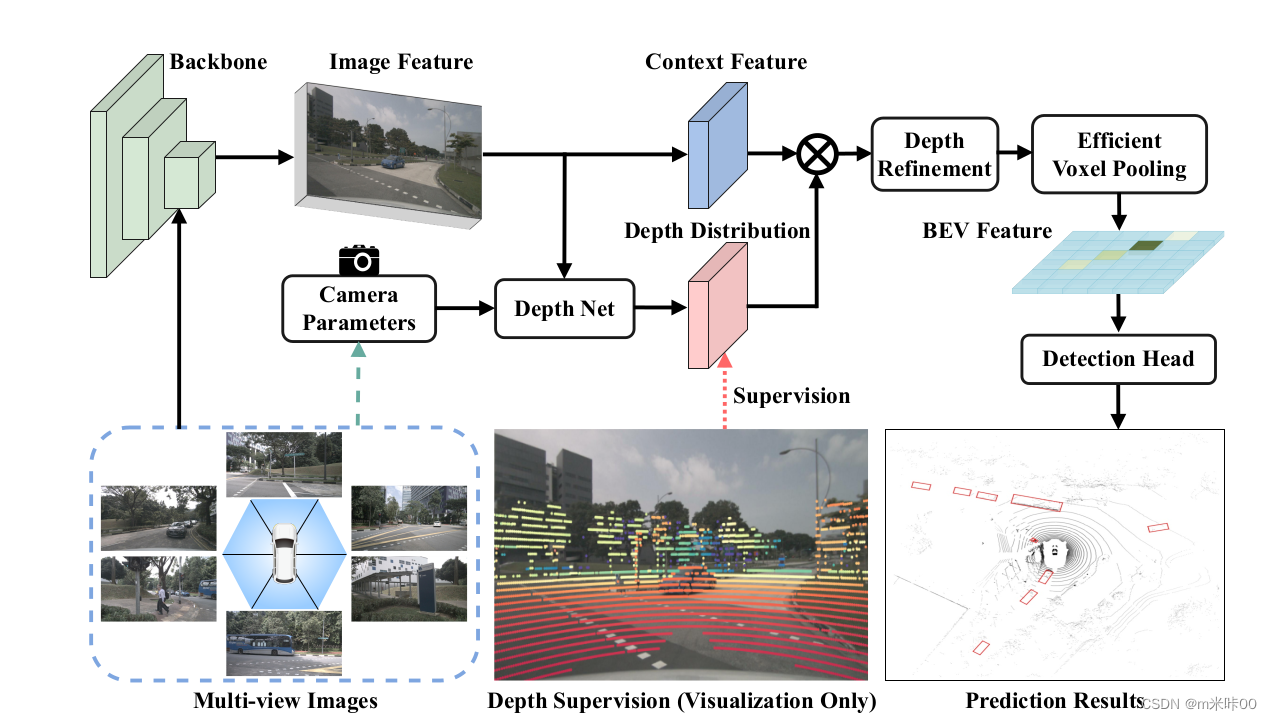
通过对LSS的分析,作者发现了几个可以改进的点,如下:
1、在LSS中,lift步骤中的单目深度估计不够准确,在训练过程中,对于这部分的修正来自于最终BEV检测结果的误差回传,在经过整个涉及坐标转换的回传过程后,这部分修正结果已经不够准确,导致前端网络深度估计能力不足。因此,BEVDepth增加了一个DepthNet,用激光雷达数据对其进行直接监督训练,提高其深度估计能力。
2、LSS整个过程没有使用相机内外参,使得整个网络对于相机的空间位置没有感知。BEVDepth的DepthNet增加了相机参数作为输入(实际实现中,在提取特征过程中也增加了相机参数作为输入),增加网络对于相机的空间感知能力
3、车辆运动过程中存在震动,可能导致相机与车辆相对位置存在偏移,LSS中提取特征与关联特征的部分网络输入是固定的,可能无法适应这种外参变化导致性能下降。DepthNet的最后一部增加了DCN模块,使得网络能够自适应相机位置的变化。
4、LSS使用单帧数据,可改进为使用多帧数据融合再进行分割。
5、LSS的voxel pooling部分性能可以得到进一步优化。BEVDepth中voxel pooling部分使用cuda进行加速。
DepthNet解析
DepthNet是BEVDepth的一个核心改进点,先来看看整体网络结构(图片来自开头的参考文章,侵删):
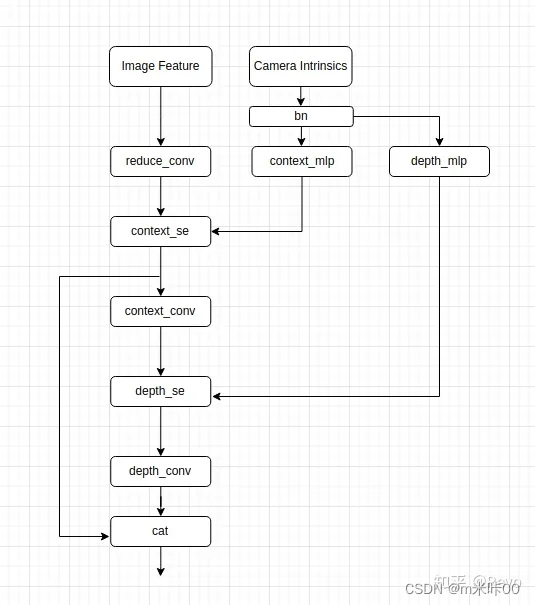
CA(Camera Awareness)
可以清晰的看到,相机参数两次参与了相关的运算,一次是在提取图像特征之前,一次是生成最终的深度特征之前,结合代码来看看相机参数如何被代入使用:
def forward(self, x, mats_dict):
intrins = mats_dict['intrin_mats'][:, 0:1, ..., :3, :3]//提取内参3*3矩阵
batch_size = intrins.shape[0]
num_cams = intrins.shape[2]
ida = mats_dict['ida_mats'][:, 0:1, ...]//数据扩增导致的图像变化矩阵
sensor2ego = mats_dict['sensor2ego_mats'][:, 0:1, ..., :3, :]//注意这里是相机到key frame ego的转换矩阵
bda = mats_dict['bda_mat'].view(batch_size, 1, 1, 4,
4).repeat(1, 1, num_cams, 1, 1)
mlp_input = torch.cat(
[
torch.stack(
[
intrins[:, 0:1, ..., 0, 0],//fx
intrins[:, 0:1, ..., 1, 1],//fy
intrins[:, 0:1, ..., 0, 2],//cx
intrins[:, 0:1, ..., 1, 2],//cy
ida[:, 0:1, ..., 0, 0],
ida[:, 0:1, ..., 0, 1],
ida[:, 0:1, ..., 0, 3],
ida[:, 0:1, ..., 1, 0],
ida[:, 0:1, ..., 1, 1],
ida[:, 0:1, ..., 1, 3],
bda[:, 0:1, ..., 0, 0],
bda[:, 0:1, ..., 0, 1],
bda[:, 0:1, ..., 1, 0],
bda[:, 0:1, ..., 1, 1],
bda[:, 0:1, ..., 2, 2],
],
dim=-1,
),
sensor2ego.view(batch_size, 1, num_cams, -1),
],
-1,
)//把内参与数据扩增导致的变换矩阵中有效数据摊平为一维数组,每个相机为共27个数据
mlp_input = self.bn(mlp_input.reshape(-1, mlp_input.shape[-1]))//做一次bn
x = self.reduce_conv(x)
context_se = self.context_mlp(mlp_input)[..., None, None]//得到的相机27维数据进一次MLP,使其在维度上与后面提取特征的channel数目一致
context = self.context_se(x, context_se)//将提取的特征与提取后的相机数据融合,实际上是将context_se与x在channel维度相乘
context = self.context_conv(context)//再经过一次卷积得到图像特征
depth_se = self.depth_mlp(mlp_input)[..., None, None]//同上,将相机27维数据进一次MLP,使其在维度上与后面提取深度特征的channel数目一致
depth = self.depth_se(x, depth_se)//融合
depth = self.depth_conv(depth)//卷积得到深度分布
return torch.cat([depth, context], dim=1)//将深度分布与图像特征cat后输出
DR(Depth Refinement)
实际上就是在深度提取的部分增加了DCN模块,增大感受野以及让其自适应数据的变化。
class DepthNet(nn.Module):
def __init__(self, in_channels, mid_channels, context_channels,
depth_channels):
super(DepthNet, self).__init__()
self.reduce_conv = nn.Sequential(
nn.Conv2d(in_channels,
mid_channels,
kernel_size=3,
stride=1,
padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
)
//以下为网络核心模块的构建
self.context_conv = nn.Conv2d(mid_channels,
context_channels,
kernel_size=1,
stride=1,
padding=0)
self.bn = nn.BatchNorm1d(27)
self.depth_mlp = Mlp(27, mid_channels, mid_channels)//这里可以看到MLP输出维度与SE模块输入维度匹配,均为mid_channels,可自定义配置
self.depth_se = SELayer(mid_channels) # NOTE: add camera-aware
self.context_mlp = Mlp(27, mid_channels, mid_channels)
self.context_se = SELayer(mid_channels) # NOTE: add camera-aware
self.depth_conv = nn.Sequential(
BasicBlock(mid_channels, mid_channels),
BasicBlock(mid_channels, mid_channels),
BasicBlock(mid_channels, mid_channels),
ASPP(mid_channels, mid_channels),
build_conv_layer(cfg=dict(//在三个残差模块后接一个DCN模块
type='DCN',
in_channels=mid_channels,
out_channels=mid_channels,
kernel_size=3,
padding=1,
groups=4,
im2col_step=128,
)),
nn.Conv2d(mid_channels,
depth_channels,
kernel_size=1,
stride=1,
padding=0),
)
DL(Depth Loss)
这一块比较简单,不展开来讲了,使用激光雷达点云数据,与图像对齐后得到每个图像点深度,然后用以对DepthNet进行训练。在代码中主要涉及两个部分,一个在NuscDetDateset中的数据准备部分进行了点云的准备与对齐,另一个是在 BaseLssFPN类中对训练部分进行了相关处理。
多帧融合(Multi-Frame)
BEVDepth中对于多帧的处理,是将数据集以key frame为间隔切割为多个sweeps,每个sweep头帧为key frame,逐帧进行前向传播得到每一帧的bev feature,最后进行融合后分割。
def forward(...):
...
batch_size, num_sweeps, num_cams, num_channels, img_height, \
img_width = sweep_imgs.shape
key_frame_res = self._forward_single_sweep(//先对第一帧进行BEV feature生成
0,
sweep_imgs[:, 0:1, ...],
mats_dict,
is_return_depth=is_return_depth)
if num_sweeps == 1:
return key_frame_res //num_sweeps设置为1即不采用多帧融合策略
key_frame_feature = key_frame_res[
0] if is_return_depth else key_frame_res
ret_feature_list = [key_frame_feature]
for sweep_index in range(1, num_sweeps): //对每个sweep进行BEV feature生成
with torch.no_grad():
feature_map = self._forward_single_sweep(
sweep_index,
sweep_imgs[:, sweep_index:sweep_index + 1, ...],
mats_dict,
is_return_depth=False)
ret_feature_list.append(feature_map)
if is_return_depth:
return torch.cat(ret_feature_list, 1), key_frame_res[1]
else:
return torch.cat(ret_feature_list, 1) //将所有BEV feature融合,准备进行分割
在以上过程中,有一个细节需要注意,就是不同sweep的BEV feature是在不同坐标系下的,只有将其放在同一坐标系才能顺利融合分割,这个操作在以下代码实现:
def _forward_single_sweep(...):
...
geom_xyz = self.get_geometry(
mats_dict['sensor2ego_mats'][:, sweep_index, ...],
mats_dict['intrin_mats'][:, sweep_index, ...],
mats_dict['ida_mats'][:, sweep_index, ...],
mats_dict.get('bda_mat', None),
)
...
在每个sweep的splate操作中,将点云转换到ego坐标系的时候使用的是mats_dict[‘sensor2ego_mats’][:, sweep_index, …],在数据集构建的代码中可以看到:
def get_image(...):
...
sweepsensor2keyego = global2keyego @ sweepego2global @\
sweepsensor2sweepego //根据每个sweep ego在全局坐标系的位姿、sensor在当前ego位姿及key frame ego在全局位姿得到每个sweep中每个sensor到key frame ego的位姿
sensor2ego_mats.append(sweepsensor2keyego)
...
sensor2ego保存的实际上已经是每个sweep每个相机到key frame ego的转换矩阵,因此在每个sweep的BEV feature生成阶段已经转换到了key frame ego坐标系下。
结果
以上为BEVDepth的主要工作,论文也采用控制变量法测试了不同策略的实际效果,如下:
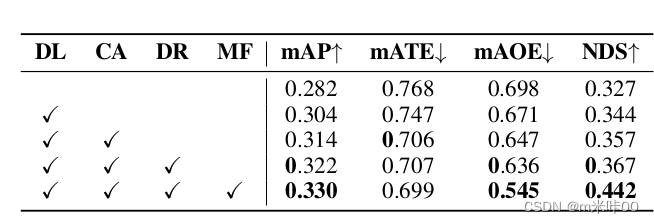
可以看出整体效果非常理想,不过看起来有些过于理想了,后面有机会将实际进行相应测试,看看能否复现相关结果。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









