






前言
自Tesla公开BEV感知已过去数年,该项技术得到高速发展,国内诸多自动驾驶厂商与车厂快速跟进,部分走的快的头部玩家已对其进行了商业落地应用,相关技术的应用也逐步向整个工业界蔓延,因此,近段时间对BEV感知进行了整体的学习和研究,部分大佬对这篇论文已有了相当详尽且细致的解析,因此这里仅简单记录以下个人的理解,尽量保持全文的精练。
论文:Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
代码:https://github.com/nv-tlabs/lift-splat-shoot
相关解析文章:
LSS (Lift, Splat, Shoot) 论文+源码万字长文解析
一文读懂BEV自底向上方法:LSS 和 BEVDepth
概述
纯视觉的BEV感知本质上是通过采集多视角下的相机数据,基于相机间的外参以及相机内参,将不同视角下的观测特征关联从而得到物体深度,并将其转换到BEV视角下辅助机器或者车辆进行规划控制以及决策。相应实现的方法有很多,传统算法可以直接对多视角相机采集到的图像进行特征关联,生成视差图,再基于内外参计算得到深度,这也是双目视觉的基本原理;采用深度学习的方法则更加简单粗暴,往往是直接通过网络提取图像特征,之后采用其他网络估计深度或者转换到相同的空间中进行特征关联后再输出深度等方法。
本文采用的方法也类似,其核心流程如下图所示:

- 1、基于原图用一个特征提取网络提取图像特征,获取图像坐标下视锥体内每个点的特征
- 2、获取图像坐标下视锥体每个点的三维坐标,与第一步中的点特征一一对应
- 3、将视锥体内每个点(坐标及特征)利用内外参转换到ego即车辆坐标系下
- 4、对所有图像转换到ego坐标系的点进行处理,对位于同一voxel中的特征进行累加得到该voxel的唯一特征
- 5、将ego坐标系下得到的所有特征输入到一个网络中得到BEV最终结果
- 6、将BEV结果进行处理后输入到规划网络实现motion planning
整体流程大致如上文所述,下面拆解进行分析。
Lift
对应以上1、2两个步骤,如下图所示:
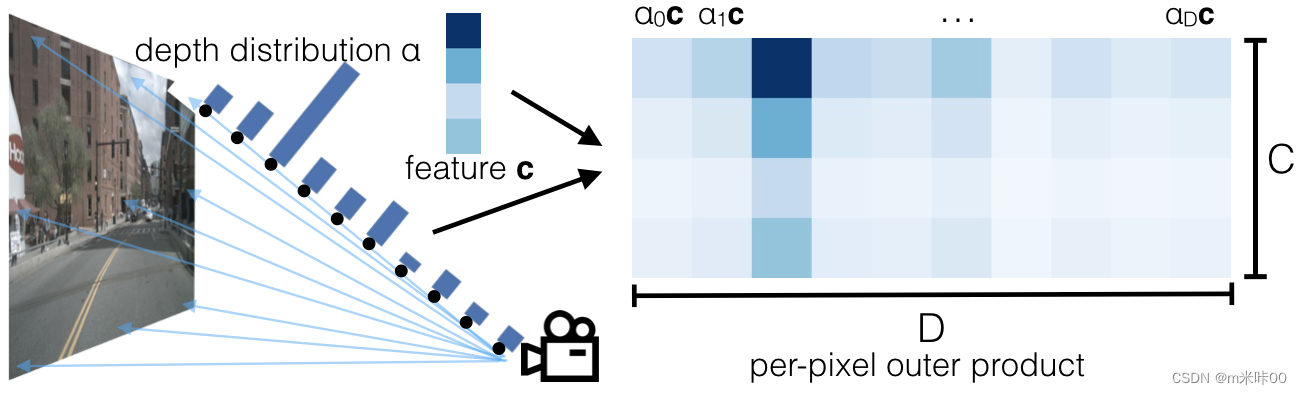
对应代码如下:
def create_frustum(self):
# make grid in image plane
ogfH, ogfW = self.data_aug_conf['final_dim']
fH, fW = ogfH // self.downsample, ogfW // self.downsample //所有操作都不是基于原图分辨率,而是基于下采样后的特征图分辨率的,可以大幅减少计算量
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)//生成z轴深度坐标0-40
D, _, _ = ds.shape
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)//生成x轴坐标
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)//生成y轴坐标
# D x H x W x 3
frustum = torch.stack((xs, ys, ds), -1)//将三轴坐标堆叠,构成视锥体点云,注意,这个点云坐标是基于后处理后的图像坐标系
return nn.Parameter(frustum, requires_grad=False)
def get_cam_feats(self, x):
"""Return B x N x D x H/downsample x W/downsample x C
"""
B, N, C, imH, imW = x.shape
x = x.view(B*N, C, imH, imW)
x = self.camencode(x)//网络提取特征,特征已经是经过下采样的,与上面的视锥体分辨率匹配
x = x.view(B, N, self.camC, self.D, imH//self.downsample, imW//self.downsample)
x = x.permute(0, 1, 3, 4, 5, 2)
return x
网络提取特征的部分就略过了,主要就是使用Efficientnet-B0主干网络提取特征,最后进行后两层特征融合,再进行卷积输出每个点105维度的特征,其中前41维代表深度方向的深度概率分布,后64维代表该点特征表示,对深度概率分布和点特征进行外积得到视锥体中每个点的特征,即[41,64]维矩阵。
Splate
对应以上3、4两个步骤,代码如下:
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""Determine the (x,y,z) locations (in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/downsample x W/downsample x 3
"""
B, N, _ = trans.shape
# undo post-transformation, 前文讲过,视锥体点云在后处理后的图像坐标系下,因此需要反变换到原图坐标系
# B x N x D x H x W x 3
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))
# cam_to_ego, 使用外参将图像坐标系点云转到ego坐标系
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5)
combine = rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3)
return points
def voxel_pooling(self, geom_feats, x):
B, N, D, H, W, C = x.shape
Nprime = B*N*D*H*W
# flatten x
x = x.reshape(Nprime, C)//摊平特征
# flatten indices
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long()//空间坐标转体素坐标
geom_feats = geom_feats.view(Nprime, 3)
batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,
device=x.device, dtype=torch.long) for ix in range(B)])
geom_feats = torch.cat((geom_feats, batch_ix), 1)//每个点加入batch index信息
# filter out points that are outside box
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
x = x[kept]
geom_feats = geom_feats[kept]
# get tensors from the same voxel next to each other,下面整个重新排序,在同一个voxel、同一batch的rank相同,同一voxel不同batch的相邻,保证时间和空间相近的特征聚在一起
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\
+ geom_feats[:, 1] * (self.nx[2] * B)\
+ geom_feats[:, 2] * B\
+ geom_feats[:, 3]
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]
# cumsum trick,同一voxel同一batch的特征累加,并只保留累加后的特征,这里同时采用了一些加速训练的trick
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks)
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)
# griddify (B x C x Z x X x Y),调整数据保存形式
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x
# collapse Z
final = torch.cat(final.unbind(dim=2), 1)
return final
至此,就已经得到了BEV下的特征图了。
Shoot
对应以上5、6两个步骤,实际上,经过Lift和Splate两布已经得到了BEV下特征图,只用来做感知的话,对特征进行一些多尺度特征提取、融合并且增加一个Head输出最终语义结果就可以了,对应代码:
class BevEncode(nn.Module):
def __init__(self, inC, outC):
super(BevEncode, self).__init__()
trunk = resnet18(pretrained=False, zero_init_residual=True)//主干基于resnet-18进行
self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = trunk.bn1
self.relu = trunk.relu
self.layer1 = trunk.layer1
self.layer2 = trunk.layer2
self.layer3 = trunk.layer3
self.up1 = Up(64+256, 256, scale_factor=4)
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear',
align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, outC, kernel_size=1, padding=0),
)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x1 = self.layer1(x)
x = self.layer2(x1)
x = self.layer3(x)
x = self.up1(x, x1)
x = self.up2(x)
return x
论文中做了一些额外工作,基于生成的cost map,生成K条模板轨迹,将轨迹在cost map上计算cost指,并进行softmax后得到每条轨迹的打分,从而进行路径规划,这里主要关注感知部分,这里就不展开讲了。















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









