








下载不同的digest 模型,狗模型。
TensorRT下载地址:https://developer.nvidia.com/nvidia-tensorrt-download
TesnsoRT介绍文档:https://devblogs.nvidia.com/tensorrt-3-faster-tensorflow-inference/
TensorRT开发者指南:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
TensorRT样例代码:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#samples
接下来,下载并解压训练好的模型到Jetson里面。通过浏览器访问您的DIGITS服务器,然后查看您训练好的DetectNet-COCO-Dog 模型。在Select Model里面可以选择我们训练的模型,我们可以选择固定步数训练出来的结果来下载,通常最多的那个效果比较好。点击Download Model下载模型。
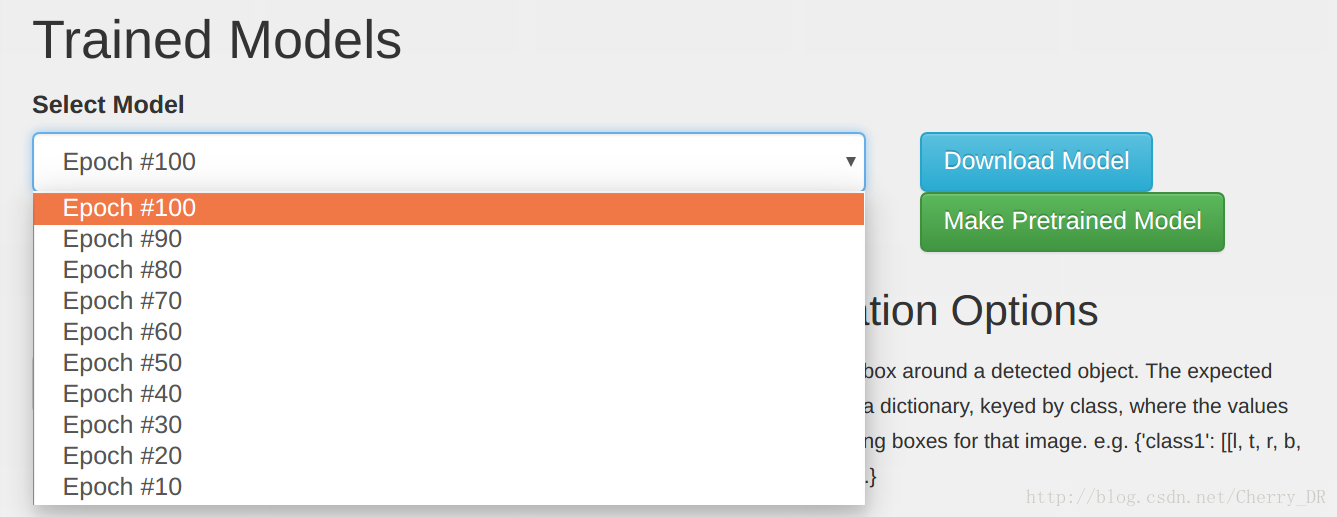
如果你的Jetson不能用浏览器连接到DIGITS服务器,您可以先下载到一个本地,然后用SCP或者U盘传到Jetson上。
解压命令如下:
tar -xzvf 20170504-190602-879f_epoch_100.0.tar.gz- 1
DetectNet Patches for TensorRT
在DetecNet prototxt里面有一个python聚类层无法直接在TensorRT上面使用,所以需要在deploy.prototxt里面删除。在这个项目中,detectNet 类处理聚类来代替python。
在deploy.prototxt的最后,删除名字为cluster的层:
layer {
name: "cluster"
type: "Python"
bottom: "coverage"
bottom: "bboxes"
top: "bbox-list"
python_param {
module: "caffe.layers.detectnet.clustering"
layer: "ClusterDetections"
param_str: "640, 640, 16, 0.6, 2, 0.02, 22, 1"
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
删除了这个python层,训练完的模型才能被TensorRT使用。
Processing Images from the Command Line on Jetson
利用detectNet 和 TensorRT处理测试图像,可以使用 detectnet-console 程序。 detectnet-console 命令行要输入检测图片的路径作为输入,以及输出图片的路径(检测框会水印在输出图片的路径上)。我们的repo中会包含一些测试图片。
定义你的从DIGITS上面下来的模型,可以使用下面的语法来执行detectnet-console。首先,你可以把之前训练完的模型的路径设置为$NET :
$ NET=20170504-190602-879f_epoch_100
$ ./detectnet-console dog_0.jpg output_0.jpg \
--prototxt=$NET/deploy.prototxt \
--model=$NET/snapshot_iter_38600.caffemodel \
--input_blob=data \
--output_cvg=coverage \
--output_bbox=bboxes- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:如果你的网络层和DetecNet的层名字和默认的一样,the input_blob, output_cvg, and output_bbox这三个设置可以忽略。如果你的DetecNet的层的名字跟默认的不一样,那么这些命令行参数也可以自己设置。

Launching With a Pretrained Model
当然,你也可以加载这个repo中已经训练好的模型,你可以用第三个命令行参数来指定用这个模型来检测。
$ ./detectnet-console dog_1.jpg output_1.jpg coco-dog- 1
上面的命令就是用repo中的训练好的DetectNet-COCO-Dog模型来检测dog_1.jpg,然后将检测结果保存在output_1.jpg。如果你不想等待训练,你可以直接用这个方法。

Pretrained DetectNet Models Available
下面的这个表就是对应检测目标的模型,这些模型都在这个repo里里面下载好了(运行完cmake之后,模型就会在data/networks 的目录下),大家可以设置相对应的命令行参数来调用这些模型。
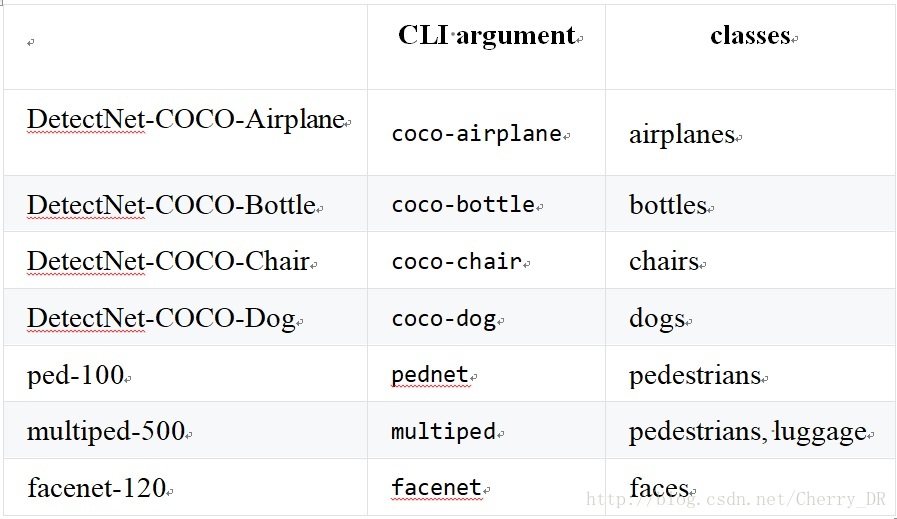
这些都是有python版本的。
Running Other MS-COCO Models on Jetson
我们来尝试使用一些其他的COCO模型。训练的数据是上面已经下载过的。上面训练狗的步骤,可以直接用于训练COCO中其他类别的模型。
$ ./detectnet-console bottle_0.jpg output_2.jpg coco-bottle- 1

$ ./detectnet-console airplane_0.jpg output_3.jpg coco-airplane- 1

Running Pedestrian Models on Jetson
这个repo中还包括了DetecNet训练好的检测人的模型。
pednet 和 multiped的模型可以识别行人,而facenet可以用来识别人脸。下面的例子就是在画面中的行人检测。

Multi-class Object Detection Models
当使用多个模型,对于包含行李箱或者包包的行人,第二类目标会用绿色的框标注出来
$ ./detectnet-console peds-003.jpg output-3.jpg multiped- 1
Running the Live Camera Detection Demo on Jetson
就像之前的例子,detectnet-camera会利用Jetson板载的摄像头进行实时视频的目标检测。可以利用命令行程序执行您想运行的网络:
$ ./detectnet-camera coco-bottle # detect bottles/soda cans in the camera
$ ./detectnet-camera coco-dog # detect dogs in the camera
$ ./detectnet-camera multiped # run using multi-class pedestrian/luggage detector
$ ./detectnet-camera pednet # run using original single-class pedestrian detector
$ ./detectnet-camera facenet # run using facial recognition network
$ ./detectnet-camera # by default, program will run using multiped- 1
- 2
- 3
- 4
- 5
- 6
注意:为了得到更好的性能,可以利用下面的脚本来增加Jetson的时钟限制
注意:默认使用的是Jetson的板载csi 摄像头。如果你想用自己的摄像头,可以更改detectnet-camera.cpp中的DEFAULT_CAMERA 的设置来更改。














 1528
1528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









