







Xlent 乱序排列模型,第一次听到这个名字的时候疑惑,乱序那不是句子都乱了吗,其实这正是利用了transform的跟token的位置无关性,但是句子中的token位置不同意义。所以每个token都带着位置embedding输入的。
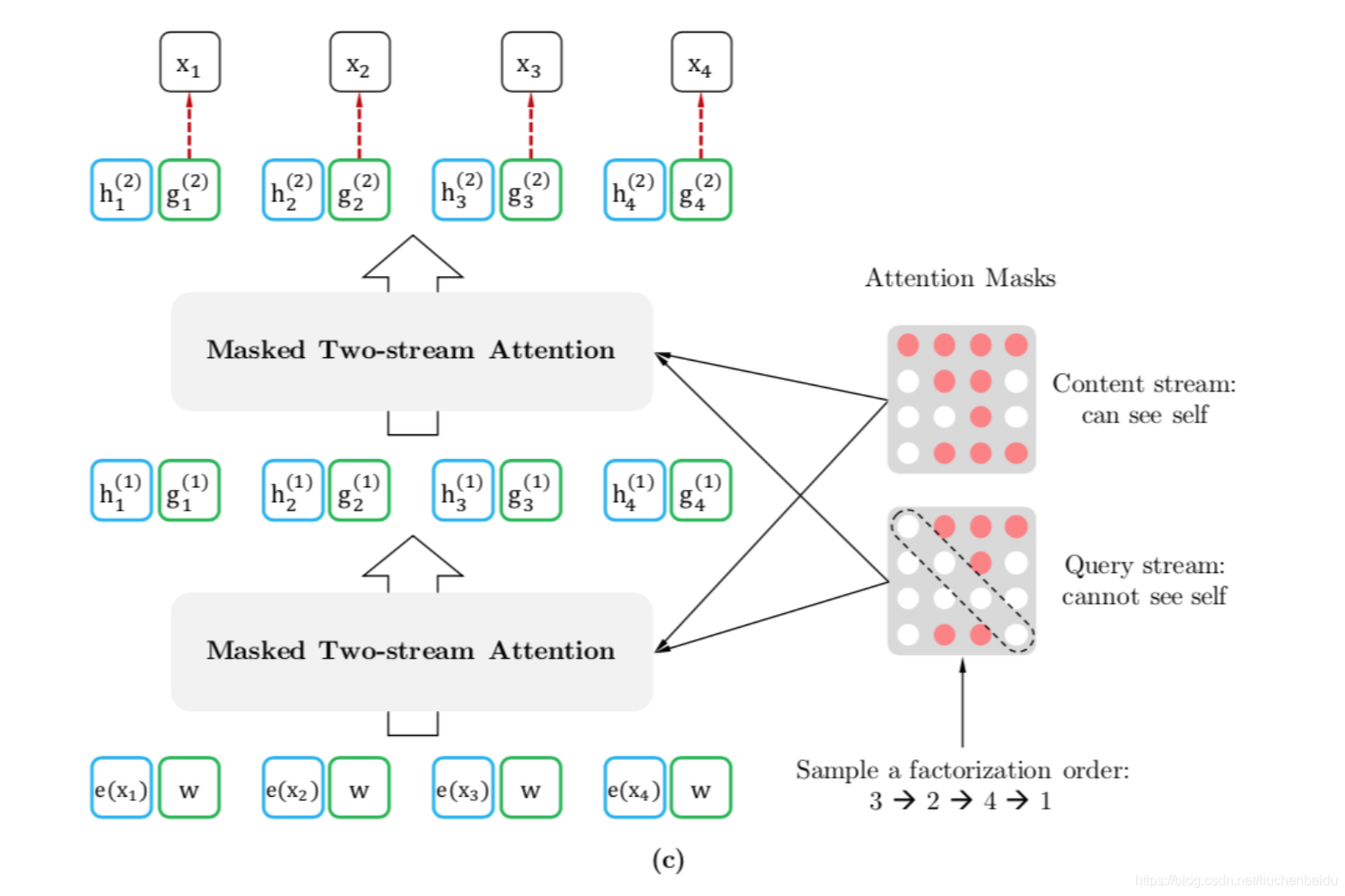
1.双流注意力,content和Query,2个流共享1套自注意力机制的参数,因此不会造成参数的增加。
2.解释两个图,attention Mask很多人看不懂。每一行都是token 1,2,3,4。
图示的序列是3-2-4-1,
content stream
就是token1 可以看到所有的content
第二行 token2,可以看到token3,和token2,第三行token3可以看到token3,第四行 token4可以看到token3,token2,token4
query stream,就是预测attention 通过其他token预测,所以不能看到自己。所有中间的全是白色 mask掉了
这样做的目的,就是用content生成hidden vector 用query 来预测。

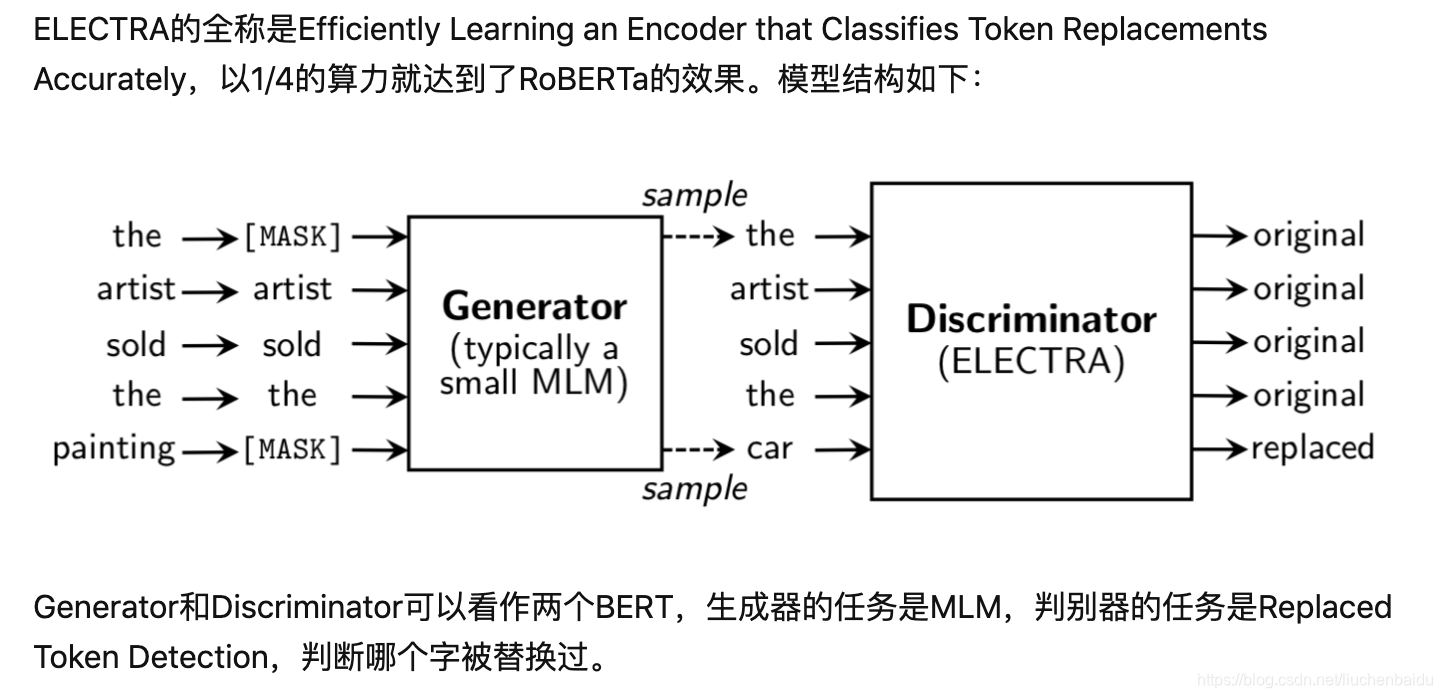
二 、Electra模型
优势充分训练,训练时间和训练样本大量减少。使用的时候只用Discriminator



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











