






最近在学习李航编写的《统计学习方法》一书,看到SVM这一章时遇到了一些困难,在翻阅很多资料之后对其有了一定的理解,所以打算写篇博客来记录一下,后面如果有时间也会把前面几章中的算法加以整理。在看这本书的同时大多加以参考hankcs在码农场中所写的机器学习系列文章,写的很不错,有理论分析也有代码实现,很适合机器学习入门者学习和理解。《统计学习方法》里讲述的太过理论化,假如很多东西我们直接当作已知定理去用可能会更容易理解。所以接下来就直接介绍一些结论,具体的推导可以参考原著或者这篇文章。
首先假设样本集线性可分,其实SVM就是找到一个划分超平面将不同类别样本分开,但是这样的超平面会有很多,我们要找到最鲁棒的那个,即对样本扰动的容忍最好,泛化能力最强的那个划分超平面。用下面的线性方程来表示划分超平面:
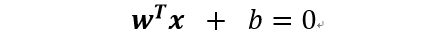
所以任何一个样本点到该平面的几何间隔为:
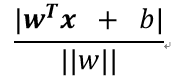
如果所有样本点都可以正确被分类,则我们假设所有点到超平面的距离均大于等于1(可以通过将w和b缩放的形式达到该目标),并且称距离唯一的点为支持向量,两个异类支持向量到划分超平面的距离之和
支持向量机SVM算法原理笔记1
最新推荐文章于 2023-11-27 16:00:00 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









