







 本文详细介绍了Hierarchical Attention Network (HAN)在文档分类中的应用,该模型基于GRU和Attention机制,分别对句子和单词的重要性进行建模,以提升文本分类的精确度。HAN模型包括词序列编码器、词级注意力层、句子编码器和句子级注意力层。此外,文章还提及了无Attention机制的前驱工作,并对比了两种模型的区别。
本文详细介绍了Hierarchical Attention Network (HAN)在文档分类中的应用,该模型基于GRU和Attention机制,分别对句子和单词的重要性进行建模,以提升文本分类的精确度。HAN模型包括词序列编码器、词级注意力层、句子编码器和句子级注意力层。此外,文章还提及了无Attention机制的前驱工作,并对比了两种模型的区别。
最近看了”Hierarchical Attention Network for Document Classification”一篇文章,也在网上找了一些资料结合理解,发现在此之前有篇文章跟他提出的模型架构基本相似,只不过不包含attention机制:“Document Modeling with Gated Recurrent Neural Network
for Sentiment Classification”,也就是说本篇论文是基于这篇论文作了一些改进的。所以这里主要结合两篇论文进行介绍文档的分层架构模型。
Non-Attention
第一篇文章主要是使用两个神经网络分别建模句子和文档,采用一种自下向上的基于向量的文本表示模型。首先使用CNN/LSTM来建模句子表示,接下来使用双向GRU模型对句子表示进行编码得到文档表示,这里论文中提到在情感分类任务中,GRU往往比RNN效果要好。模型架构如下图所示:
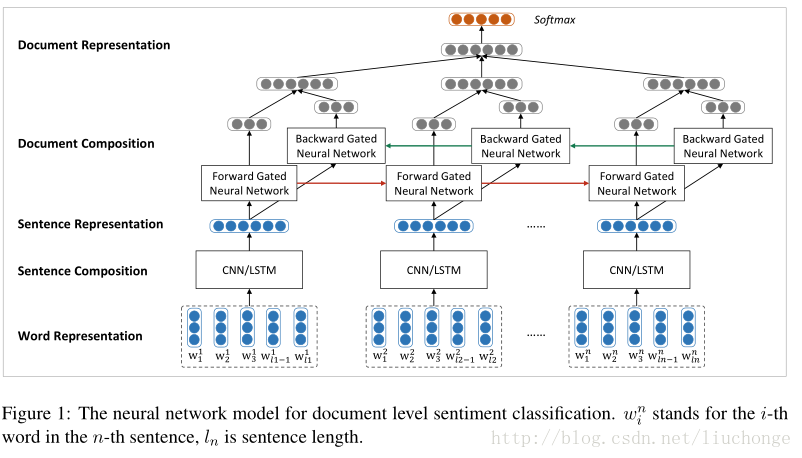
再上图中,词向量是从语料库中使用Word2vec模型训练出来的,保存在词嵌入矩阵中。然后使用CNN/LSTM模型学习句子表示,这里会将变长的句子表示成相同维度的向量,以消除句子长度不同所带来的不便。也就是说之后的GRU模型的输入是长度相同的句子向量。
卷积模型如下图所示,filter的宽度分别取1,2&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









