








 超级会员免费看
超级会员免费看


理论假设:
输入和输出的方差保存一致,这样就可以避免在信息传导过程中,出现梯度爆炸或者梯度消失的情况,利于训练。
条件:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
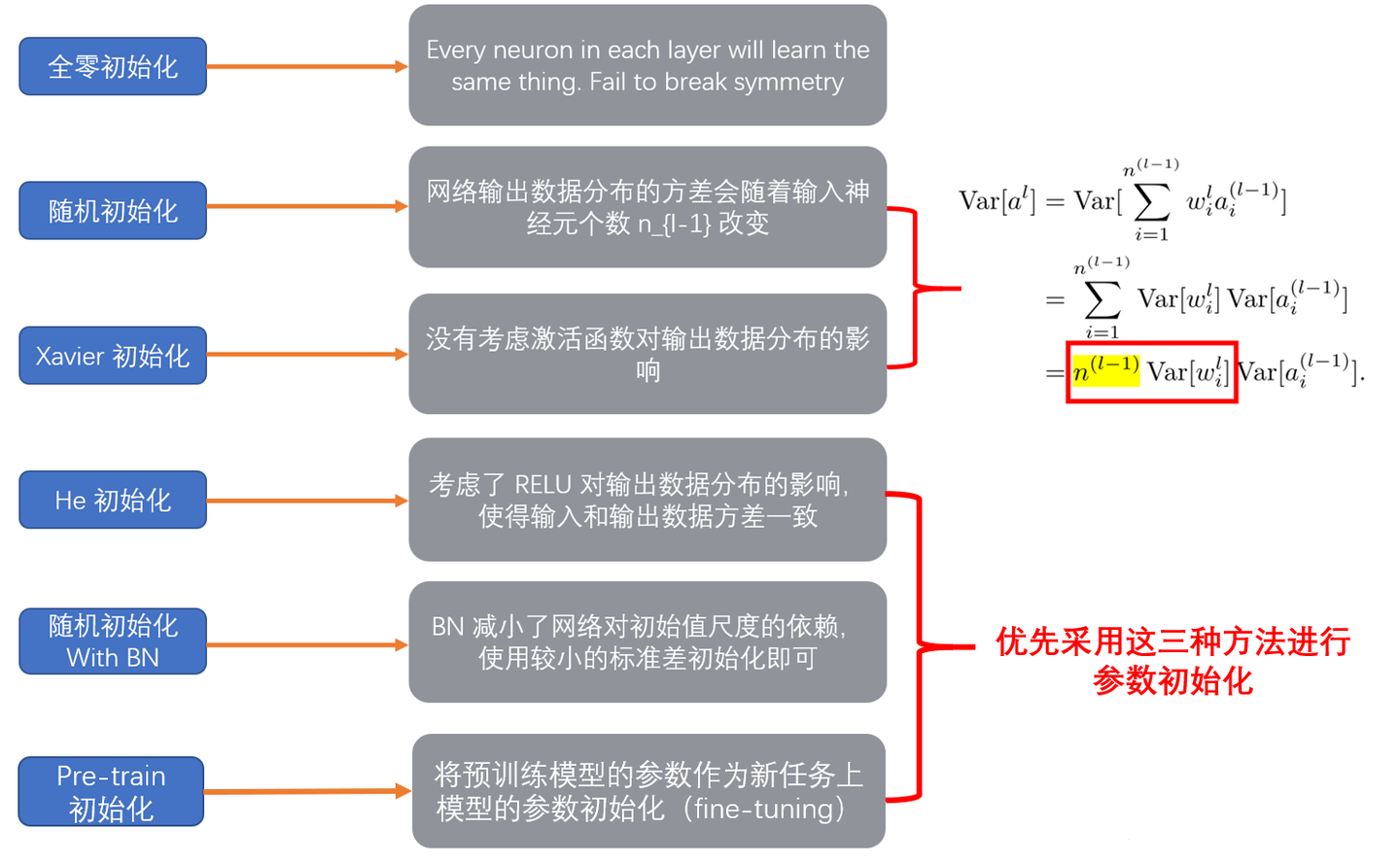
参数初始化的理想状态是参数正负各半,期望为0。
过大或者过小的初始化
如果权值的初始值过大,则会导致梯度爆炸,使得网络不收敛;过小的权值初始值,则会导致梯度消失,会导致网络收敛缓慢或者收敛到局部极小值。
如果权值的初始值过大,则loss function相对于权值参数的梯度值很大,每次利用梯度下降更新参数的时,参数更新的幅度也会很大,这就导致loss function的值在其最小值附近震荡。
而过小的初值值则相反,loss关于权值参数的梯度很小,每次更新参数时,更新的幅度也很小,着就会导致loss的收敛很缓慢,或者在收敛到最小值前在某个局部的极小值收敛了。
随机初始化
过小导致梯度消失,过大导致梯度爆炸。
随机初始化带有BN
BN可以将过大过小的数据都归一化到0-1分布,避免了梯度爆炸或梯度消失的情况。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 410
410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











