







初始化方案的选择至关重要,且初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。糟糕选择可能会导致我们在训练时遇到梯度爆炸或者梯度消失。
梯度消失
不稳定梯度会威胁到我们优化算法的稳定性。会存在梯度爆炸(gradient exploding)问题:参数更新过大,破环了模型的稳定收敛;梯度消失(gradient vanishing)问题:参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
sigmoid函数会导致梯度消失
%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],
legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
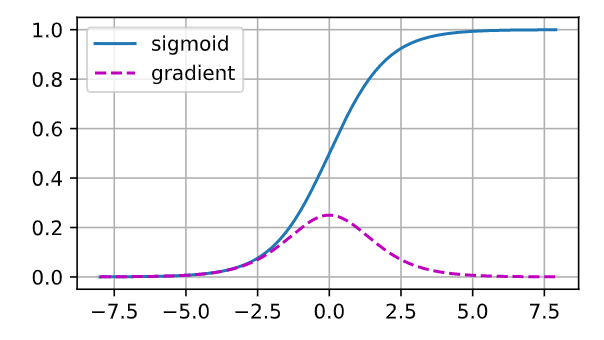
当sigmoid函数的输入很大或是很小时,它的梯度都会消失。此外当反向传播通过很多层时,除非我们在刚刚好的地方,这些sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。
梯度爆炸
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(100):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)
参数初始化
解决(或至少减轻)上述问题的一种方法是进行参数初始化, 优化期间的注意和适当的正则化也可以进一步提高稳定性。如果我们不指定初始化方法, 框架将使用默认的随机初始化方法,对于中等难度的问题,这种方法通常很有效。















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









