







Transformer详解
参考 The Illustrated Transformer
Github模型库:
Tensor2Tensor:Attention is all you need中给出的开源代码,实际包含了很多其他模型,不太好看源码
The Annotated Transformer:OpenNMT的相关作者给出的PyTorch代码分析,适合PyTorch的同学阅读
Kyubyong/transformer:Tensorflow版的Transformer,代码比较简洁,star星数2.8k,适合Tensorflow的同学阅读
模型原理
参数分析
典型参数(base):encoder 6层,decoder 6层,隐层512维,forward2048,多头8个,KV矩阵维度64(512/8),drop0.1
训练参数
1、embedding
2、每个encoder:QKV矩阵的W和b,FFN两层W和b,2个LayerNorm的权重
3、每个decoder:QKV矩阵的W和b,Q矩阵的W和b,FFN两层W和b,3个LayerNorm的权重
模型整体
6层的encoder(每个参数独立学习),最上层encoder的输出的K和V,作为6个decoder(每个参数独立学习)的中间attention层输入。encoder和decoder之间都是512维的vector list,list的长度在训练阶段定好。

encoder的组成,self-attention层是注意力层,每个词和上下文进行QKV的计算。FFN层对每个word,进行计算,共享一个权重。FFN比较简单,2层DNN,第一层维度为2048,后面加上ReLU层。公式为FFN(x) = max(0, xW1 + b1 )W2 + b2。FFN可以并行计算。

decoder的组成,类似于encoder,多一个中间attention层,叫做encoder-decoder attention层

输出层是一个DNN+Softmax,维度为词典大小,decoder的每一个位置输出共享一个参数。原文中提到,we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation,similar to [30]。即前后合用一个词典,DNN的权重为embedding weight,bias为0

encoder和decoder的输入都为word embedding + position embedding,word embedding为可训练的lookup table,乘以sqrt(64)?不知道为什么,position embedding固定函数产生(实验证明学习的和固定的效果差不多),可以scale到无限长的句子(?貌似作用不大,因为训练时最大长度已经设好,infer时不能增加,因为没有对应的QKV矩阵了)

注意力层
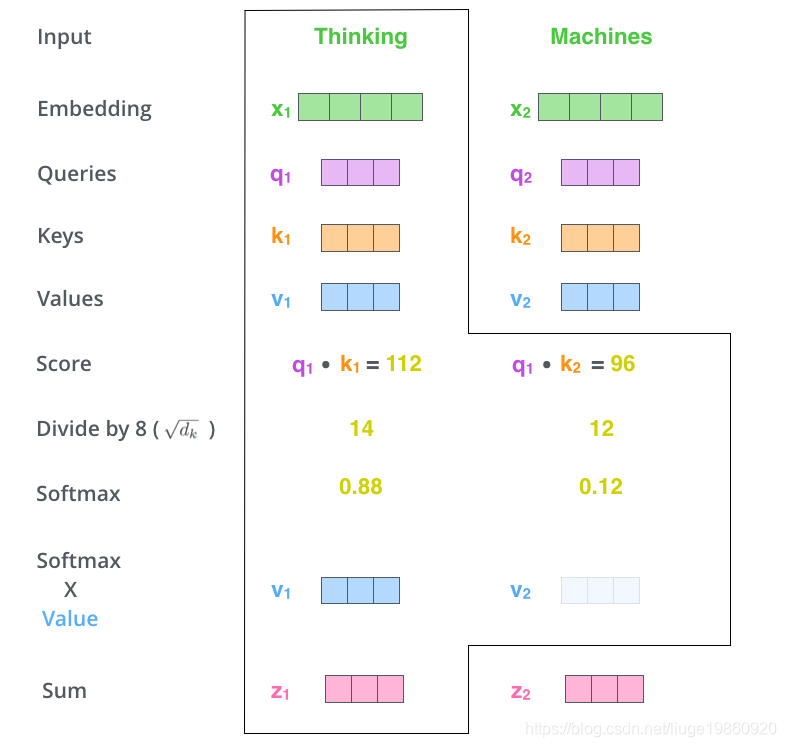
self-attention:
1、q、k、v为embedding或encoder/decoder输出与可学习参数WQ、WK、WV相乘得到,注意Kyubyong/transformer中用的是一层DNN,即包含bias;
2、q和序列的k内积,除以sqrt(64),取softmax,再与序列的v加权得到输出;
3、序列长度掩码mask,输入中后面的qk内积值设成无穷小;
4、MultiHead(Q, K, V ) = Concat(head1, …, headh)Wo,维数正好对上Wo省略
4、在decoder中,self-attention要对后续位置做掩码,位置掩码用下三角实现(感觉有了位置掩码就不用序列掩码了?)

encoder-decoder attention
与self-attention类似,一样的实现
Why Self-attention
未完待续~















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









