









[ICLR’18]论文链接:https://arxiv.org/abs/1710.01878
Tensorflow修剪库参考:https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/model_pruning
这篇文章的重点在于比较一个大疏模型和一个小密模型之间的模型精度和尺寸权衡上,试图仔细研究模型修剪作为模型压缩手段的有效性。文章还提出了一种简单的逐步修剪方法:需要最少的调整并且可以无缝地融入训练过程中。同样展示了其在各种神经网络架构上的适用性和性能。
通过比较通过两种不同方法获得的模型的质量:
(1)训练一个大模型,但修剪得到一个具有少量非零参数(大稀疏)的稀疏模型。
(2)训练一个与大稀疏模型相当的小密模型。
文章选择了不同应用领域的模型进行测试比较:用于图像识别任务的InceptionV3和MobileNets,用于语言模型的LSTM以及在谷歌的神经机器翻译系统中使用的seq2seq模型。
相关工作:
与前人相比,文章工作的优点:
1)在不同领域(视觉与NLP)的各种模型中对稀疏模型与密集模型进行了广泛比较。
2)文章提出的自动渐进修剪算法修剪最小的权值以实现预设的网络稀疏度。
3)不需要为每个层选择权重阈值(依赖于决定权重阈值的稀疏表)。
4)不需要太多的超参数调整,并且可以在不同的模型中表现出色。
5)没有对网络或其构成层的结构作出任何假设,更普遍适用。
方法
文章对于要修剪的图层添加了一个与图层的权重张量大小和形状相同的二元掩码变量,并确定哪个权重参与图的前向传播。根据其绝对值对该层中的权重进行排序,并将掩码设置为0以使最小权值权重为零,直到达到所需的稀疏级别s为止。 反向传播的梯度流经二进制掩码,正向传播中被掩蔽的权重在反向传播步骤中不会更新。(作者开发了一个Tensorflow修剪的代码库)
文章引入了一种新的自动渐进修剪算法,在n步修剪范围内,将稀疏度从初始稀疏值si(通常为0)增加到最终稀疏值sf。以修剪频率Δt从训练步骤t0开始:

二进制权重掩码在训练时以Δt步的频率进行更新,Δt在100到1000之间变化对最终模型质量的影响可以忽略不计。一旦模型达到目标稀疏性sf,权重掩码不再更新。
等式中稀疏函数的作用是在初始阶段当冗余连接充足时快速修剪网络,随着网络中剩余的权重越来越少并逐渐减少每次修剪的权重数量。
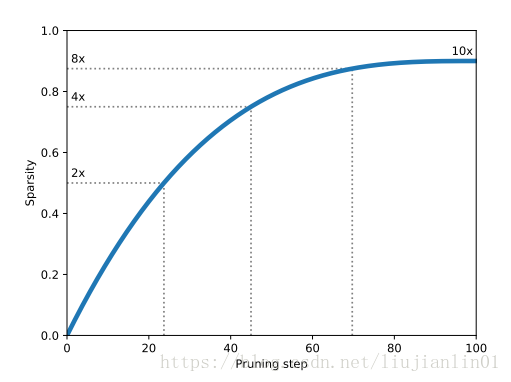
在论文的实验结果中,修剪是在已经训练过几个epoch之后的模型或者已经预训练好的模型之上进行操作的。这决定了超参数t0的值。n的选择在很大程度上取决于学习速率表。
随机梯度下降(及其类似方法)通常会在训练期间衰减学习速率,当设定小的学习率进行大程度的修剪会使后续的训练步骤难以从由于迫使权重为零而导致的准确度损失中恢复。同时,在过高的学习率中进行修剪可能会导致在权重尚未收敛到一个好的解决方案时修剪权重,所以修剪与学习速率密切结合很重要。
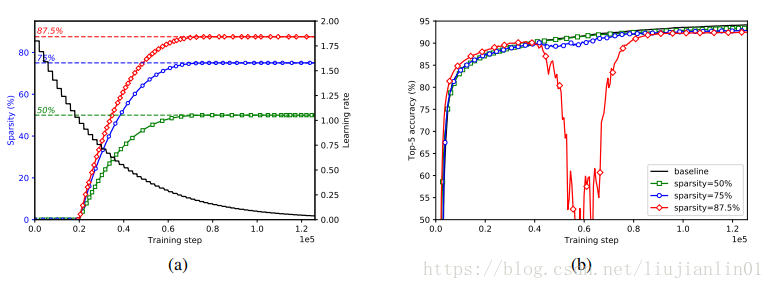
图a显示了用于训练稀疏InceptionV3模型的学习速率和修剪表。在这个模型中的所有卷积层都使用相同的稀疏函数进行修剪,并且修剪发生在学习率仍然相当高的区域,以允许网络从修剪引起的损伤中恢复。图b显示了修剪方案与训练过程之间的相互作用。对于87.5%的稀疏模型,随着稀疏度的逐渐增加,模型遭受近乎灾难性的退化时就会出现一个点,但在持续训练的情况下恢复速度几乎同样快。这种行为在训练有较高稀疏度的模型中更为明显。
比较大稀疏和小密度模型
MobileNets
MobileNets是专门为移动视觉应用设计的一类高效卷积神经网络。MobileNets不使用标准卷积,而是基于一种称为深度可分卷积的分解卷积形式。深度可分卷积由深度卷积组成,后面跟着一个称为逐点卷积的1×1卷积。通过在两个独立的步骤中对输入通道进行滤波和组合,而不是像标准卷积一样,这种因式分解显着减少了模型中参数的数量。MobileNet架构由一个作用于输入图像的标准卷积层,一个深度可分离卷积堆栈以及最后的平均池化和全连接层组成。dense 1.0 MobileNet中的99%参数在1x1卷积层(74.6%)和全连接层(24.3%)中。我们不修剪标准卷积层和深度卷积层的参数,因为这些层中的参数很少(参数总数的1.1%)。
width multiplier是MobileNet网络的一个参数,它允许用参数数量和计算成本来换取模型的准确性。基线模型的width multiplier为1.0。对于一个给定的宽度乘数α,对每层的输入通道数量和输出通道数量相对于基线1.0模型进行α倍的缩放。
文章中比较了使用width multiplier分别为0.75,0.5和0.25训练的dense MobileNets性能,可以看到,对于给定数量的非零参数,稀疏MobileNets能够胜过密集MobileNets。
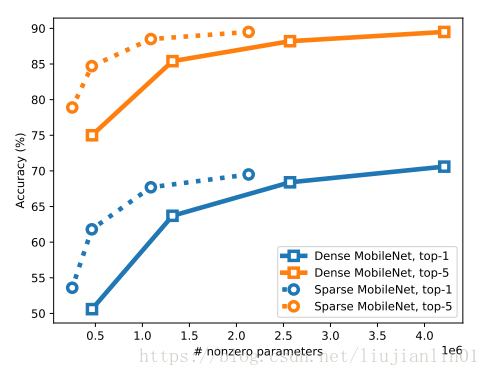
对于给定的非0参数,75%的稀疏模型的性能优于dense 0.5 MobileNet。同样,90%稀疏模型优于dense 0.25 MobileNet。
Penn Tree Bank (PTB) language model
文章使用Zaremba等人提供的模型和训练程序在Penn Tree Bank数据集上训练LSTM语言模型。在每个时间步中,LSTM语言模型从历史给定的词中输出句子中下一个词的概率。损失函数是目标词的平均负log概率,perplexity是损失函数的指数。语言模型由一个嵌入层,2个LSTM层和一个softmax层组成。词汇大小为10000,LSTM隐藏层大小为小型模型200,中型模型650,大型模型1500。
训练不同大小的模型时使用不同的超参数。在修剪大小一定的稀疏模型时,使用的超参数与训练同样大小稠密模型的相同。
文章比较了密集模型和稀疏模型在不同网络大小时的性能。稀疏模型能够胜过具有更多参数的稠密模型。
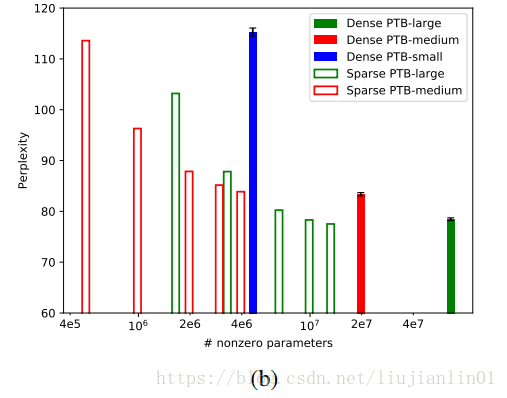
与MobileNet相比,修剪PTB模型可能会带来更好的结果,因为PTB模型更大,参数更多。结果表明,修剪不仅在密集的LSTM权重和密集的softmax层上,而且在密集的嵌入矩阵上都能很好地工作。这表明在优化过程中,神经网络可以找到词汇中词汇的良好稀疏嵌入,能够良好得与LSTM权重和softmax层的稀疏连接结构一起工作。
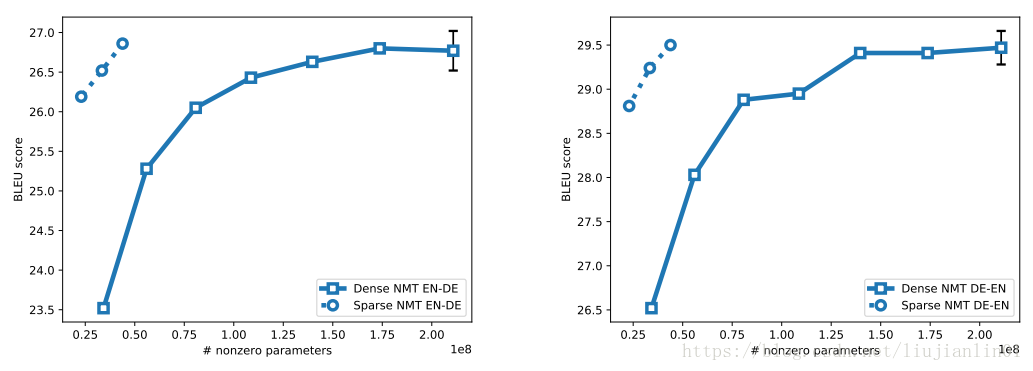
Google Neural Machine Translation
文章使用Luong等人提供的开源TensorFlow项目来训练机器翻译的深层LSTM模型。该项目基于谷歌神经机器翻译架构。该模型是编码器-解码器架构。编码器有一个将36548单词的源词汇表映射到k维空间的嵌入层,1个双向LSTM层和3个标准LSTM层;解码器有一个将36548个单词的目标词汇映射到k维空间的嵌入层,4个注意力LSTM层和一个softmax层。
德文数据集使用WMT16,英文数据集使用news-test2013作为验证集,news-test2015作为测试集。使用BLEU评分进行翻译质量的衡量。训练时初始学习率为1.0,迭代次数为170K,每17K次迭代学习速率衰减为0.5。修剪时初始学习率为0.5,迭代次数为170K,每17K次迭代学习速率衰减为0.5,所有其他超参数保持不变。
因为在NMT训练过程中具有很高的方差,文章测试了几种适用于NMT的修剪方案。
上文提到的逐步修剪方案是在每个修剪步骤中将每层的稀疏度增加到相同的稀疏度水平。
在这里作者提出了一种称之为“分层常量”的稀疏性变体:不在每个修剪步骤中同时将所有图层的稀疏性增加到某个稀疏性水平,而是将修剪细分,一次只增加一层的稀疏性水平。这会降低修剪的影响,并且网络通过训练后可以更好地恢复。
最后的结论表明:稀疏模型胜过更大尺寸的密集模型。
结论
文章证明了大型稀疏模型在各种神经网络架构中的性能优于同等大小的小密度模型,同时还提出了一种渐进修剪技术,可以轻松应用这些不同的架构。














 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









