










追随Song Han大神的第一篇网络压缩论文(NIPS’15),论文链接:https://arxiv.org/abs/1506.02626
这篇论文只是简单介绍了裁剪的思路,并没有涉及到网络加速。
效果:
作者用了4个网络实验
Lenet-300-100, pruning reduces the number of weights by 12×
Lenet-5, pruning reduces the number of weights by 12×
AlexNet, pruning reduces the number of weights by 9×
VGG-16, pruning reduces the number of weights by 12×
修剪后的网络精度下降很低,有的还有所提高。
主要思想:
修剪网络中不重要的连接(直接置0处理),个人感觉有点像Dropout,但是和Dropout具体实现不同。(Dropout不修剪参数,只是随机选择,参数具体内容还在)
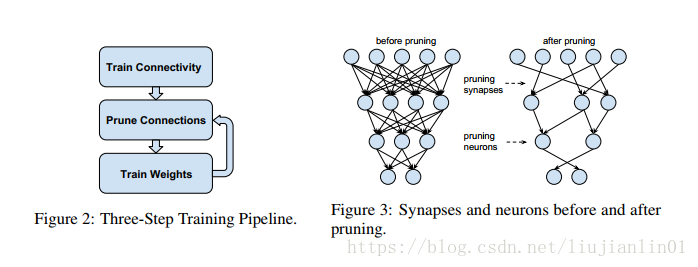
分3步:
1)训练网络,得到训练好的权重
2)设定一个阈值,对权重进行裁剪(个人在代码中选取的阈值是α*weight.std)
3)利用裁剪完的权重进行retrain(再训练),对保留下来的参数进行微调
注意事项:
正则化:
作者采用了L2范数,关于L1范数和L2范数对裁剪产生的影响,作者在论文后的实验中谈到。
Dropout概率的调整:
retrain期间的Dropout概率与原始训练时的Dropout概率相关,作者在论文中给出了计算公式。

裁剪比重:
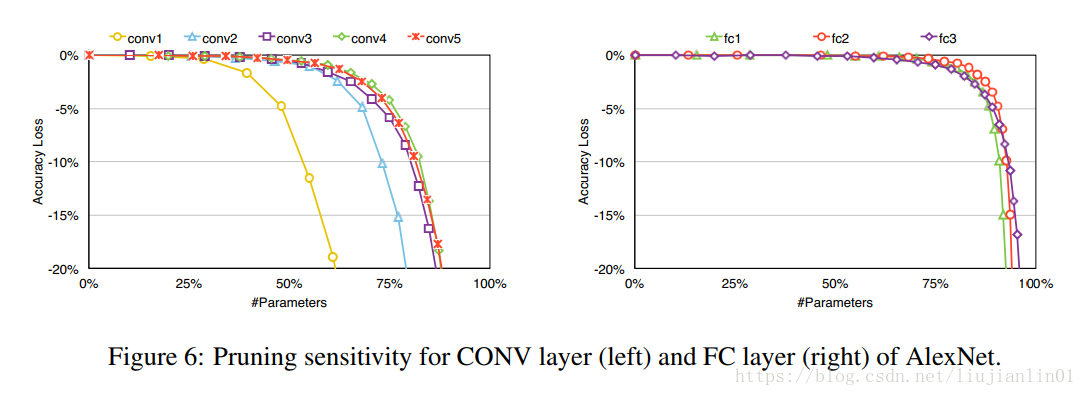
网络中不同层参数裁剪的比例不同。卷积层参数裁剪比例应较小,裁剪过多会对网络的精度造成很大影响;因为全连接层的参数数量最多,而且全连接层对网络精度的提升效果并不是很大,所以全连接层裁剪比例应较大,笔者实验也证明了这一点。作者在论文中同时也给出了裁剪比例测试结果。
迭代裁剪:
其实就是循环裁剪(笔者认为retrain过程中训练一次,裁剪一次)
去除无效神经元:
就是将0输入和0输出的神经元裁剪掉
权重保存:
这点作者在论文中并没有提到,其实裁剪完的权重如果正常保存的话所占空间和原始权重是一样的,因为都还是float型,即便里面置0,但是所占空间的大小是不会变的。
笔者在裁剪完后发现了这个问题,最开始笔者采取只保存权重中的非0值和非0值的索引位置,但是发现这种保存方式在裁剪率较低的情况下会导致权重文件所占的空间比原始权重大,只有当裁剪比例达到一定程度时权重文件所占空间才会比原始权重小。
通过拜读了Song Han大神的下一篇论文【Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding】(ICLR’2016)看到了更好的解决方案。

















 5675
5675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









