




 本文详细介绍了Spark的宽窄依赖概念,包括窄依赖的一对一或多对一关系,宽依赖的一对多特性及其在数据重新分布中的作用。接着,文章深入探讨了Stage的划分规则和计算模式,以及Spark的资源调度和任务调度流程,包括粗粒度和细粒度资源申请。此外,还讨论了共享变量如广播变量和累加器的使用,以及Spark Shuffle的原理,包括HashShuffle和SortShuffle的优缺点。最后,文章触及Spark内存管理,包括静态和统一内存管理模式。
本文详细介绍了Spark的宽窄依赖概念,包括窄依赖的一对一或多对一关系,宽依赖的一对多特性及其在数据重新分布中的作用。接着,文章深入探讨了Stage的划分规则和计算模式,以及Spark的资源调度和任务调度流程,包括粗粒度和细粒度资源申请。此外,还讨论了共享变量如广播变量和累加器的使用,以及Spark Shuffle的原理,包括HashShuffle和SortShuffle的优缺点。最后,文章触及Spark内存管理,包括静态和统一内存管理模式。
- 课程地址:spark讲解
- Scala | Spark基础入门 | IDEA配置 | 集群搭建与测试
- Scala | Spark核心编程 | SparkCore | 算子
- Scala | 宽窄依赖 | 资源调度与任务调度 | 共享变量 | SparkShuffle | 内存管理
- Scala | SparkSQL | 创建DataSet | 序列化问题 | UDF与UDAF | 开窗函数
一、术语解释

Task的个数 =Paration的个数 = 并行度
job串行,Stage串行加并行,task并行;
app > job > stage > task
二、窄依赖和宽依赖
RDD 之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
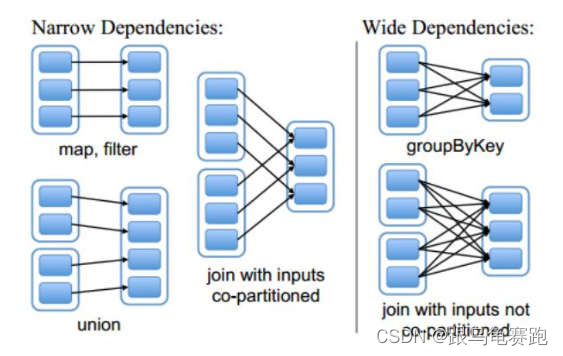
1.窄依赖
父 RDD 和子 RDD partition 之间的关系是一对一的。或者父 RDD 和子 RDD的partition 关系是多对一的。不会有 shuffle 的产生。
shuffle会产生数据重新分布
2.宽依赖
父 RDD 与子 RDD partition 之间的关系是一对多。会有 shuffle 的产生。
3.宽窄依赖图理解(以WordCount为例)
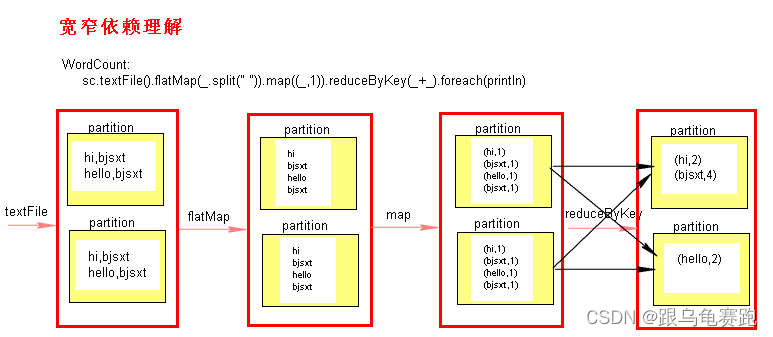
三、Stage详解
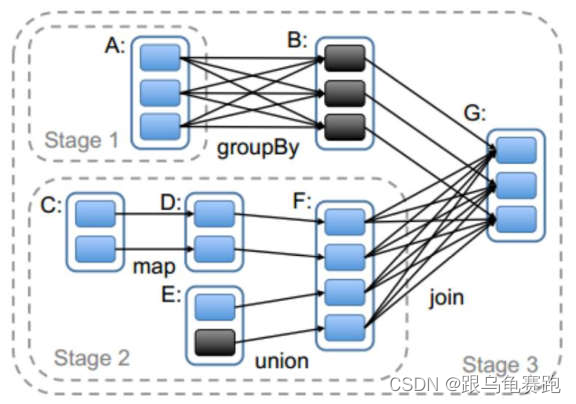
Spark 任务会根据 RDD 之间的依赖关系,形成一个 DAG 有向无环图,DAG会提交给 DAGScheduler,DAGScheduler 会把 DAG 划分相互依赖的多个stage,划分 stage 的依据就是 RDD 之间的宽窄依赖。遇到宽依赖就划分stage,每个 stage 包含一个或多个 task 任务。然后将这些 task 以 taskSet的形式提交给 TaskScheduler 运行。stage是由一组并行的 task 组成。
1.stage 切割规则
切割规则:从后往前,遇到宽依赖就切割 stage。
2.stage 计算模式
stage 计算模式是pipeline 管道计算模式。pipeline 只是一种计算思想、模式。
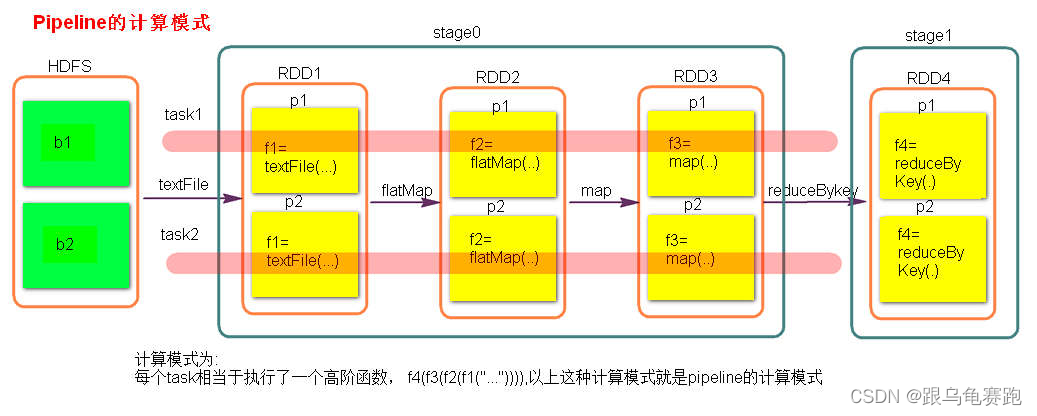
测试验证 pipeline 计算模式:
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object Pipeline_Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("pipeline")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(Array(1, 2, 3))
val rdd2: RDD[Int] = rdd.map(x => {
println("map---------------", x)
x
})
val rdd3: RDD[Boolean] = rdd2.map(x => {
println("filter-------------", x)
true
})
rdd3.collect()
sc.stop()
}
}
(map---------------,1)
(filter-------------,1)
(map---------------,2)
(filter-------- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2617
2617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











