







广度优先搜索
广度优先搜索(Breadth-First-Search,BFS)类似于二叉树的层序遍历算法(借助队列),其基本思想是:首先访问起始顶点,接着由v出发,依次访问v的各个未访问过的邻接顶点w1,W2,…,Wn,然后依次访问w1,W2,…,Wn的所有未被访问过的邻接顶点;再从这些访问过的顶点出发,访问它们所有未被访问过的邻接顶点……以此类推,直到图中所有顶点都被访问过为止。Dijkstra 单源最短路径算法和Prim最小生成树算法也应用了类似的思想。
广度优先搜索是一种分层的查找过程,每向前走一步可能访问一批顶点,不像深度优先拽索那样有往回退的情况,因此它不是一个递归的算法。为了实现逐层的访问,算法必须借助一个辅助队列,以记忆正在访问的顶点的下一层顶点。
在示例中,我们创建了一个简单的图实例,并从节点2开始执行广度优先搜索,最终输出了搜索的结果。
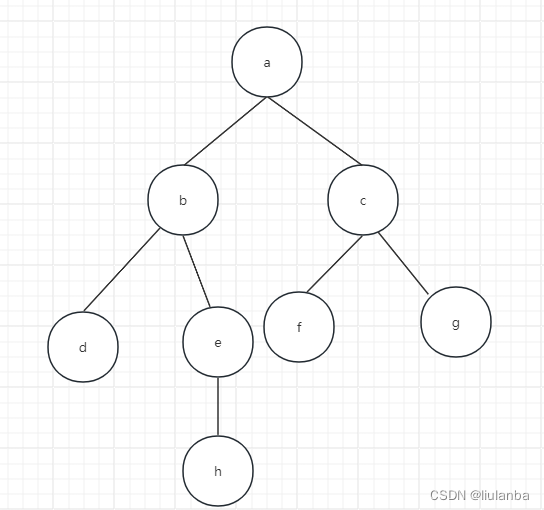
下面通过实例演示广度优先搜索的过程,给定图G如下。假设从a结点开始访问,a先入队。此时队列非空,取出队头元素a.由于b、c与a邻接且未被访问过,于是依次访问b、c,并将b、c依次入队。队列非空,取出队头元素b,依次访问与b邻接且未被访问的顶点d、e,并将d、e入队(注意:a与b也邻接,但a己置访问标记,故不再重复访问)。此时队列非空,取出队头元素c,访间与c邻接且未被访问的顶点f、g,并将f、g入队。此时,取出队头元素d,但与d邻接且未被访问的顶点一个无向图G为空,故不进行任何操作。继续取出队头元素e,将h入队列……最终取出队列头元素h后,队列为空,从而抵环自动跳出。遍历结果为 abcdefh
从上例不难看出,图的广度优先搜索的过程与二叉树的层序遍历是完全一致的,这也说明了图的广度优先搜索遍历算法是二叉树的层次遍历算法的扩展。
广度优先搜索(Breadth-First Search,简称BFS)是一种图搜索算法,用于在图或树数据结构中遍历或搜索。BFS从根节点开始,沿着树的宽度遍历树的节点,即首先访问根节点的所有邻居节点,然后再依次访问邻居节点的邻居节点。在搜索时,BFS通常使用队列数据结构来辅助实现。下面是用Python实现BFS算法的示例代码:
from collections import defaultdict, deque
class Graph:
def __init__(self):
self.graph = defaultdict(list)
def add_edge(self, u, v):
self.graph[u].append(v)
def bfs(self, start):
# 使用队列来存储待访问的节点
queue = deque()
# 使用集合来记录已经访问过的节点,避免重复访问
visited = set()
# 将起始节点加入队列,并标记为已访问
queue.append(start)
visited.add(start)
while queue:
# 从队列中取出一个节点
current_node = queue.popleft()
print(current_node, end=' ')
# 遍历当前节点的邻居节点
for neighbor in self.graph[current_node]:
# 如果邻居节点尚未被访问,则将其加入队列,并标记为已访问
if neighbor not in visited:
queue.append(neighbor)
visited.add(neighbor)
# 创建图实例
g = Graph()
# 添加边
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 0)
g.add_edge(2, 3)
g.add_edge(3, 3)
print("BFS traversal starting from vertex 2:")
g.bfs(2)
这段代码首先定义了一个Graph类,其中包含了add_edge方法用于添加边,以及bfs方法用于执行广度优先搜索。在bfs方法中,我们使用了一个队列来辅助遍历图中的节点,首先将起始节点加入队列,然后循环从队列中取出一个节点,并访问其未访问过的邻居节点,将其加入队列中。重复这一过程,直到队列为空,即完成了图的广度优先搜索。
1.BFS算法的性能分析
无论是邻接表还是邻接矩阵的存储方式,BFS算法都需要借助一个辅助队列Q,n个顶点均需入队一次,在最坏的情况下,空间复杂度为0(V)。
采用邻接表存储方式时,每个顶点均需搜索一次(或入队一次),故时间复杂度为0(V),在搜索任一顶点的邻接点时,每条边至少访问一次,故时间复杂度为 0(E),算法总的时间复杂度为0(V+E)。采用邻接矩阵存储方式时,查找每个顶点的邻接点所需的时间为O(V),故算法总的时间复杂度为0(V²)。
2.BFS算法求解单源最短路径问题
若图G=(V,E)为非带权图,定义从顶点u到顶点v的最短路径d(u,v)为从u到v的任何路径中最少的边数;若从u到v没有通路,则d(u,v)=∞。
使用BFS,我们可以求解一个满足上述定义的非带权图的单源最短路径问题,这是由广度优先搜索总是按照距离由近到远来遍历图中每个顶点的性质决定的。
BFS 算法求解单源最短路径问题的算法如下:
from collections import defaultdict, deque
class Graph:
def __init__(self):
self.graph = defaultdict(list)
def add_edge(self, u, v):
self.graph[u].append(v)
def bfs_shortest_path(self, start):
# 使用队列来存储待访问的节点,并记录节点到起始节点的距离
queue = deque([(start, 0)])
# 使用字典来存储节点到起始节点的最短距离
shortest_paths = {start: 0}
while queue:
current_node, distance = queue.popleft()
# 遍历当前节点的邻居节点
for neighbor in self.graph[current_node]:
# 计算邻居节点到起始节点的距离
neighbor_distance = distance + 1
# 如果邻居节点尚未被访问或找到了更短的路径,则更新最短距离并加入队列
if neighbor not in shortest_paths:
shortest_paths[neighbor] = neighbor_distance
queue.append((neighbor, neighbor_distance))
return shortest_paths
# 创建图实例
g = Graph()
# 添加边
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 0)
g.add_edge(2, 3)
g.add_edge(3, 3)
# 求解从节点0到其他节点的最短路径
start_node = 0
shortest_paths = g.bfs_shortest_path(start_node)
print("Shortest paths from node", start_node, "to other nodes:")
for node, distance in shortest_paths.items():
print("Node:", node, "Distance:", distance)
这段代码首先定义了一个Graph类,其中包含了add_edge方法用于添加边,以及bfs_shortest_path方法用于执行BFS算法求解最短路径问题。在bfs_shortest_path方法中,我们使用了一个队列来辅助遍历图中的节点,并利用一个字典来记录每个节点到起始节点的最短距离。我们从起始节点开始执行BFS算法,在遍历过程中,不断更新节点到起始节点的最短距离,直到队列为空。
在示例中,我们创建了一个简单的图实例,并求解了从节点0到其他节点的最短路径。最后输出了每个节点到起始节点的最短距离。
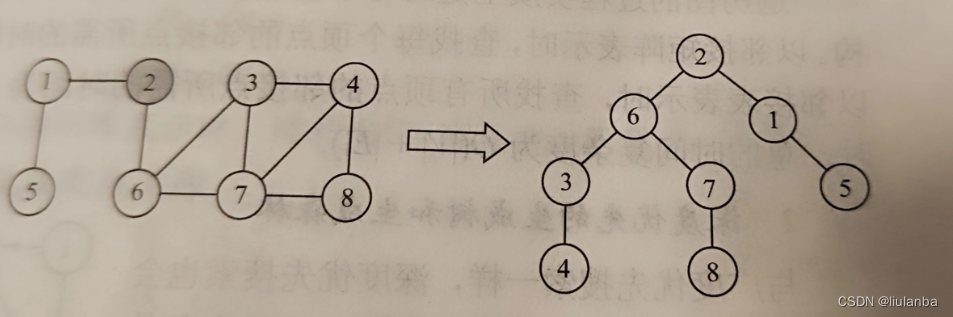
3.广度优先生成树
在广度遍历的过程中,我们可以得到一棵遍历树,称为广度优先生成树,需要注意的是,一给定图的邻接矩阵存储表示是唯一的,故其广度优先生成树也是唯一的,但由于邻接表存储表示不唯一,故其广度优先生成树也是不唯一的。
from collections import deque
def bfs(graph, start):
visited = set() # 使用一个集合来记录已经访问过的节点
queue = deque([start]) # 使用一个队列来存储待访问的节点
visited.add(start) # 将起始节点标记为已访问
while queue: # 当队列不为空时继续循环
node = queue.popleft() # 取出队首节点
print(node) # 可以在这里输出节点值,代表对节点的访问
for neighbor in graph[node]: # 遍历当前节点的邻居节点
if neighbor not in visited: # 如果邻居节点未被访问过
visited.add(neighbor) # 将邻居节点标记为已访问
queue.append(neighbor) # 将邻居节点加入队列
# 示例图的邻接表表示
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
# 从节点'A'开始进行广度优先搜索
bfs(graph, 'A')
bfs函数接受两个参数:graph是表示图的邻接表,start是指定的起始节点。
我们使用一个集合visited来记录已经访问过的节点,并使用一个双端队列queue来存储待访问的节点。在开始时,我们将起始节点start加入到visited集合和queue队列中,并标记为已访问。
在while循环中,我们不断从队列中取出节点进行处理,直到队列为空。
在每次处理一个节点时,我们打印该节点的值,这里可以代表对节点的访问操作。
然后,我们遍历当前节点的邻居节点。对于每个邻居节点,如果它尚未被访问过,则将其标记为已访问,并将其加入到队列中,以便稍后进行处理。
这个过程会一直持续,直到队列中没有待访问的节点为止。
通过这种方式,广度优先搜索会逐层遍历图,从而生成一棵树,这棵树称为广度优先搜索生成树。
深度优先搜索
与广度优先搜索不同,深度优先搜索(Depth-First-Search,DFS)类似于树的先序遍历)如其名称中所暗含的意思一样,这种搜索算法所遵循的搜索策略是尽可能“深”地拽索一个图。
它的基本思想如下:首先访问图中某一起始顶点v,然后由v出发,访问与v邻接且未被访问的任顶点m1,再访问与m1邻接且未被访问的任一顶点m2…重复上述过程。当不能再继续向下访间时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述拟索过程,直到图中所有顶点均被访问过为止。
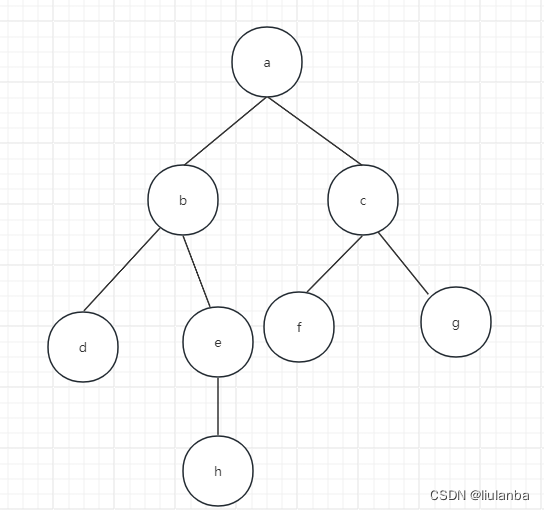
以图所示的无向图为例,演示深度优先搜索的过程:首先访问a,并置a己访问标记。然后访问与a邻接且未被访问的顶点b,置b已访问标记;然后访问与b邻接且未被访问的顶点d,置d已访问标记。此时d已没有未被访问过的邻接点,故返回上一个访问过的顶点b,访问与其邻接且未被访问的顶点e,置e访问标记……以此类推,直到图中所有的顶点访问一次且仅访问一次。遍历结果为abdehcfg
注意:图的邻接矩阵表示是唯一的,但对于邻接表来说,若边的输入次序不同,生成的邻接表也不同。因此,对于同样一个图,基于邻接矩阵的遍历所得到的 DFS 序列和 BFS序列是唯一的,基于邻接表的遍历所得到的DFS 序列和BFS序列是不唯一的。
深度优先搜索(DFS)是一种用于遍历或搜索树或图的算法。它从根节点开始,沿着树的深度尽可能远的路径探索每个分支,直到遇到叶子节点或者无法继续往下搜索为止,然后回溯到前一个节点,继续深度遍历其他分支。
下面是用Python实现深度优先搜索算法的代码:
def dfs(graph, start, visited=None):
if visited is None:
visited = set() # 使用一个集合来记录已经访问过的节点
visited.add(start) # 将当前节点标记为已访问
print(start) # 可以在这里输出节点值,代表对节点的访问
for neighbor in graph[start]: # 遍历当前节点的邻居节点
if neighbor not in visited: # 如果邻居节点未被访问过
dfs(graph, neighbor, visited) # 递归调用dfs函数进行深度优先搜索
# 示例图的邻接表表示
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
# 从节点'A'开始进行深度优先搜索
dfs(graph, 'A')
dfs函数接受三个参数:graph是表示图的邻接表,start是指定的起始节点,visited是一个集合,用于记录已经访问过的节点。在函数内部,我们先检查是否需要初始化visited,如果没有提供,就将其设为一个空集合。
我们将当前节点start加入到visited集合中,表示已经访问过。
在每次访问一个节点时,我们打印该节点的值,这里可以代表对节点的访问操作。
接着,我们遍历当前节点的邻居节点。对于每个邻居节点,如果它尚未被访问过,则以它为起点递归调用dfs函数进行深度优先搜索。
这个递归过程会一直持续,直到遍历完整个图或者无法继续深入为止。
1.DFS算法的性能分析
DFS 算法是一个递归算法,需要借助一个递归工作栈,故其空间复杂度为O(V)。
遍历图的过程实质工是对每个顶点查我其邻接点的过程,其耗费的时间取决于所用的存储结构。以邻接矩阵表示时,查找每个顶点的邻接点所需的时间为0(V),故总的时间复杂度为0(V²).以邻接表表示时,查找所有顶点的邻接点所需的时间为O(E),访问顶点所需的时间为0(V)),此时,总的时间复杂度为O(V+|E|)
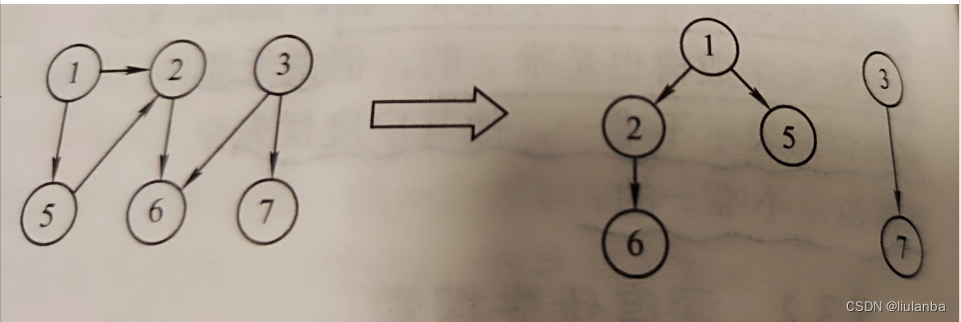
2.深度优先的生成树和生成森林
与广度优先拽索一样,深度优先拽索也会产生一棵深度优先生成树。当然,这是有条件的,即对连通图调用DFS才能产生深度优先生成树,否则产生的将是深度优先生成森林,如图5.13所示。与BFS类似,基于邻接表存储的深度优先生成树是不唯一的。
深度优先生成树是深度优先搜索(DFS)在树结构中的应用。当使用DFS遍历一个连通图时,会生成一棵深度优先生成树。这棵生成树包含了图中所有可达节点,并且保持了深度优先搜索的顺序。
下面是详细解释深度优先生成树的过程:
选择起始节点:深度优先生成树的开始节点可以是任意一个节点。通常选择图中的一个未被访问过的节点作为起始节点。
从起始节点开始深度优先搜索:从起始节点开始,进行深度优先搜索。具体来说,对于当前节点,首先将其标记为已访问,然后递归地访问其所有未被访问过的邻居节点。
生成树的边:在搜索过程中,每次从当前节点到邻居节点的访问过程中,形成的边被添加到生成树中。这些边构成了深度优先生成树的结构。
回溯:当一个节点的所有邻居节点都被访问过后,递归回溯到上一个节点,继续搜索其他未被访问的邻居节点。
终止条件:深度优先搜索会一直进行直到所有可达节点都被访问过为止。这样就会形成一棵包含所有节点的深度优先生成树。
通过这个过程,深度优先生成树保留了图中节点之间的连接关系,并且保持了深度优先搜索的顺序。生成树的根节点是起始节点,而其他节点则按照DFS的顺序连接到根节点上。
在实际应用中,深度优先生成树通常用于网络路由、拓扑排序、最小生成树算法等场景中。
下面是用Python实现深度优先生成树的代码:
def dfs(graph, start, visited=None):
if visited is None:
visited = set() # 使用一个集合来记录已经访问过的节点
visited.add(start) # 将当前节点标记为已访问
for neighbor in graph[start]: # 遍历当前节点的邻居节点
if neighbor not in visited: # 如果邻居节点未被访问过
yield start, neighbor # 生成一条边 (start, neighbor)
yield from dfs(graph, neighbor, visited) # 递归调用dfs函数进行深度优先搜索
# 示例图的邻接表表示
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
# 从节点'A'开始进行深度优先搜索
dfs_tree_edges = list(dfs(graph, 'A'))
print("深度优先生成树的边:")
for edge in dfs_tree_edges:
print(edge)
在这个实现中,使用了一个生成器函数 dfs,它会生成深度优先生成树的所有边。在函数内部使用递归来进行深度优先搜索,当访问到一个节点时,会将其与邻居节点之间的边生成出来。
这段代码会输出深度优先生成树的所有边,例如:
深度优先生成树的边:
('A', 'B')
('B', 'D')
('D', 'E')
('B', 'E')
('A', 'C')
('C', 'F')
这些边构成了深度优先生成树的结构,它们保留了节点之间的连接关系,并且按照深度优先搜索的顺序连接起了整棵树。














 5406
5406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









