









使用系统:
ubuntu16.04、Windows7
step1:
新建工程文件夹:TensorFlowRetrainInceptionV3,然后下载图片训练集,这里我使用的是Google 提供的一个训练样本。
$ cd TensorFlowRetrainInceptionV3
$ curl -O http://download.tensorflow.org/example_images/flower_photos.tgz
$ tar xzf flower_photos.tgz打开训练样本文件夹 flower_photos ,里面有 5 种类别的花:daisy(雏菊), dandelion(蒲公英), roses(玫瑰), sunflowers(向日葵) , tulips(郁金香),每个类别的大概有 600-700 张训练样本图片。

step2:
下载 retrain 脚本
该脚本会自动下载 google Inception v3 模型相关文件,retrain.py 是 Google 提供的迁移训练脚本。这里我们可以通过以下命令进行下载:
$ cd TensorFlowRetrainInceptionV3
$ curl -O https://raw.githubusercontent.com/tensorflow/tensorflow/r1.1/tensorflow/examples/image_retraining/retrain.py
也可以通过Google提供的链接进行下载:
https://github.com/googlecodelabs/tensorflow-for-poets-2
这是Google针对mobile专门设计tensorflow Lite而开源的一个集成包。主要包含了一些tensorflow Lite需要用的script文件中的脚本和在Android和ios上运行的开源代码。
step3:
启动训练脚本
通过运行 retrain.py 脚本时,需要配置一些运行命令参数,比如指定模型输入输出相关名称和其他训练要求的配置。
阅读retrain.py源文件,我们可以得到一些待输入的参数:
阅读源码,查看脚本中几个重要的输入参数
‘–image_dir’
标记图像文件夹的路径
‘output_graph’
存放训练好的计算图(该计算图已经进行了变量固化,可以直接转化为TFlite)
‘–output_labels’
输出标签
‘–summaries_dir’
存放训练日志,用TensorfBord打开,可以查看训练过程
‘–how_many_training_steps’
训练次数
‘–bottleneck_dir’
存放瓶颈层输出的特征向量
‘–architecture’
预训练好的用于提取图像特征的模型
‘–saved_model_dir’
存放导出的模型,含有计算流图和变量值
‘–final_tensor_name’
输出层的节点名字
linux系统,运行retrain.py脚本,输入以下命令:
python retrain.py \
--bottleneck_dir bottleneck \
--how_many_training_steps 200 \
--model_dir modeldir \
--output_graph output_graph.pb \
--output_labels output_labels.txt \
--image_dir flower_photos
Windows系统,运行retrain.py脚本,输入以下命令:
python retrain.py ^
--bottleneck_dir bottleneck ^
--how_many_training_steps 200 ^
--model_dir modeldir ^
--output_graph output_graph.pb ^
--output_labels output_labels.txt ^
--image_dir flower_photos
如果不添加--how_many_training_steps=500配置,默认值为4000,会相当耗时,建议测试阶段可以减少这个值。
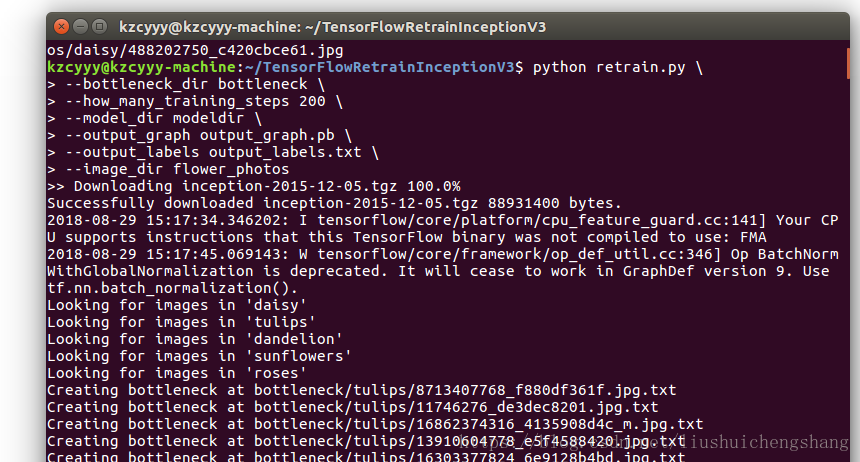
最后运行结束,主要会生成我们定义好会用到的output_graph.pb 和 output_labels.txt两个文件。
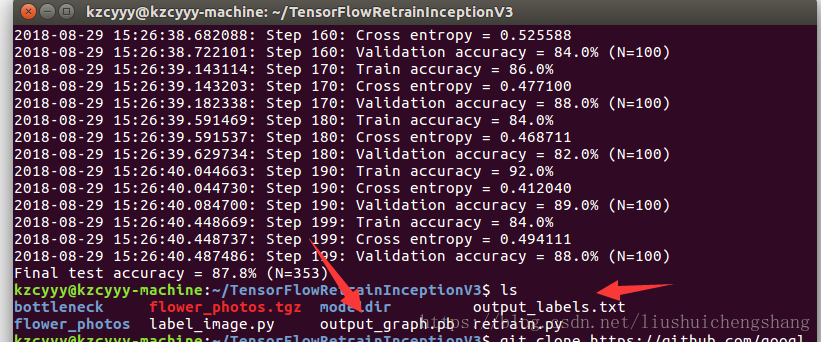
step4:
接下来就是测试我们生成的pb文件的最终效果,即测试分类的准确度。在Google提供的tensorflow Lite中的script文件夹中,通过lable_image.py来进行测试。
python -m scripts.label_image \ --graph=output_graph.pb \ --image=flower_photos/daisy/3475870145_685a19116d.jpg
我在运行的是时候出现以下错误:
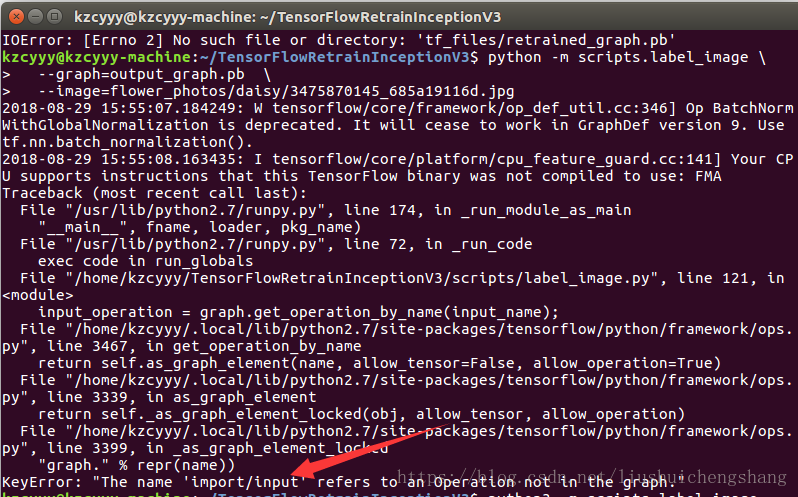
需要对label_image.py文件进行修改:
input_layer = "input"
output_layer = "final_result"
修改为:
input_layer = "Mul"
output_layer = "final_result"
就可以了!
如果出现输入图片shape的问题,如下
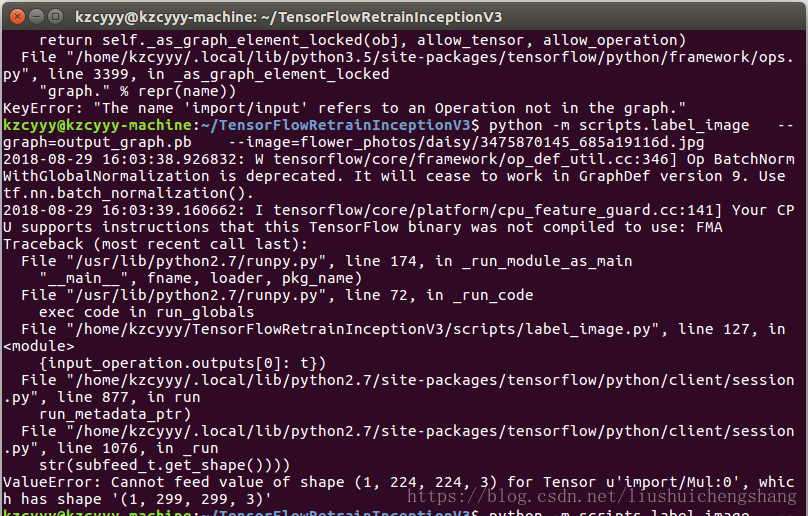
对label_image.py文件中,相应的位置,进行修改,
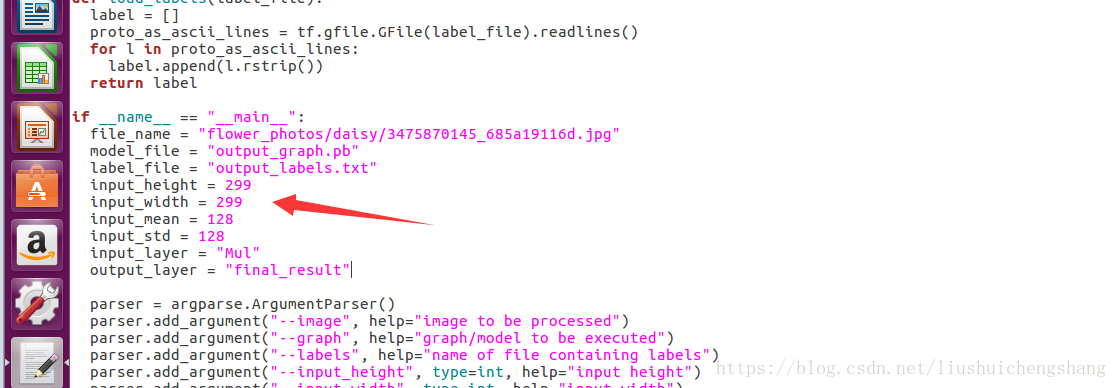
接下来应该不会再有什么错误了!运行以下看看效果
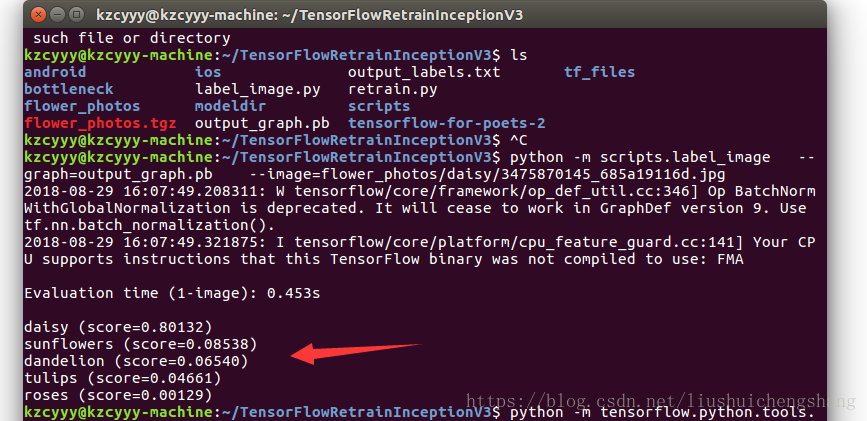
基于迁移学习的简单图像分类就完成了


















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











