







https://arxiv.org/abs/2002.12549
加入对抗训练的鲁棒的无监督NMT(未开源)
以前的工作只关注如何在干净的数据上建立sota UNMT,而在真实的场景中,输入语句中常常存在小的噪声。模型对输入中的微小扰动很敏感,会导致各种误差。
首先定义两种类型的噪声,研究UNMT和SNMT在这种嘈杂场景下的性能,结果表明UNMT模型的性能优于SNMT模型,但两者的性能均有所下降。对抗性训练方法可以缓解这种情况, 提高BLEU score 10分。
两种噪声
单词噪声:对源句中的每个单词,以概率a替换为任意一个单词。a值越大,则有越多的单词被任意单词替换。
词序噪声:input shuffle策略,用一个随机数列γ改变源句子的词序,满足:
![]()
![]()
n为源句子长度,b为控制词序调整幅度的超参数,值越大顺序越乱(只有当b > 1时,顺序才会改变)。大小为n的随机数组Q,U为从0到b的均匀分布。γ定义Q的排列顺序,以合成噪声。
随着噪音a、b的增加,SNMT和UNMT性能都有所下降,在有噪声的情况下,UNMT系统的性能要优于BLEU评分的SNMT系统。

两种对抗训练方法去噪训练
基于词性嵌入的对抗性训练(Word_AT)和基于位置嵌入的对抗性训练(Position_AT),分别利用含有单词噪声和词序噪声的输入来提高UNMT的性能。

(1)Word_AT
对于语言L1在每次迭代训练,最小化目标函数使模型对扰动具有鲁棒性:
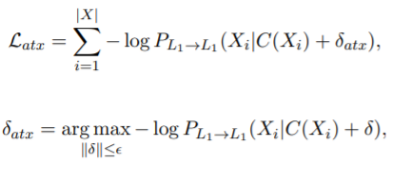
δ是源端的一个小的扰动。计算δatx的最大化是很困难的,词对抗扰动δatx是通过目标函数的梯度来近似。{Xi}是语言L1的数据集,{Yi}是语言L2的数据集,|X|, |Y|分别是数据集中的句子数量,{C(Xi)}和{C(Yi)}是有噪音的句子。PL1→L1 (PL2→L2)表示重构的概率。

gx为目标函数的梯度,通过反向传播算法计算得到。ε是控制对抗扰动大小的超参数。L2语言的对抗扰动目标函数优化为:

为了提高UNMT的鲁棒性,在UNMT去噪训练过程中会加入目标函数Latx和Laty。整个UNMT目标函数为:
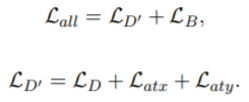
LD是去噪的目标函数,LB是back-translaion的目标函数。{(YM(Xi), Xi)}和{(XM(Yi), Yi)} 是pseudo-parallel 句子对,PL1→L2和PL2→L1表示两种语言之间的翻译概率。。

(2)Position_AT
将对抗扰动添加到原始位置向量中,作为新的位置向量,然后和词向量结合。使用位置对抗扰动对源句已有的位置向量进行惩罚,从而在UNMT去噪训练中产生新的顺序位置向量。
实验结果

1)表现最好的UNMT (Lample Conneau, 2019),使用干净的Fr↔En、De↔En数据集。
2)在输入中只有单词噪声的情况下,Word_AT方法超过baseline约7.4 BLEU分;在输入中只有语序噪声的情况下,Position_AT方法超过baseline约8.3个BLEU分。
3)在包含了单词噪声和词序噪声的场景中,baseline UNMT得分显著减少,而Word_AT和Position_AT方法平均分别提高了4和3.3个BLEU分。两种AT方法都可以进一步提高UNMT性能,平均提高10个BLEU分。这表明作者提出的方法有效地缓解了输入噪声问题。
4)这种对抗性训练方法也可以在干净的数据输入中略微提高UNMT的性能,在所有测试集上平均提高0.6个BLEU分数,表明该方法可以提高UNMT在清洁场景下的鲁棒性。
在有噪声的情况下,对抗训练方法明显优于baseline UNMT。特别是源语言输入越嘈杂,两种UNMT系统之间的差距就越明显。这说明对抗训练方法是稳健有效的。
















 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









