







https://arxiv.org/pdf/1910.02688.pdf
机器翻译的自动测试和改进
Github:https://github.com/zysszy/TransRepair(无代码)
本文提出一种测试和修复机器翻译系统一致性的自动方法——TransRepair,在没有标准翻译的情况下,结合 metamorphic testing 蜕变测试的 mutation 突变检测不一致的问题,然后采用 probability-reference 或 cross-reference 对翻译进行后处理,以灰盒或黑盒的方式修复不一致的问题。对谷歌翻译和 Transformer 的评估表明,TransRepair 在生成翻译一致的输入对方面具有很高的准确率 (99%),使用自动一致性度量和手动评估,发现谷歌翻译和 Transformer 大约有36%和40%的不一致 bug。黑盒修复了平均28%和19%的谷歌翻译和 Transformer 错误,灰盒修复了平均30%的 Transformer 错误。手动检查表明,TransRepair 修复的译文在87%的情况下提高了一致性(在2%的情况下降低了一致性),在27%的情况下的修复具有更好的翻译可接受性(在8%的情况下降低了可接受性)。
关键词:machine translation, testing and repair, translation consistency
1 INTRODUCTION

图1中,当主语是“men”或“male students”时,谷歌翻译将“good”翻译成“很好的 (very good)”,然而当主语是“women”或“female students”时,则将“good”翻译成“很多 (a lot)”,这种不一致可能会让用户感到困惑,而且显然对计算机科学领域的女性研究人员也不公平,与进行“very good”研究相比,进行“a lot”研究显然是一种更具贬义的解释。为了避免这种不公平的翻译,需要能够自动识别和纠正这种不一致性的技术。
现有的工作可以测试翻译系统能否为语义相等的转换(如同义词替换 buy→purchase,或缩写替换 what’s→what is)提供稳定的翻译,但没有涉及到上下文相似转换的翻译不一致性的测试和修复,也没有涉及到具有相似词嵌入、但在语料库中共享上下文的句子之间的转换(例如,简单的基于性别的转换,boys→girls)。
作者引入一种将突变与蜕变测试结合的方法,通过上下文相似的突变来生成突变句,作为被测机器翻译的输入,当上下文相似的突变导致非突变部分的翻译变化超出阈值时,就报告一个不一致错误。
传统机器学习系统的“修复”方法通常使用数据增强或算法优化,提高机器学习的整体性能,而不是针对单个错误特定修复;还需要数据收集、标注和模型的再训练,通常成本很高。传统“修复”方法是白盒的,找到要修改的源代码进行修复,但这种方法不能用于修复源代码不可用的软件,比如第三方代码。
结合系统重复输出的结果(可能不一致),可以实现一种轻量级的黑盒修复技术,作为特定bugs的后处理。除了可以修复机器翻译,当开发人员遇到源代码不可见的 bug 时,黑盒修复是惟一可用的方法。对于谷歌翻译和 Transformer,TransRepair 能生成有效的测试输入,准确率为99%;自动效地报告超过阈值的不一致错误,谷歌翻译/Transformer 的 F值平均为0.82/0.88。
2 APPROACH
2.1 Overview
图2为 TransRepair 的概览,主要有三个步骤:
1) Automatic test input generation. 生成用于一致性测试的句子,对每个句子使用上下文相似的单词替换进行句子突变,生成的候选突变使用语法检查进行筛选,通过筛选的突变将作为被测机器翻译的输入;
2) Automatic test oracle generation. 根据翻译输入和输出之间的蜕变关系,生成 oracle 以识别不一致的翻译,思想是,翻译原句与其上下文相似突变句的输出应具有一定程度的一致性。使用相似度指标衡量翻译输出和 oracle 的一致性程度;
3) Automatic inconsistency repair. 有黑盒和灰盒两种方法,根据突变中最优的翻译对原译文进行转换。考虑两种最优翻译的选择方法:predictive probability 预测概率法,cross-reference 交叉引用法。

2.2 Automatic Test Input Generation
生成输入的过程包含以下步骤:
2.2.1 Context-similarity Corpus Building. 进行上下文相似的单词替换的关键步骤是,找到一个可以被其他相似单词替换、且不影响句子结构的单词,替换生成的新句应与原句的翻译一致。使用词向量衡量相似度,两个单词 w1 和 w2 之间的相似度为 sim(w1, w2),vx 为词 x 的向量。
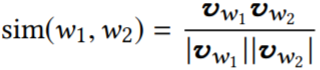
为了构建一个可靠的上下文相似语料库,采用 GloVe、SpaCy 两种词向量模型,并使用其训练结果的交集。当两个单词在两个模型中的相似度都超过0.9时,则认为它们是上下文相似的,将这对单词放入上下文相似语料库中,使用这种方法总共收集了131,933个单词对。
2.2.2 Translation Input Mutation.
Word replacement. 对于原句中的每个单词,搜索上述语料库看是否存在匹配单词,如果找到了一个匹配的词,就替换并生成突变句。与原句相比,每个突变句包含一个替换了的单词,为了减少生成无法解析的突变的可能性,只替换名词、形容词和数字。
Structural filtering. 生成的突变句可能无法解析,因为替换的单词可能不适合句子的上下文,例如“one”和“another”是上下文相似的单词,“a good one”可以解析,而“a good another”不能。因此附加约束检测突变句的合理性,使用基于 Stanford Parser 的 structural filtering,假设原句为 s = w1, w2, …,wi, …, wn,突变句为 s' = w1, w2, …, w'i, …, wn 中,对于每个句子,Parser 输出 l(wi),即每个单词的 POS tag,如果 l(wi) ≠ l(w'i),说明句法结构发生了变化,所以将 s' 从候选中删除。
2.3 Automatic Test Oracle Generation
测试时使用 oracle 增强生成的输入,假设句子中没有变化的部分保留了充分性和流利性(充分性指译文是否具有相同的意义、信息是否丢失、增多或失真;流利性是指输出是否流畅,语法是否正确),将源句 s 中的 w 替换为 w' 生成 s',两个句子的翻译分别为 t(s) 和 t(s'),希望在计算 t(s) 和 t(s') 的相似性时忽略单词 w 和 w' 的翻译,但是要去掉它们的影响并不容易,因为它们可能会改变整个句子的翻译,且很难准确地将 w 和 w' 映射到译文中与其对应的词。
为了绕过这个问题,计算 t(s) 和 t(s') 子序列的相似度,并使用最大相似度近似 t(s) 和 t(s') 的一致性,算法1展示了这个过程。对于 t(s) 和 t(s'),首先使用 GNU Wdiff 获得 difference slices(第1行),GNU Wdiff 以单词为基础比较句子,对比较两个文本中有几个单词被更改非常有效,Wdiff 可以将两个句子“A B C D F”和“B B C G H F”的区分切片分别表示为“A”, “D”和“B”, “G H”。将 t(s) 和 t(s') 的区别切片保存为集合 Bs 和 Bs',然后每次从译文中删除一个切片(第5行和第9行),每个切片对应一个子序列,例如“A B C D F”有两个子序列:“B C D F”(删除“A”)和“A B C F”(删除“D”)。新的 t(s) / t(s') 子序列被添加到集合 To / Tm 中(第6行和第10行)。对于集合 To 中的每个元素,计算它与集合 Tm 中的每个元素的相似度(第15行),得到 |To| ∗ |Tm| 的相似性得分,其中 |To| 和 |Tm| 是 To 和 Tm 的大小,使用最高相似度作为最终一致性评分的结果(第16行)。这种方法减少了突变词的影响,有助于选择不一致的上界,即使相似度最大的两个子序列包含被替换的单词,其他句子部分的相似度也较差,所以这种情况下不太可能被替换的单词所影响(导致出现假正例)。

2.4 Automatic Inconsistency Repair
整体修复过程,及两种突变翻译排序方法(probability and cross-reference)。
2.4.1 Overall Repair Process.
首先修复原句的翻译,然后寻找通过一致性测试的突变句的翻译,算法2为修复过程。对于已经被发现有不一致问题的 t(s),生成一组突变句,并得到它们的译文 t(s1), t(s2), …, t(sn),这些突变句及其翻译,连同原句及其翻译,被放入字典 T 中(第1行),然后使用预测概率或交叉引用对 T 中的元素降序排序,结果存入OrderedList(第2行),接下来使用单词对齐获得 s 和 t 之间的映射单词 a(s)(第3行),单词对齐是一种自然语言处理技术,当且仅当两个单词具有翻译关系时它们才会被连接起来。特别地,使用 Liu et al. 提出的技术,一种用于无监督单词对齐的 latent-variable log-linear 模型。然后检查 OrderedList 中的句子对 (sr, t(sr)) 是否可以用于修复原始翻译,按照排序顺序,直到找到一个可以接受不一致性修复的突变句翻译。如果 sr 是原句 (sr == s),意味着原始译文被认为是比其他突变译文更好的选择,所以不动它(第6-8行);否则,继续对 s1 和 t(s1) 进行同样的操作。变量 表示 s, sr 中替换的单词,通过对齐(第9-12行)得到翻译后的单词

单词对齐并不是100%准确的,如果直接将 替换为
进行翻译,可能会出现语法错误或上下文不匹配问题,判断替换是否可以接受的策略有:1) 限制
必须属于同一类型(数字或非数字,第13-15行);2) 如果被替换的单词是非数字类型的,使用 Stanford Parser 检查替换是否会导致结构更改(第17-21行)。
在修复突变句翻译时(第22行),使用原句的修复结果(第23行),然后检查二者是否一致(第24-26行),如果不一致,就继续检查其他的候选项。
2.4.2 Translation Ranking based on Probability
对于一个句子 s 和及其变体 S = s1, s2, …, sn,t(s), t(si) 分别为 s, si 的翻译,记录每个 t(si) 的翻译概率,并选择最高的一个作为候选翻译,使用单词对齐生成最终修复后的翻译。这是一种灰盒修复方法,既不需要训练数据,也不需要训练算法的源代码,只需要机器翻译提供的预测概率,但该概率信息为方法的内部属性,通常不会提供给最终用户。
2.4.3 Translation Ranking based on Cross-reference
对于一个句子 s 及其变体 S = s1, s2, …, sn,t(s), t(si) 分别为 s, si 的翻译,计算 t(s), t(s1), t(s2), ..., t(sn) 之间的相似度,并使用将最佳译文(平均相似度得分最大)译文与其他译文映射并修复之前的译文。这是一种黑盒修复方法,只需要翻译器的输出。
3 EXPERIMENTAL SETUP
3.1 Research questions
RQ1: How accurate are the test inputs of TransRepair?
随机采样一些候选对并手动检查有效性,确保 TransRepair 确实生成了适合一致性检查的输入。
RQ2: What is the bug-revealing ability of TransRepair?
为了评估 TransRepair 的 bug 发现能力,比较手动检查与自动测试(根据相似度度量计算一致性得分作为测试 oracles,确定是否检测到 bug)的结果。
RQ3: What is the bug-repair ability of TransRepair?
通过一致性度量和手工检查记录修复了多少不一致的 bug,并手动检查 TransRepair 修复的译文是否提高了翻译的质量和一致性。
3.2 Consistency Metrics
使用 t1、t2 表示原始、突变的翻译输出,考虑四种度量不一致性的方法:
LCS-based metric
通过 t1、t2 之间的一个最长公共子序列的标准化长度度量其相似性:
![]()
LCS是一个计算 t1、t2 之间以相同的相对顺序出现的一个最长公共子序列的函数,例如序列“ABCDGH”和“AEDFHR”的LCS是长为3的“ADH”。
ED-based metric
基于 t1、t2 之间的编辑距离,编辑距离是计算将一个字符串转换为另一个所需的最少操作量以衡量二者差距的方法。标准化编辑距离使用以下公式,其中 ED 是计算 t1、t2 之间编辑距离的函数。
![]()
tf-idf-based metric
tf-idf 可以用来衡量词频方面的相似性,单词 w 的权重为:
![]()
其中 C 是一个文本语料库(本文使用 Transformer 的训练数据),|C| 是句子总数,fw 是包含词 w 的句子数量。句子使用词袋法表示,忽略语法和词序。向量的每个维数都与它的权值 widf 相乘,计算 t1、t2 加权向量的余弦相似度作为最终的 tf-idf 一致性得分。
BLEU-based metric
计算句子匹配子序列的个数、pn(n-gram precision,n 为子序列长度)和过短翻译惩罚因子(c 为 t(si) 的长度,r 为 t(s) 的长度),BLEU 的公式如下,其中 wn = 1/N(N = 4)为 pn 的权值。
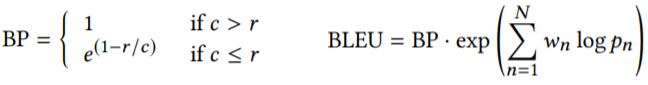
由于 BLEU 是 unidirectional 单向的,BLEU(s, s') ≠ BLEU(s', s),使用较高的分数来作为 s、s' 之间的相似度,这与算法1中的想法是一致的:获得一致性的一个上界,避免出现翻译错误的假正例。
3.3 Machine Translators
黑盒实验使用谷歌翻译,无法获得训练数据和代码;灰盒实验使用 Tensor2Tensor 深度学习库实现的 Transformer,三个训练数据集为:CWMT--7,086,820个平行句、UN--15,886,041个平行句、新闻评论集--252,777个平行句,验证数据也来自新闻评论集的2,002个平行句,训练50万个epochs。
3.4 Test Set
谷歌翻译和 Transformer 的测试集为新闻评论集的2001个平行句,实验配置:Ubuntu 16.04,256GB RAM,4个 Intel E5-2620 v4 cpu (2.10 GHz),32核,神经网络都是在单个 Nvidia Titan RTX (24GB memory) 上训练的。
4 RESULTS
4.1 Effectiveness on Input Generation (RQ1)
对于每个测试句,生成突变句并检查它们是否通过了结构过滤,每句最多保留5个通过过滤的突变句(第5节研究突变句数量的影响)。2001个测试句一共生成21960个突变句,过滤掉17268句保留4692句作为测试输入,作者随机抽取400句手动评估它们是否能够检测翻译不一致性,查看突变句的替换词是否会导致语法错误、突变体的翻译是否与原句一致。这一验证步骤发现了三个无效的突变句:1) He was a kind spirit with a big heart: kind → sort;
2) Two earthquakes with magnitude 4.4 and 4.5 respectively: Two → Six;
3) It is in itself a great shame: great → good.
400句中其余的397句符合两个有效性标准,准确率为99%,说明两种策略--两个 word2vec 模型的交集、斯坦福解析器过滤--有很高的概率能够产生有效的测试句。400个突变句体和手动评估结果可以在 TransRepair 的主页上找到。下面使用4692个突变句(来自1323个原句)检验机器翻译系统的翻译一致性。
4.2 Inconsistency-revealing Ability of TransRepair (RQ2)
Consistency Metric Values
使用谷歌翻译 GT 和 Transformer 对4692个突变句进行翻译,按算法1将它们与原始句的翻译进行比较,计算每个突变句的四种一致性得分,图3为一致性得分直方图,四种度量都发现了大量得分低于1.0的翻译(约占总量的47%),表明翻译存在不一致性。表1为四种度量不同阈值的不一致翻译个数,可以看到即使在一致性阈值较宽松时,bug 依然存在。

Manual Inspected Inconsistency
随机抽取300个突变句的翻译,其中有两个无法解析,使用剩下的298个翻译进行分析。作者手动检查每个突变句和原句的翻译,当满足下面任何一个条件时,就报告一个不一致的错误:除了突变句的替代词,这两个翻译 1) 有不同的含义;2) 有不同的 tones 声调;3) 专有名词使用了不同的字符表示。手动检查发现了谷歌翻译、Transformer 中107个(36%)、140(47%) 个翻译不一致错误。
Correlation between Metrics and Manual Inspection

比较度量分数和手动一致性评估结果,将298篇带有人工标记的译文分手动分成两组,一组为一致的翻译,另一组为不一致的翻译,检查每组的度量分数。图4显示了结果,虚线左右两侧的点分别为人工标记为一致/不一致翻译的度量分数,左侧大部分点(82.2%)的得分为1.0,左侧平均分0.99高于右侧平均分0.86,表明度量和手动检查的翻译一致性倾向于一致。值得注意的是,左侧有一些得分相对较低的度量,而右侧有一些较高的度量,说明使用度量来评估一致性存在假正例和假负例,详细分析如下:
Threshold Learning
度量分数是连续的值,为了自动报告不一致性,需要为每个度量选择阈值,使度量判断结果接近手动检查。从谷歌翻译中随机抽取100个翻译,手动标记为一致或不一致,然后根据标记选择阈值(从0.8到1.0,步长0.01),使得每个相似度度量的F值最大。这种方法确定的 LCS、ED、tf-idf、BLEU 的最佳阈值分别为 0.963、0.963、0.999、0.906,F值分别为 0.81、0.82、0.79、0.82。当度量分数低于 so-identify 阈值时,就报告一个不一致错误。为了了解所选阈值在多大程度上捕获了一致性和不一致性之间的边界,分别使用谷歌翻译和 Transformer 对之前采样的298个翻译对阈值进行测试,结果如表2所示。

假正例 FP 表示阈值判断翻译不一致、但人工检查是一致的,假负例 FN 表示阈值判断翻译是一致的、但人工检查是不一致的。从表中可以看出,FP 和 FN 的比例都在10%以下,这是可以接受的。手动检查 FP 和 FN 后,发现 FN 可能是由一个小的字符差异、但具有不同的含义或语气引起的,例如,一个突变句翻译有一个额外的 er(意思是“but”),但它不出现原始翻译中,人工检查认为这是不一致的,而度量评价则相反。当两个翻译中有许多含义相同的不同词语,可能会出现 FP,例如,中文短语“尚未”和“还没”都是“not yet”的意思,但每个短语的汉字完全不同。测试时 FP 可能带来的害处在于有可能使翻译变得更差。
Overall Number of Inconsistency Issues
阈值确定后用于4592个输入的翻译(100个已经用于阈值学习),检查其中有多少个低于阈值,结果表明,Transformer 不一致的翻译结果是--LCS: 1917 (42%); ED:1923 (42%); tf-idf: 2102 (46%); BLEU:1857 (40%)。总的来说,大约五分之二的翻译低于选择的一致性阈值;谷歌翻译不一致的翻译结果是--LCS: 1708 (37%); ED:1716 (37%); tf-idf: 1875 (41%); BLEU:1644 (36%),这表明在一致性方面,谷歌翻译比 Transformer 要稍好一些。
4.3 Bug-repair Ability (RQ3)
4.3.1 Improvement Assessed by Metrics
对所有不一致的翻译进行修复,并检查有多少个翻译可以用刚才的方法修复。对于每个句子,生成16个待修复的突变句,结果见表3,其中每个单元包含修复方法修复的不一致 bug 的数量和比例,“Probability”列表示概率(灰盒修复)的结果,“Cross-reference”列表示交叉引用的结果(黑盒修复),谷歌翻译只有黑盒的结果。从表中可以看出,TransRepair 平均减少了黑盒 GT 28%的 bugs,灰盒修复了 Transformer 30%的 bugs、黑盒修复了19%到20%的 bugs,表明灰盒和黑盒方法是修复不一致缺陷的有效方法。

4.3.2 Improvement Assessed by Human
手动检查先前标记的298个抽样翻译的修复结果的 LCS 指标,有113/136对在谷歌翻译 / Transformer 上的翻译不一致,因此修复针对这些句子对的原句和突变句的翻译,基于概率的修复改变了 Transformer 的58对,基于交叉引用的修复改变了谷歌翻译 / Transformer 的39/27对。对于被 TransRepair 修改过的翻译对,手动比较:修复前后的翻译一致性 & 修复前后翻译的可接受性(原句和突变句),考虑充分性和流利性,手动给出“Improved”、“Unchanged”或“Decreased”标签,结果见表4。

前四行是谷歌翻译,其余是 Transformer 翻译,带有“overall”的行表示原句和突变句的翻译接受度都有提高,带有“original”/“mutant”的行表示原句/突变句的翻译修复结果。TransRepair 在提高翻译一致性方面有很好的效果,平均87%的谷歌翻译和 Transformer 翻译的一致性提高了,只有3个翻译一致性降低,其中一个原句的翻译得到了改进,而突变句没有,因此修复后原句改进的翻译与突变句未改进的翻译不匹配;剩下两个是由于修复后原句变差、突变句翻译没变。
修复的主要目的是提高翻译一致性,翻译可接受性的提高是额外的“bonus”,从表4中可以发现,修复约提高了四分之一(27%)的翻译可接受性,而8%的可接受性下降,手动检查可接受性下降的原因是,有时修复方法可能会为了一致性而牺牲质量。
5 EXTENDED ANALYSIS AND DISCUSSION
Example of Repaired Translations
表5为改进误译的一些例子,第一列是翻译输入,第二列是原文翻译输出(转换为拼音),其中斜体字是误译部分,最后一列为改进的翻译。

Effectiveness and Efficiency of Data Augmentation
之前的工作采用了数据增强的方法提高机器学习模型的鲁棒性,对于源代码已知的翻译器,训练数据增强是增加翻译一致性的方案之一,因此设计实验研究添加更多的训练数据是否会产生更好的翻译一致性。使用10%, 20%, ..., 90%的原始训练数据分别训练 Transformer,结果见图5,当比例在0.7到1.0之间时,没有观察到 bug 下降的趋势,这说明增加训练数据对改善翻译不一致性的效果有限。

数据增强需要模型再训练,在当前的配置下使用100%的数据训练模型需要19个小时,且数据收集、标记和处理也需要时间,总之很少有证据表明数据增强是这个问题的好的解决方案。与之相比,TransRepair 具有以下优点:1) 黑盒不需要源代码和训练数据,灰盒只需要预测概率;2) 不需要额外的数据及模型再训练,成本更低;3) 更加灵活,可以修复特定的 bug 而不需要改动其他格式良好的翻译。
Efficiency of TransRepair
TransRepair 的 cost 包括检测和修复两部分,实验配置下每句检测时间平均为0.97s;基于概率方法的每句修复时间平均为2.68秒,基于交叉引用的方法为2.93秒。当使用 TransRepair 优化在线实时机器翻译时,对于一个被认为没有 bug 的句子,用户得到最终翻译的时间少于1秒;对于一个被认为有 bug 的句子,需要不到4秒(检测和修复)的时间才能得到最终翻译。
Influence of Mutant Number
在不一致检测和修复过程中都会产生突变句,默认设置是每个句子最多生成5或16个突变句。为了研究突变句的数量如何影响检测和修复性能,对1或3个突变句进行重复实验进行检测,对4或8个突变句进行修复,然后比较不一致 bug 数和修复的 bug 数。由于论文空间有限,仅给出灰盒修复的结果,如表6所示,完整的结果可以在主页上找到。可以看到在检测时,使用更多的突变句有助于发现更多不一致的问题;修复也是如此,但是使用4个突变句也可以得到可接受的结果。

Application Scenario
TransRepair 可以端到端应用,给定输入和翻译器,将自动测试和修复翻译输出,并向用户提供新的翻译输出。















 1738
1738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









