







声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
learn2sing target speaker singing voice synthesis by learning from a singing teacher
本文是西北工业大学语音和语言处理小组和北京标贝科技有限公司发表的文章,主要是使用普通语音来学习歌唱合成,具体的文章链接
https://arxiv.org/pdf/2011.08467.pdf,demo的链接
(这种使用普通语句合成歌唱的研究适合用户制作个性歌曲的应用)
1 背景
SVS(singing voice synthesis)是根据歌词和乐谱合成歌声,这些任务需要大量的歌唱音频和歌词乐谱。然而,很多用户并不会唱歌,因此如何使用普通的语音来合成歌唱成为有趣的研究。目前,可选的研究方案为singing voice conversion和tacotron2-gst,但这些方案需要参考的歌唱音频作为输入。本文设计了一种只输入歌词和乐谱就可以让普通语音合成歌声的系统,实验验证本方法可行。
2 详细设计
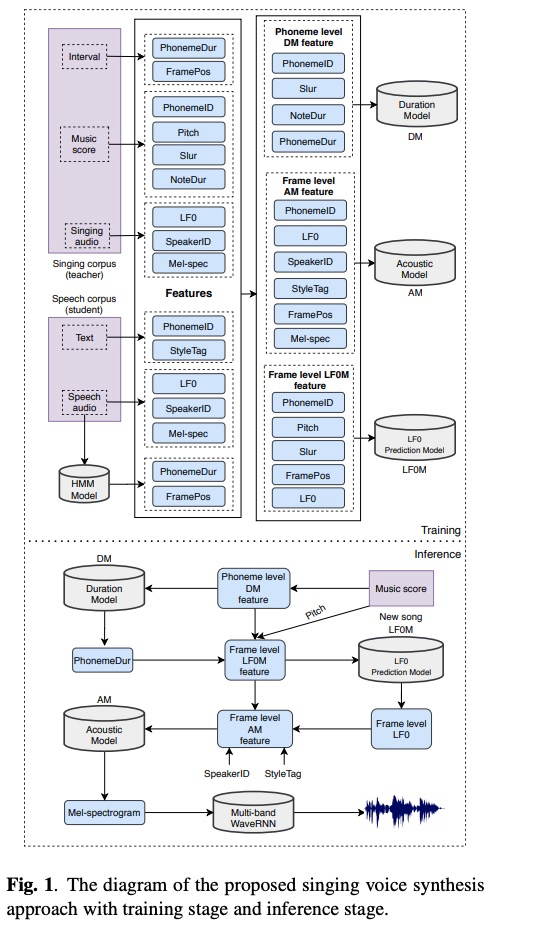
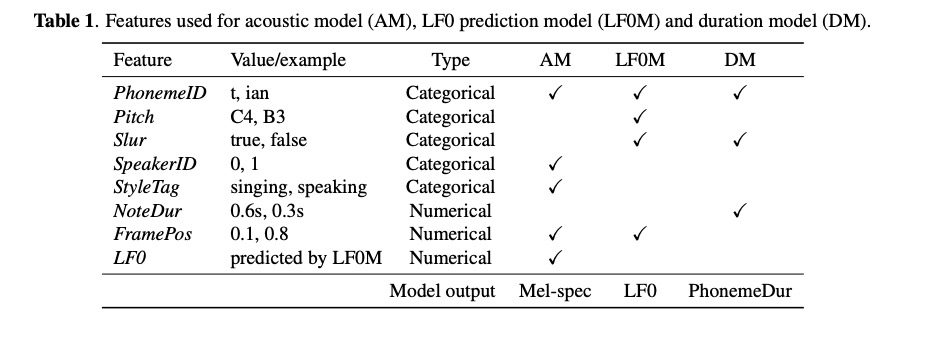
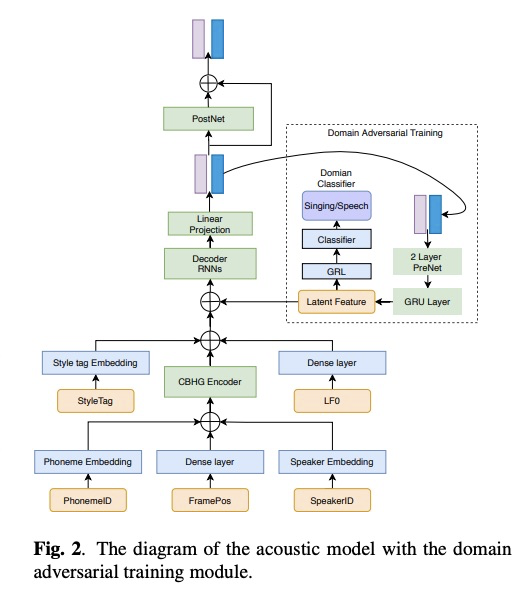
这里我不在啰嗦了,直接进入主题。该系统主要包含三个模型(图1所示):Duration model (DM), LF0 prediction model (LF0M)和Acoustic model(AM),其中AM模型使用可domain adversarial training(DAT)进行歌唱类型解耦。另外,训练和推理阶段如图一所示,简单明了,而且每个模型的输入特征如table 1列出。其中声学模型如图2所示的encoder-decoder架构,其decoder为自回归模式(AM就是去掉attention的tacotron,因为已经有duration model了)。当进行推理阶段,先使用乐谱进行音素的duration预测,然后进行LF0的预测,最后设定目标speaker id和sing 的style tag进行声学特征的推理,最后使用声码器合成音频。
3 实验
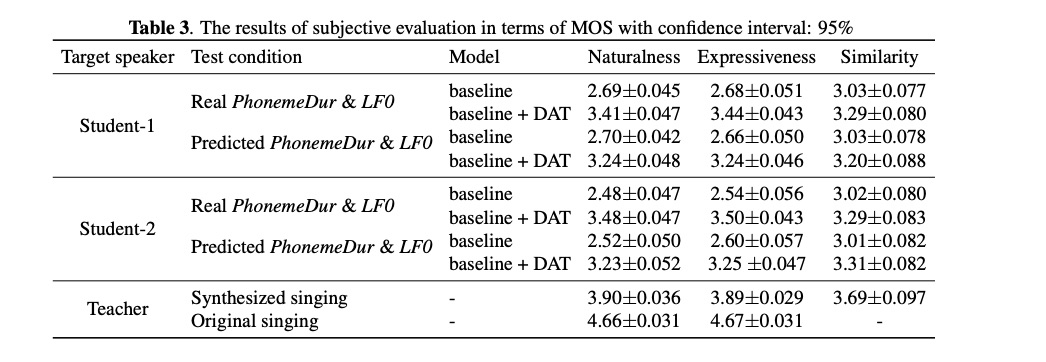
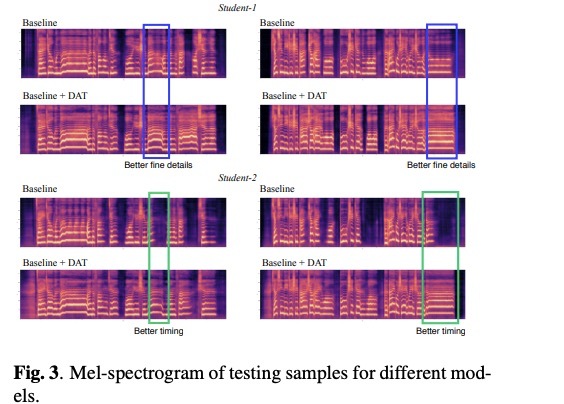
首先对比客观的指标,由table 2显示三个指标结果,其实最主要还是主观的听感。table 3的主观MOS测试显示,普通语句student 1和2 可以合成音乐,而且使用DAT网络效果更好,由图3的语谱图也可以看出使用DAT的频谱刻画更清晰。

4 总结
本文提出了使用普通音频来合成歌唱的系统,我感觉这个需求更适合少数据量的个性化定制,合成的音频还有待优化。















 2635
2635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











