









语音合成TTS
学习李宏毅课程。
输入文字,输出语音。
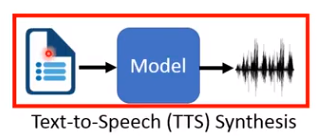
端到端之前TTS
18世纪就有,能找到demo的是1939年VODER。
就像电子琴一样,用手控制发出不同声音。

到1960年,IBM计算机能合成出歌唱声。
波形拼接
过去最常用的商用语音合成系统:
就是在库里对每个音都存起来,比如说你好吗,就把这三个字的音从数据库里找出来,拼接在一起。
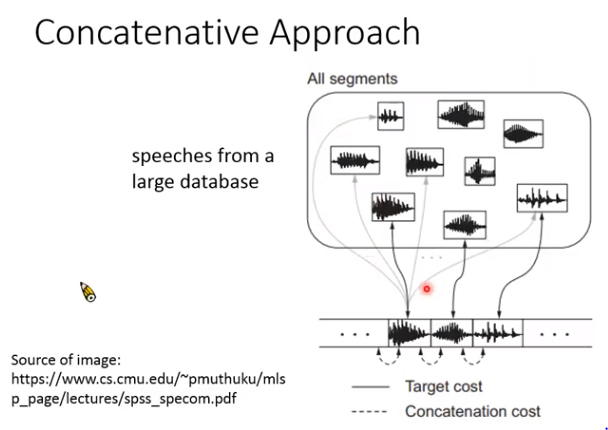
局限性:1. 不自然;2. 要男女声都有,数据库非常大。
随着机器学习的发展,出现了:
参数合成
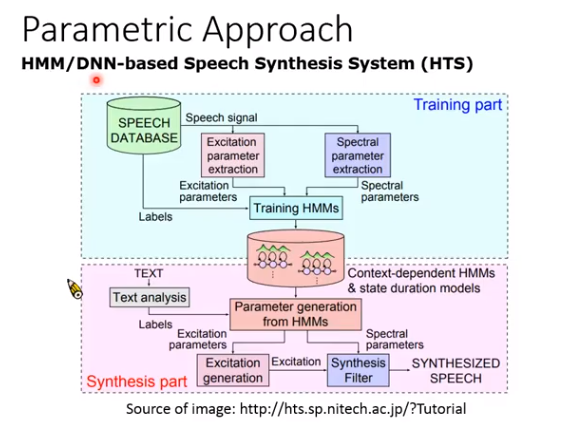
机器输出概率最大的那个,但概率最大的讲就是均值,所以很长一段都是同样的输出,听起来比较奇怪,但也有人解决这个问题,不过解决方法都很复杂。
后来,进入深度学习时代。
Deep Voice
每个蓝色模块都是基于深度学习的。当时人们只是想到对每个部分进行训练。
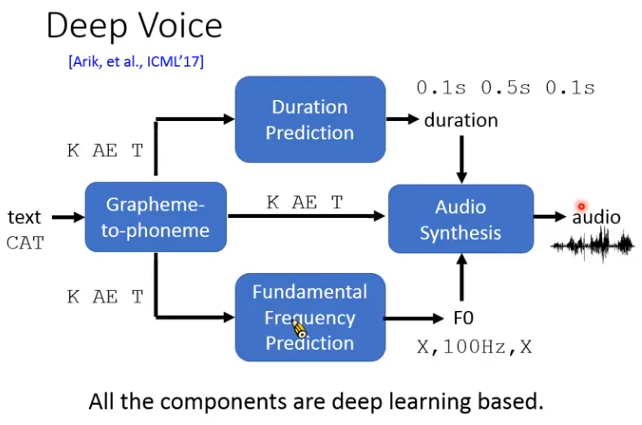
如果把上面每个模块都串起来一起train,就是端到端TTS。
端到端TTS
早期端到端TTS
早期人们尝试输入音素,输出如基频,频谱等声学特征,然后用声码器合成。或者输入字,输出声学特征。

Tacotron
而tacotron是最狂的,输入文字,直接输出语谱图,然后就能线性变换到波形。

tacotron字面是什么意思呢?
taco是一种食物,墨西哥卷饼。tron就只是为了增加科技感。

Tacotron结构
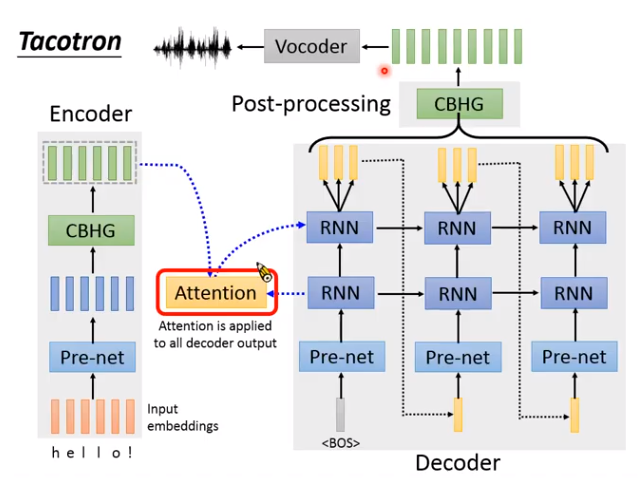
Encoder:
把输入的文字转成一组向量。
甚至输入可以有标点符号,让机器学到逗号就是停顿,句号就是结束,感叹号就很惊讶的样子等等。
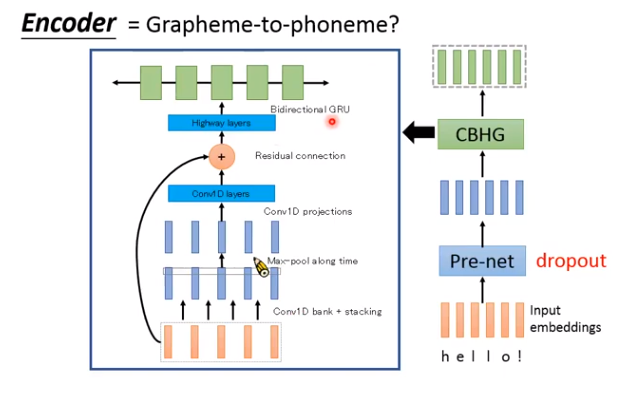
- Pre-net:就是几层全连接的神经网络。
- CBHG:一个比较复杂的模块。(CB就是Conv Bank;H就是Highway layers ;G就是GRU)
为什么要用CBHG,可以不用吗?
可以,v2版本就没用了。

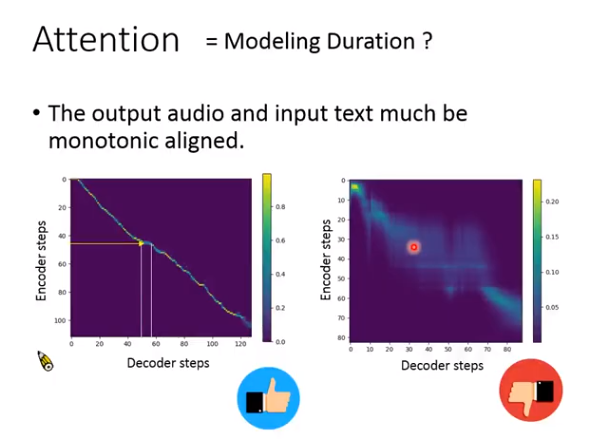
Attention
文字和声音要有个对应的顺序。
哪段文本,对用声音的哪段语谱。这个对应关系的建模就用attention机制,如下图,如果是左边很好的一条对角线,就说明结果比较好,右边的比较模糊,说明模型有问题。
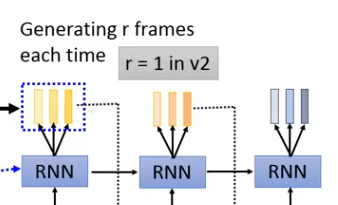
Decoder
将encoder编码的向量,解码成语谱。注意,Decoder每次会输出好几个向量(why?因为语音信号比较长,一个向量才几毫秒,太短了,多输出几个减少运算量)。第一代里r=3或5。第二代r=1。
Decoder整体结构如下,如何判断句子结束呢?把RNN接上一个二分类器,输出小于0.5就继续,大于0.5就结束。
训练的时候,输入有正确答案,测试的时候没有,导致mismatch。但有个dropout机制,在训练的时候模拟出错的情况。
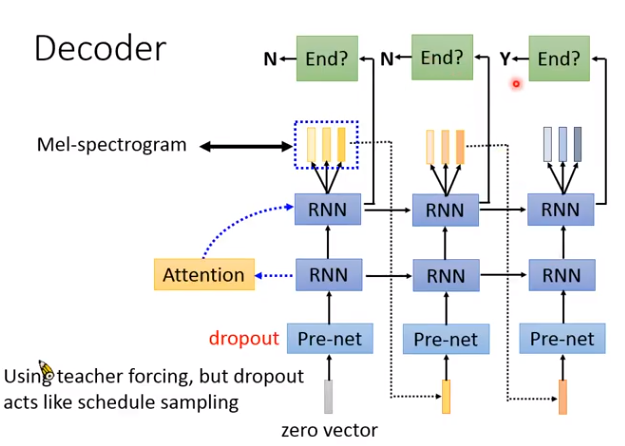
Post processing
在第一代里是CBHG模块,第二代里就是一堆卷积。
后处理的神经网络作用:
Non-causal,就是可以看整段向量是什么。
对Decoder输出的向量做检查修正。
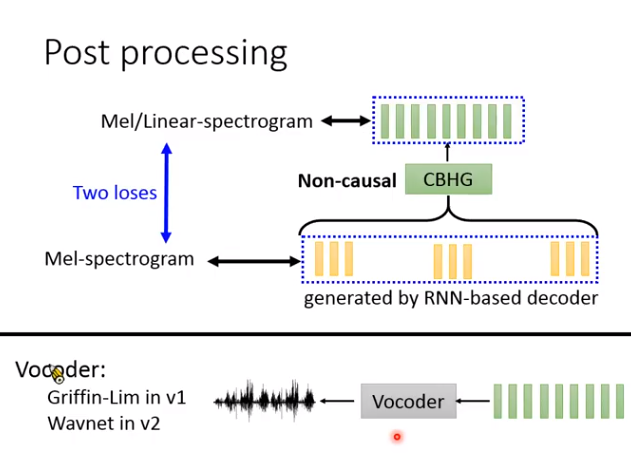
Tacotron系统好坏?
可以看到第二代很强,一个关键原因是换成了神经网络声码器。

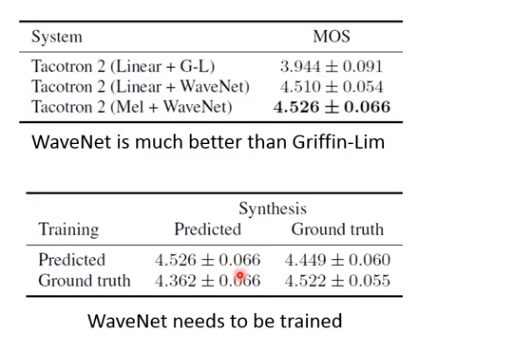
有个很重要的发现:
Tacotron在推理阶段要加dropout!!!
为什么呢?一般dropout在训练时用,推理时要去掉。但Tacotron推理要是不用的话压根出不来人声。目前还没有好的解释为什么。
Tacotron之后
问题一:
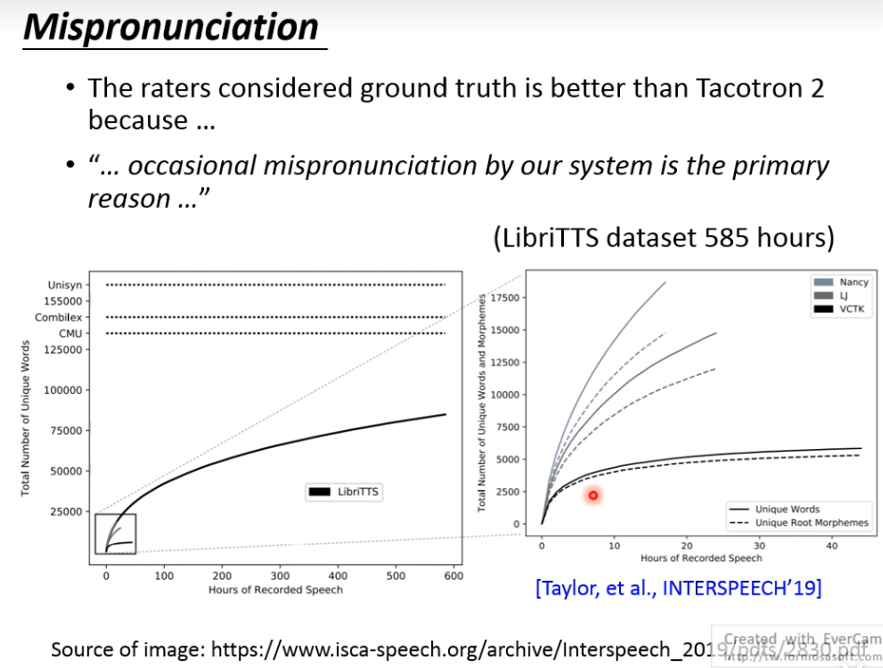
tacotron的音质已经接近真人,但会拼错字。
为什么呢?
语料库的词汇不够。目前最大的语料库如LibriTTS,有585小时语音,但包含的词汇量不到十万个。所以tacotron看到新词,就会念错。
解决法1:输入从文字word换成音素phoneme。
把正确发音加入词典中。

解决法2:把文法信息也输入进去。
解决法3:把Bert embdding作为输入。
BERT能把每个词汇抽出它的表示(包含丰富语义信息)
问题二:对齐问题
Attention
纵轴:encoder输出
横轴:decoder输出
最好是一条对角线。
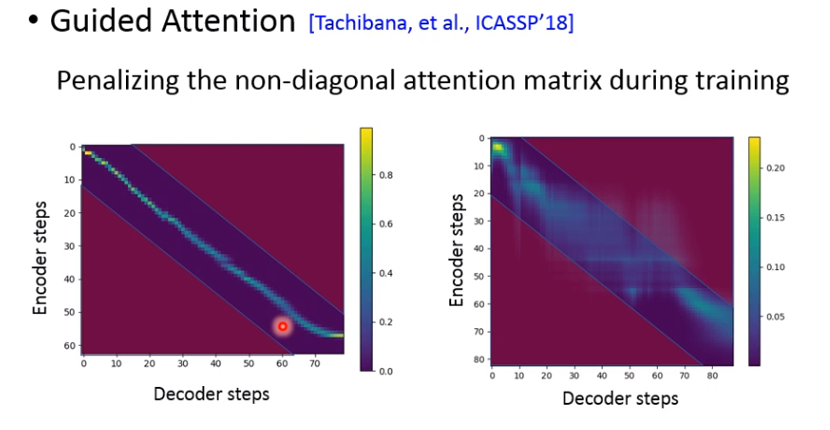
在训练时的loss上多加一个正则项,用来制约,即有禁止进入的区域。
Guided Attention:
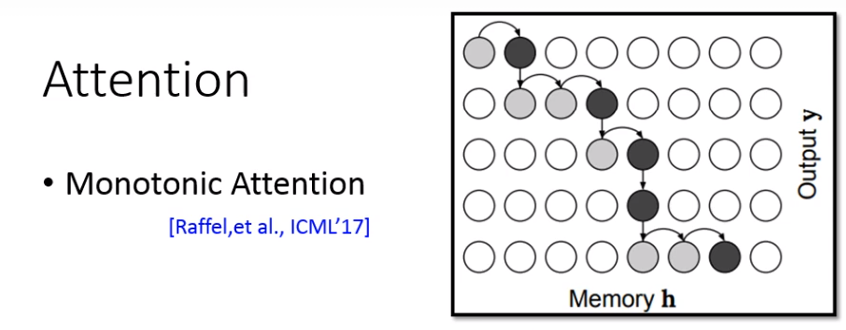
单调Attention:
这种要求Attention必须由左向右。
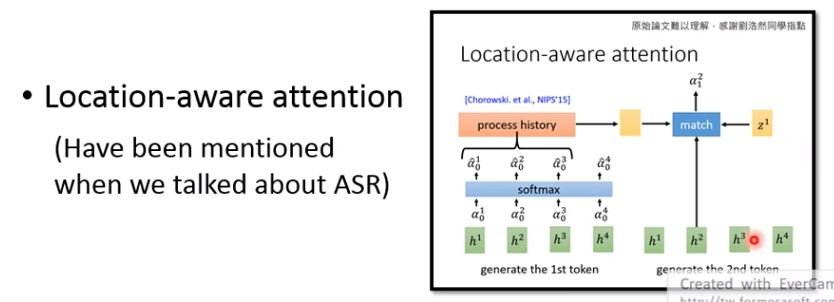
定位意识Attention:
在语音识别中也有。
还有很多其他方法。
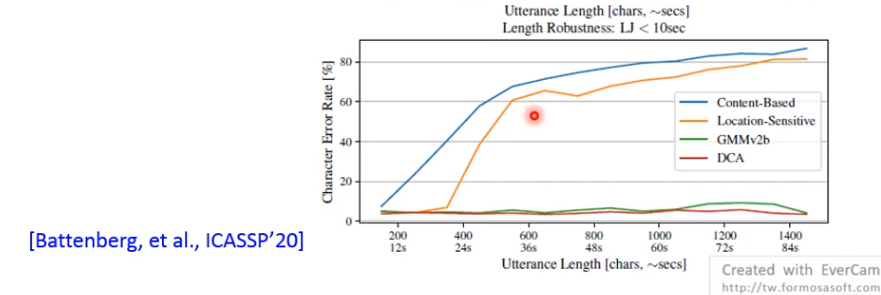
GMMv2b,DCA等。训练的时候用时间<10sec的句子,推理的时候用长句子,随句子越长,很多attention崩塌了。
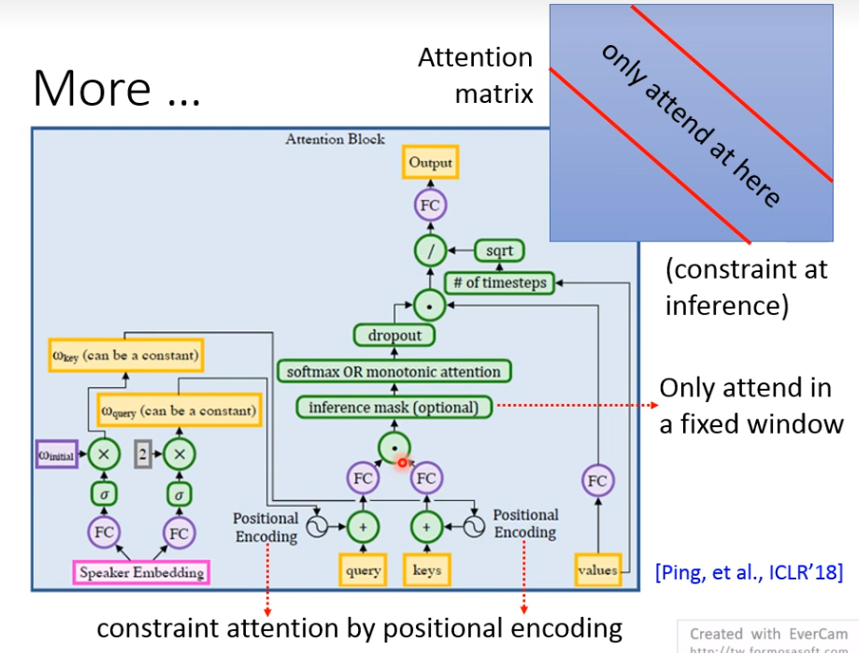
还有这篇文章,只在推理阶段mask,从Speaker Embedding中得到位置编码。
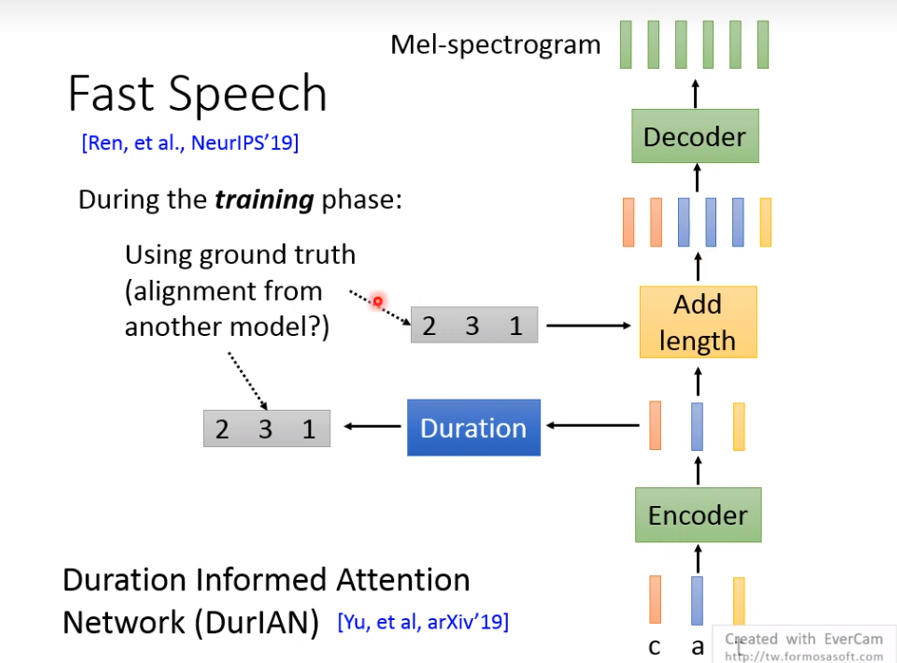
Fast Speech
需要ground truth,知道每个音素character对应哪段mel-spe。那这个对应关系怎么得到呢?
先训个tacotron,根据attention得到这个对应。理论上,也可以用个语音识别系统ASR,做下force alignment。
重读,漏读,错读,Fast Speech相比好很多。
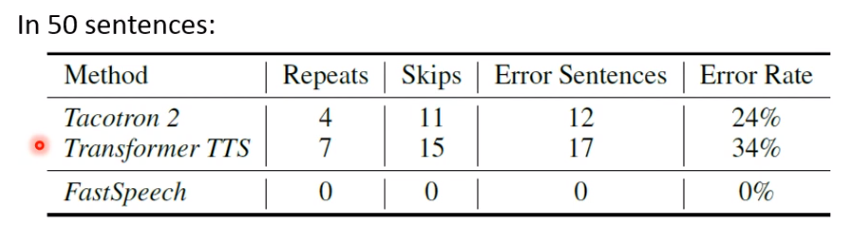
难道Tacotron效果就这么差?其实也没这么夸张,如果推理数据和训练数据类型差不多的话,它就会有好的表现,作者故意找了50句对语音合成有挑战的句子:

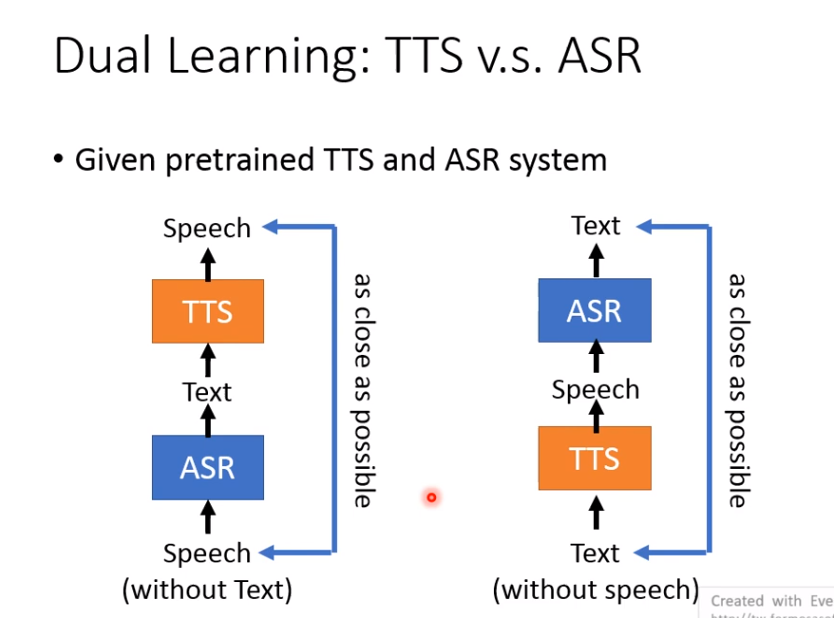
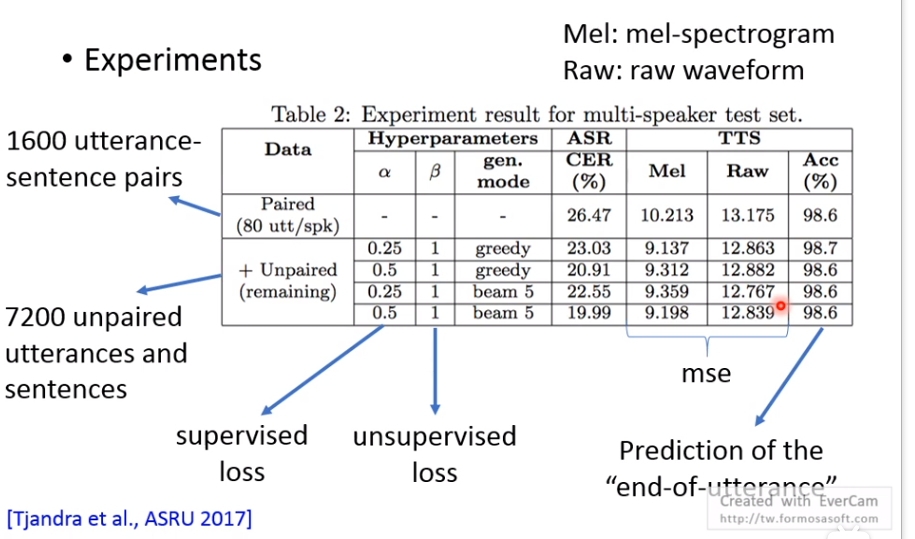
Dual Learning: ASR & TTS
把这两个接在一起,可以互相增进彼此能力。
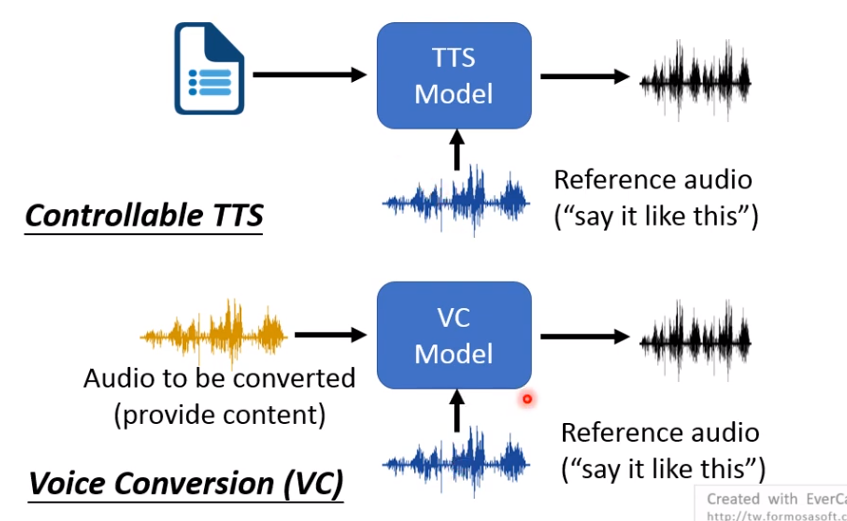
Controllable TTS
Speech:关注说什么,怎么说,谁在说。

如果想让机器输出抑扬顿挫的话,给机器一个reference的语音,形象一点,教机器请你跟我这样说。和语音转换,它们的训练方法很类似。
怎么训练 Controllable TTS?
输入一段文字,一段reference的语音,端到端的训练。
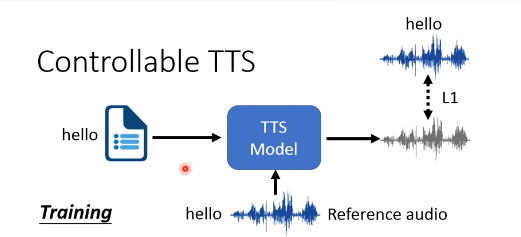
但是存在的问题是:
这个Model可看作autoencoder。如果机器学学到reference的语音和目标语音是一模一样的,就可以最小化误差。然后它就不管文字是什么,直接复制referenc的语音就可以啦。你想让它说hello,结果它直接复制了I love you的语音内容,这显然不是我们想要的。
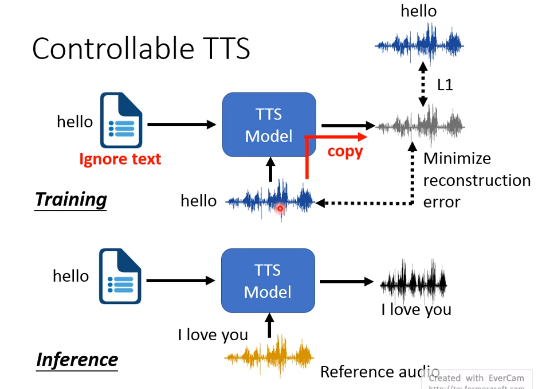
那怎么才能让Model只抽取reference语音的语者信息?
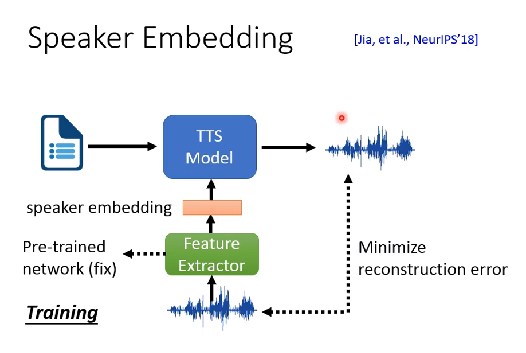
法1:Speaker Embedding
用个预训练模型,输出的向量只包含语者信息,训TTS Model时,就固定住这个预训练模型。就只需要少量的refenrence 语音。
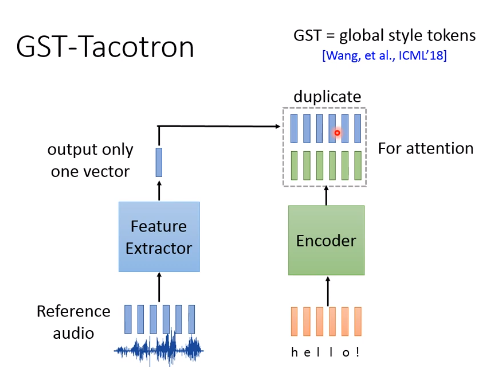
法2:GST-Tacotron
GST = Global style tokens
特征提取网络输出一个向量,把这一个向量复制,长度和Encoder输出的向量长度一样。然后,有人把这两组向量拼接,有人相加(结果差不多),再做一下attention,就和原来tacotron一样。
问题是,特征提取怎么保证不抽取说话人信息?
做了如下设计。
首先特征提取网络里有个encoder,其输出一个向量,作为Attention的权重,特征提取网络参数的一部分vector set,把它两想乘相加,得到最终的一个输出向量。
怎么保证特征提取网络输出的就是style的tokens,而不是说话人呢?因为谷歌当时训练的时候只输入了单一人的音频,所以没有语者信息。
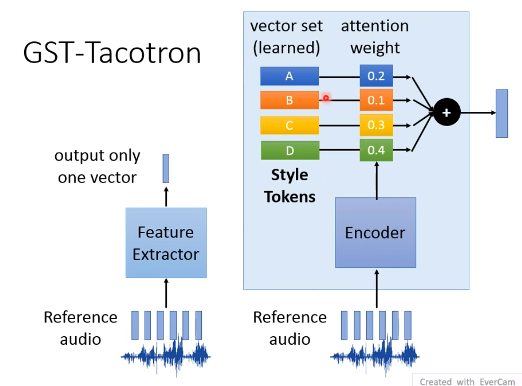
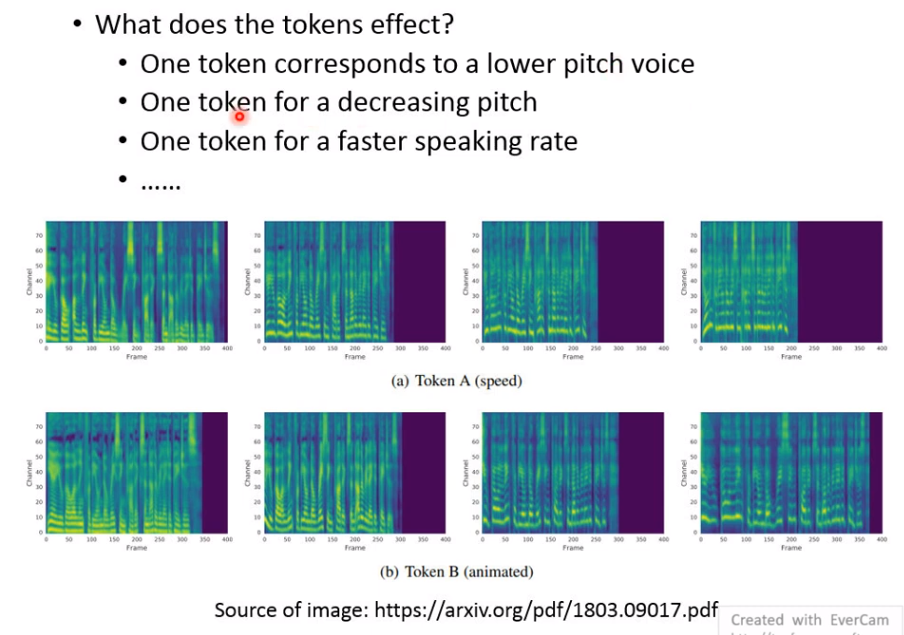
人们发现,vector set里面的每个token,对应着音高,语速等等的变化,可以手调weight。
比如下图,Token A代表语速,Token B代表戏剧化,通过调attention weight,高低起伏越来越大。
法3:Two-stage Training
训练的时候就输入文本内容和reference语音内容不一样。
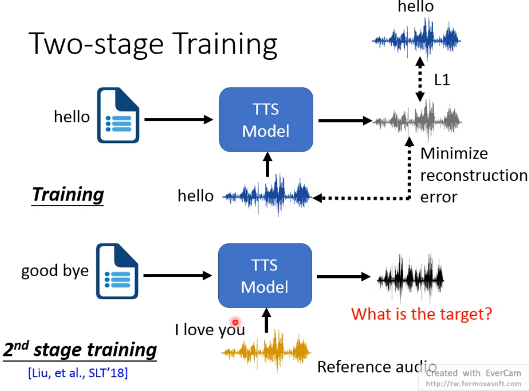
但问题是,不知道ground truth应该长什么样?
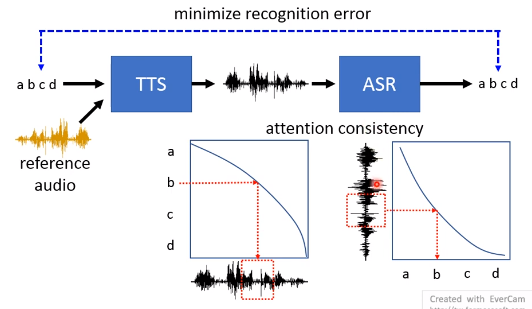
后面接个ASR系统。有点像GAN。可以保证输出的内容是想要的。
如果TTS和ASR都是端到端Attention的,就像他们的Attention一致,可以作为训练目标。
Tacotron2实战
理论
2017年谷歌提出。

输入:文本T
输出:梅尔语谱特征F
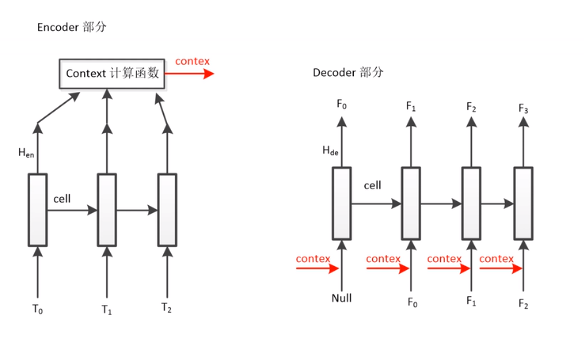
训练时,额外输入声学特征(梅尔语谱),叫作force teaching。测试时,就不需要了,直接将上一时刻的输出作为输入。
那训练时能不能不要额外输入声学特征,直接用上一时刻输出?也可以,但效果不太好。
这个网络的缺点?就是context固定。后面引入了Attention。
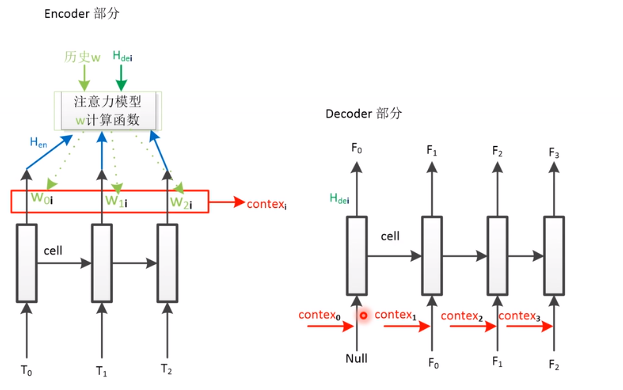
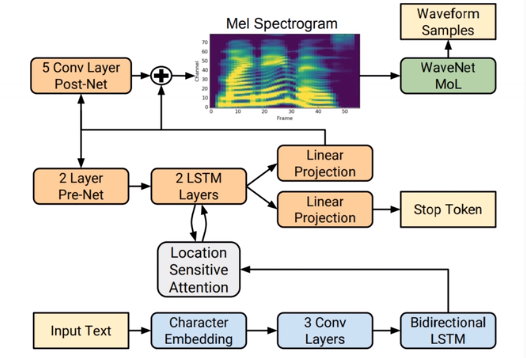
Tacotron2具体结构:(推理过程)















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









