








任务
歌唱合成的目的是给定乐谱和旋律, 合成歌唱音频。歌唱合成系统能够通过训练目标说话人相关的同一语言下的歌唱/语音数据来构建。
目前大多数的歌唱合成系统只支持一种语言,给定说话人的语音数据(同一语言)来合成歌唱声音。如Tacotron2 GST模型加入speaker embedding, pitch 后就能扩展到只用语音数据来进行歌唱合成。但是目前用说话人的非目标语言数据来训练,合成目标歌唱音频是很有挑战性的(如给定说话人的英文语音数据, 希望合成说话人的中文歌唱音频)。
在这篇文章中介绍了一个跨语言的歌唱合成系统。 主要分为四大模块: 基于BLSTM的时长模型, pitch模型, 跨语言的声学模型 和 声码器。
模型
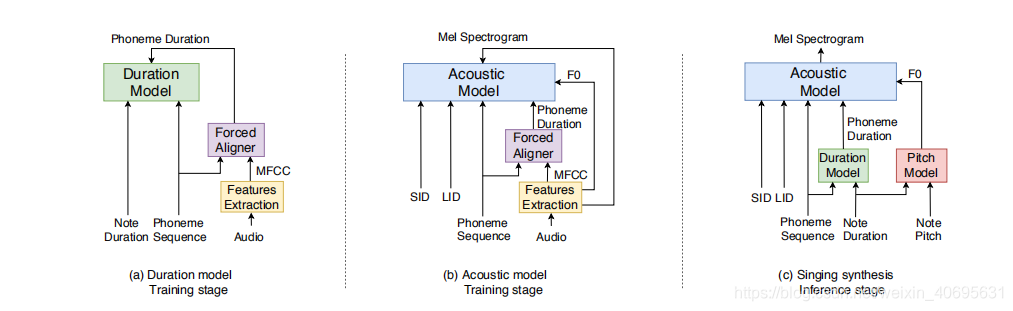
Duration model
在歌唱合成中, 音素的时长严格收到音符的控制, 这和TTS是一个显著的区别。时长预测模型将音素序列和音符时长作为输入, 进而来预测每个音素的时长。音符的时长先转换成帧数(每个音节对应的帧数),将音素序列和对应的音节帧数拼接在一起,作为时长模型的输入。
模型由一个带RELU激活函数和dropout的全连接层(FC), 两层BLSTM组成。 如上图(a)中所示
每个音素的时长是由对齐后的帧数来衡量的。
在inference 阶段, 在时长模型后添加了一个后处理的步骤, 保证预测的音素时长的总和 和 目标音符时长匹配[1]。
M. Blaauw and J. Bonada, “A neural parametric singing synthesizer modeling timbre and expression from natural songs,” Applied Sciences, 2017.
Pitch model
在音乐合成中, 音高是最重要的感知元素, 因为它决定了音乐的旋律。此外, 语音和会影响音高轮廓, 即所谓的微韵律。 这文章中, 简单地使用了启发式规则来对音高进行建模。 首先将音符的音高转成F0, 然后根据音符时长将其扩展到帧级别。 之后用三角形窗口来对F0序列进行卷积。
Acoustic model
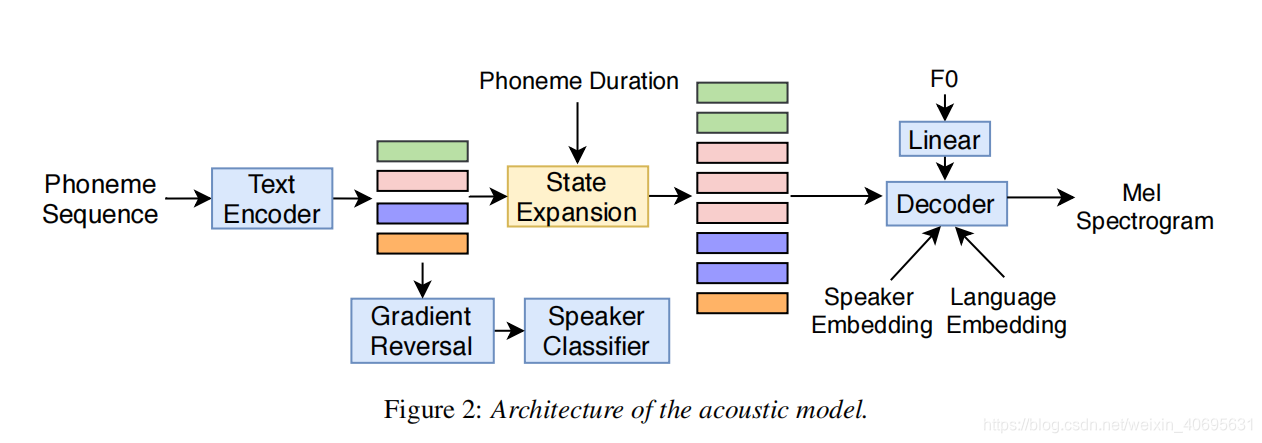
如上图所示, 我们使用了一个encoder-decoder结构的声学模型, 并且加入了说话人分类器。
text encoder的结构是CBHG(包括卷积层, highway network, BGRU)。之后, 使用一个经过对抗训练的说话人分类器来组织文本编码器捕获说话人信息, 其优化目标为:
L
s
p
e
a
k
e
r
=
∑
i
=
1
N
log
p
(
s
i
∣
t
i
)
\mathcal L_{speaker} = \sum_{i=1}^{N} \log p(s_i|t_i)
Lspeaker=i=1∑Nlogp(si∣ti)
其中
s
i
s_i
si是样本i对应的说话人label,
t
i
t_i
ti指的是样本i经过text encoder的输出, N是batch size
为了能够训练说话人分类器和声学模型, 在说话人分类器之前加入了一层 梯度反转层(a gradient reversal layer)[参考文章:https://blog.csdn.net/weixin_40695631/article/details/115346375?spm=1001.2014.3001.5501]
为了保证音素序列, 音符时长和相应的声学特征之间的硬对齐, 解码器显式地以音素时长为条件,在系统中忽略了注意力部分。将文本编码的隐状态按照音素时长沿着时间轴进行复制, F0序列先经过FC再送入decoder。
decoder部分是一个自回归网络,由prenet 两层LSTM和输出层组成。当前时间步的text encoding和F0和prenet的输出, speaker embedding, language embedding进行拼接, 输入到LSTM中。 之后LSTM的输出, text encoding 和 F0进行拼接后经过线性变换来预测目标频谱帧。 预测的特征经过post-net来重构mel谱。
整个模型的损失函数为: 说话人分类器的对抗损失+ post net之前的MSE loss + post net之后的MSE loss。
Experiments
数据集
VCTK: English; multi-speaker
内部数据: multi-speaker Mandarin speech ; a Mandarin singing corpus
setup
乐谱数据是由event tuple 组成的, 包含(ptch , note duration, syllables), 首先使用文本语出里将输入的文本和歌词转换成phoneme sequence。
时长模型用中文歌唱数据训练。
对比试验设置
system1: 声学模型用目标说话人VCTK中的P261和中文歌唱数据训练
system2: 声学模型用VCTK 和 中文语音数据训练
system3: 用VCTK和中文语音数据和歌唱数据
system4:不使用说话人分类器, VCTK+ 中文语音数据。
结果
比较目标和预测结果的F0序列的相似度:
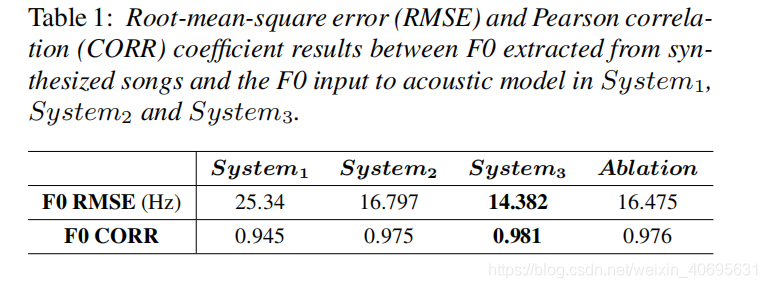
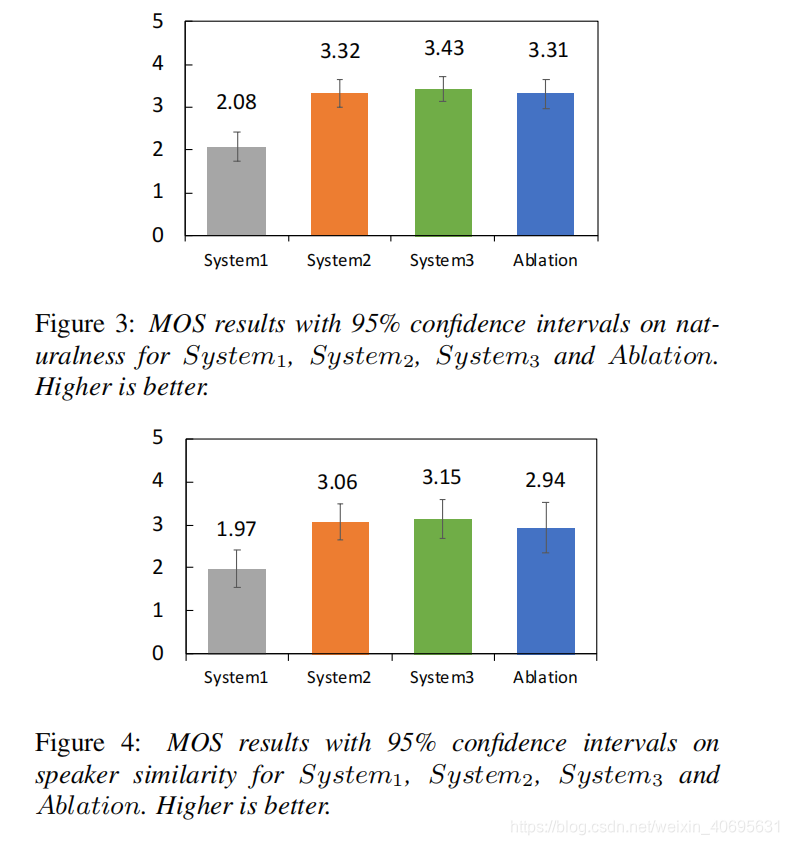
system2 和 Ablation 对比: 说明说话人分类器并没有带来很大的作用。
system3 比synstem1,2 的F0准确率更高, 说明歌唱的数据和多说话人数据对于声学模型的训练是有利的。














 5523
5523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









