







声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。文章同列统计可访问。http://yqli.tech/page/tts_paper.html
如有转载,请标注来源。 欢迎关注微信公众号:低调奋进
A Unified Transformer-based Framework for Duplex Text Normalization
本文为NVIDIA在2021.08.23更新的文章,主要的工作是使用一个模型对Text Normalization和 inverse text normalization两个任务进行建模,从而简化对话系统的管理,具体的文章链接https://arxiv.org/pdf/2108.09889.pdf
1 研究背景
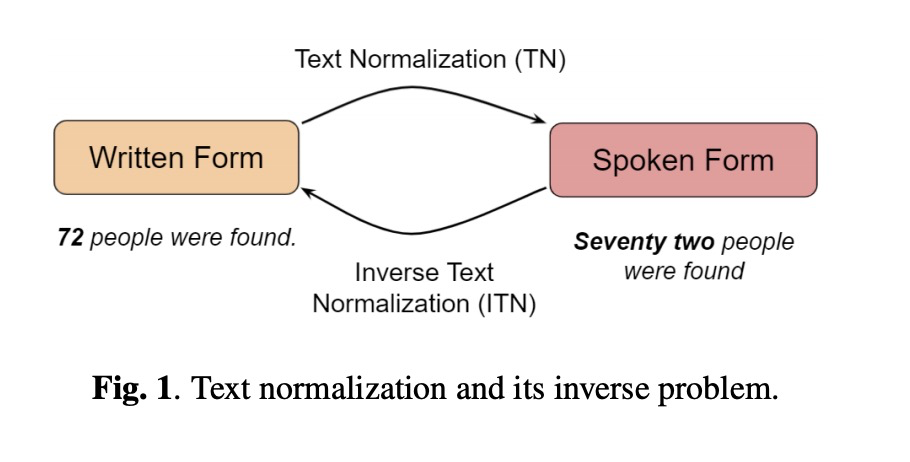
一套完备的对话系统包括DSP、ASR、LU、LG、TTS等等模块,其中TN和iTN任务分别应用在TTS和ASR中。TN工作主要把手写格式转成口语格式,iTN则是逆过程,具体如图1所示。现有系统都是分别对TN和ITN进行建模,这增加了系统复杂度和维护成本,因此本文研究使用一个模型对该两个任务进行建模。
(TN建模一直没有做过实验,一方面缺少语料;另一方面,使用正则也基本上处理大量的case。当然要是具备大量的语料和公司允许,可以玩一下)
2 详细设计
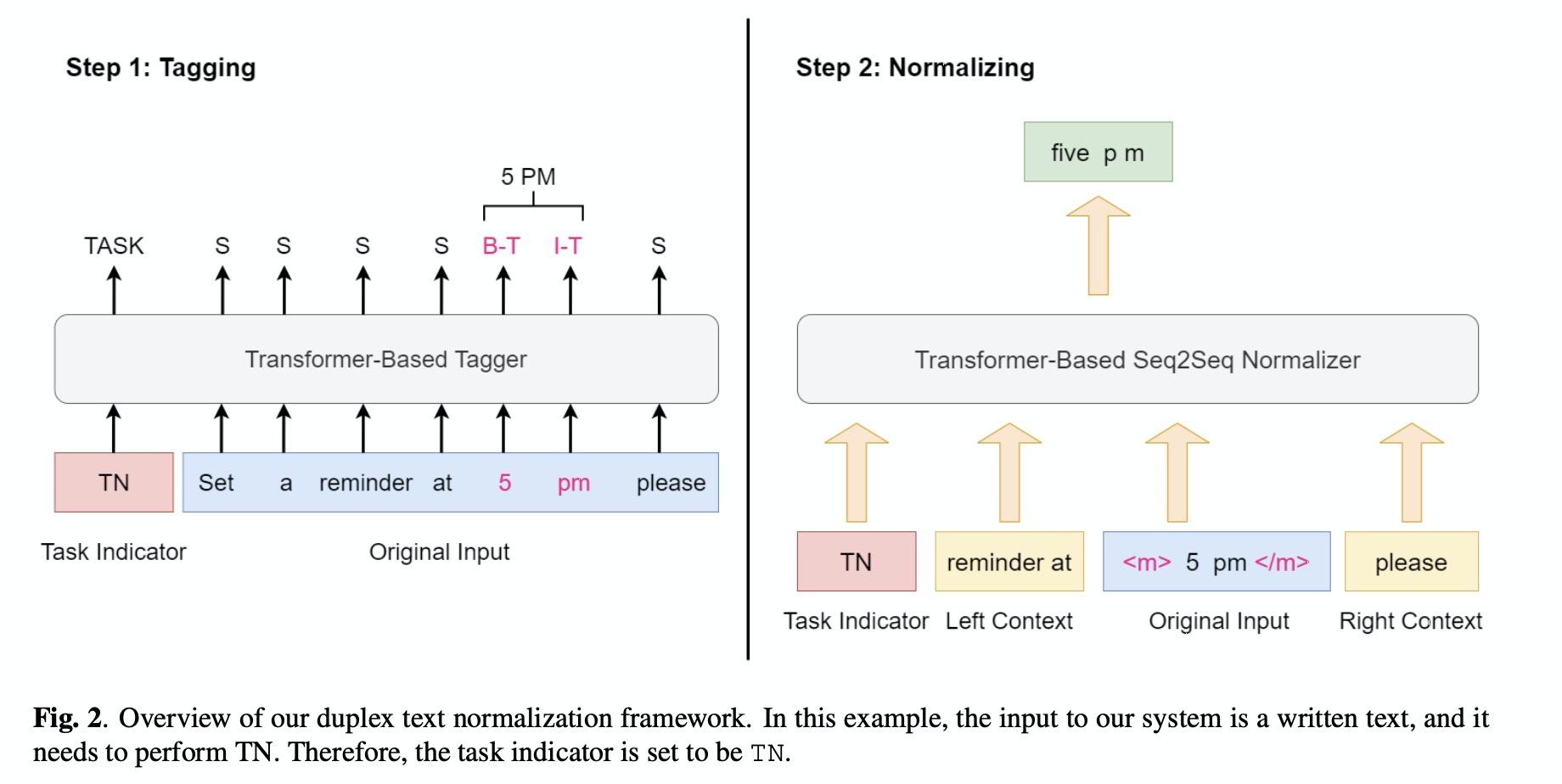
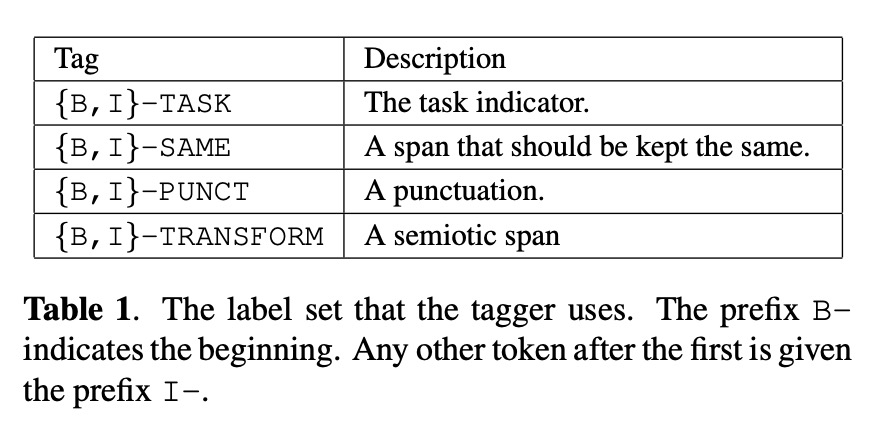
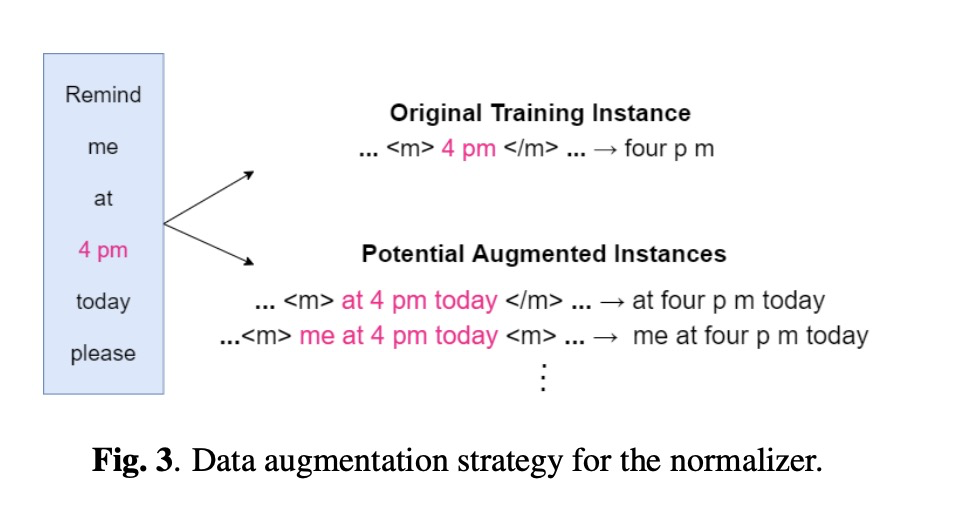
前端语言类的模型基本上不太复杂,本文的系统如图2所示,包括两个部分:Tagger和Normalizer。其中Tagger主要对输入的文本进行分类,判断那部分需要进行TN/ITN处理,其中分类如table 1所示。为了使TN/ITN共用一个模型,因此添加task indicator的前缀。另外Tagger结构为Transfomer。Normalizer则是根据Tagger进行处理,其结构为seq2seq。另外本文也提出了图3的数据增广的策略。
3 实验
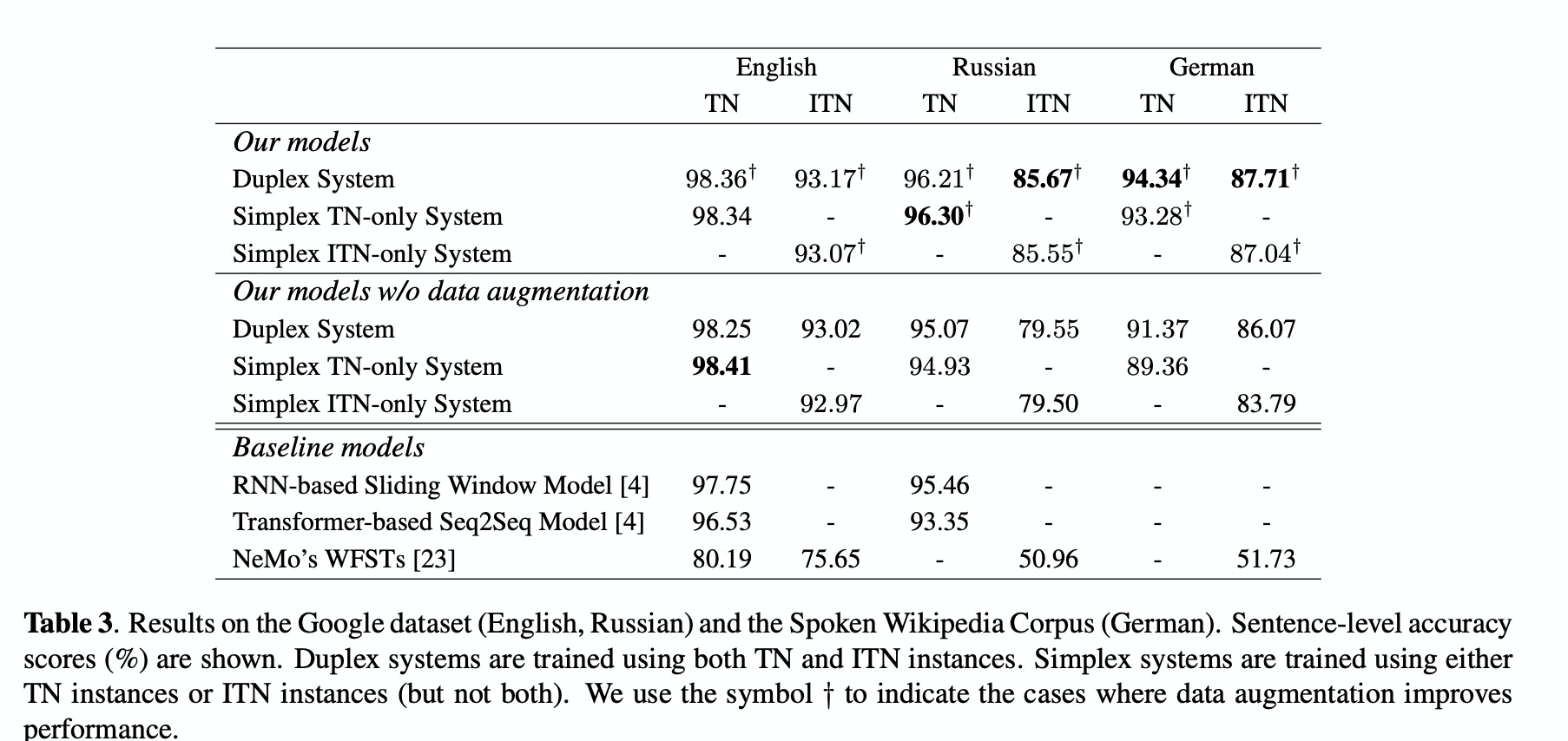
首先从实验结果table 3可以得知三点:第一,数据增广可以提高准确率;第二,多重任务的模型稍微优于分开的单任务模型;第三,本文的方案优于现有的baseline 方案。同时,在内部的数据集上也得出相同的结果,如table 4。

4 总结
本文使用一个模型对TN和iTN双重任务进行建模,不仅简化了对话系统的管理,同时也提高了TN/iTN的句准。















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











