







1.背景
当业务消费消息时,有时因为某些原因(bug、异常、依赖服务故障等)导致消费全部无效,需要回溯消息进行消费,比如消费者2个小时内的处理逻辑可能出现了问题,业务发现后,想回溯到2小时前offset位置重新消费补回相关消息。
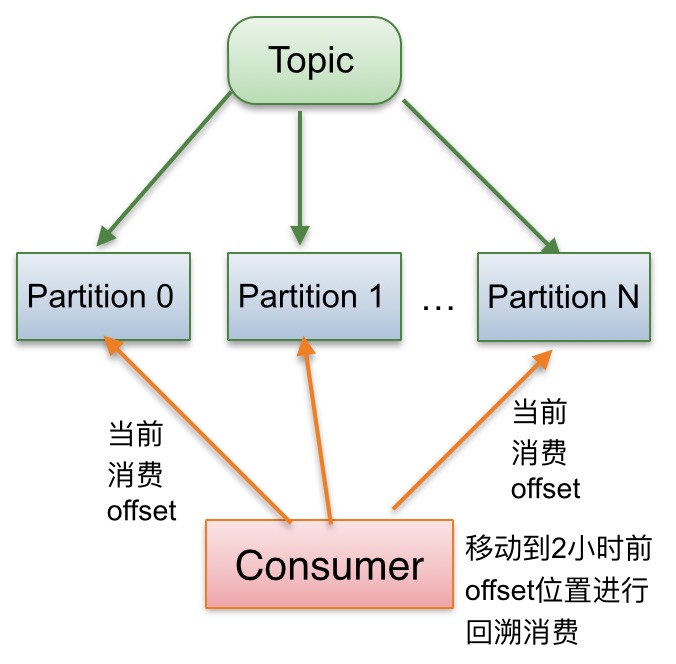
2.总体设计概述
时间粒度消息回溯特性,是基于Kafka源码扩展功能,需要修改Broker和consumer两端代码,要考虑与官方版本升级迁移等兼容性问题,尽量减少代码侵入式修改。
kafka目前已经支持按照offset粒度的回溯消费,如果我们能实现时间戳到offset 的查询也就完成按照时间维度的消息回溯功能,功能分解如下:
- 根据时间戳查找offset
- 根据offset进行消息的回溯功能
3.详细设计
2.1 Kafka文件存储基础知识
请参考:Kafka文件存储机制那些事
2.2 Kafka 消息消费流程
- Consumer发送FetchRequest到Leader Partition所在的Broker
- Broker获取消息的 start offset和size (获取消息的size大小),根据 .index 数据查找 offset 相关的 position 数据,由于 .index 并不存储所有的 offset,所以会首先查找到小于等于 start_offset 的数据, 然后定位到相应的 .log 文件,开始顺序读取到 start_offset 确定 position。
- 根据 position 和 size 便可确认需要读取的消息范围,根据确定的消息文件范围,直接通过 sendfile 的方式将内容发送给消费者。
2.3 利用Kafka如何实现消息回溯设计
在Kafka文件存储机制那篇博客已经提到,每个topic被切分为一个或多个partition,一个partition有多个replicas,每个replica逻辑上相当于一个超大文件,物理上由无数个固定大小相同的段文件组成,每个段文件包一个数据文件和索引文件,Kafka索引文件设计比较精巧和简单,因为只有2个字段,利用mmap机制可以在内存中快速高效查找,但正由于设计过于简单,而限制了Kafka的相关功能扩展,如今要实现时间粒度消息回溯,则必须在broker端持久化时间戳,即broker收到消息之后为每条消息添加时间戳,以下有3种设计方案
2.3.1方案1
侵入式最小,简单粗暴:
partition的段数据文件中每条消息Key作为保留字段,并没有使用,此处可以利用起来,key设计为复合类型包含timestmap字段,segment log file存储消息格式修改为:
| 长度(bytes) | 字段 | 类型 |
|---|---|---|
| … | … | … |
| 4 | key size: key 长度, -1 代表没有 key | Int32 |
| key size | key: key 的数据; 序列化为Map容易扩展,包含timestamp字段 | Byte[] |
| … | … | … |
查询流程(consumer设计):
consumer从每个partition初始位置开始回放消息,回放消息过程时,解析出Kafka中保留key的内容,并序列化为map,取出timestamp字段与输入timestamp进行比较,小于取出消息的timestamp,则继续不断读取下一条消息,直到大于取出消息的timestamp为止,停止消息回放,设置上一条消息为目标offset,最后根据目标offset为起点进行正常消费。
此设计方案
优点:
- 实现较为简单,对Kafka侵入式小
- 只需要修改broker源码增加时间戳字段
- 通过timestamp查找offset的逻辑在Consumer端进行
- Consuemr在应用层级开发就可以了
缺点:
- broker网络开销大,如没有流控或限流机制,可能短时间内网卡打满
- broker磁盘IO开销大,可能在线生产和消费服务有影响
2.3.2 方案2
性能优先:
segment log file存储格式同方案1,segment index file索引文件增加一个字段,存储格式如下:
| 长度(bytes) | 字段 | 类型 |
|---|---|---|
| 4 | relative_offset: offset - baseOffset, baseOffset为文件名的数,主要是降低内存占用考虑 | Integer |
| 4 | Position: 对应的消息文件中消息的位置 | Integer |
| 8 | Timestamp: 时间戳 | Long |
此设计方案
优点:
- 复用segment index file逻辑和读写策略,包括二分查找等
- 通过timestamp查找offset的逻辑在Broker端进行
- 网络和IO开销极小
缺点:
- segment index file占用大小是原理一倍左右的空间
- segment index file采用mmap的方式映射到内存且访问频繁,大部分数据加载到内存,而时间粒度消息回溯功能使用频率低,如此设计有些浪费空间。
2.3.3 方案3
性能和内存占用最优:
segment log file存储格式同方案1,timestamp采用独立的索引文件进行存储, 读写策略同index相同,文件名称为baseOffset-baseTimestmap.timestamp_index, 存储格式如下:
| 长度(bytes) | 字段 | 类型 |
|---|---|---|
| 4 | relativeTimestamp相对值= timestamp - baseTimestmap,起始的baseTimestmap存储在文件名中,降低内存消耗 | Integer |
| 4 | relativeOffset: offset - baseOffset, baseOffset即为xxx.log和xxx.index文件名的数字 | Integer |
此设计方案
优点:
- 复用segment index file逻辑和读写策略,包括二分查找等
- 通过timestamp查找offset的逻辑在Broker端进行
- 网络和IO开销极小
- 使用时才有内存开销
缺点:
- 开发相对比较复杂,实现周期长,需要维护好xxx.timestamp_index生命周期以及与xxx.index衔接和匹配
- 在极端情况下,xxx.timestamp_index数据并没有全部加载到内存,比原生多一次磁盘IO
- 适配Consumer功能,Broker端需求新开发timestampRequest请求接口(timestampRequest和timestampReponse)
xxx.timestamp_index写入策略设计:
策略与xxx.index一样,不会每条消息写一条索引记录,而是采取稀疏索引的方式:
- 消息 size 维度稀疏: 类似于xxx.index 根据消息的 bytesSize 维度来决定。 xxx.index文件是在消息超过一定的大小之后便写入一个 index,这样做的原因是在查找并未在xxx.index中的offset 的时候,后续顺序遍历 xxx.log文件的时间比较可控。
- 时间 维度稀疏:根据要求的精度,比如 2s, 那么我们每隔 2s 左右的时间记录一下xxx.timestamp_index 即可。
查询流程:
- 根据给定的时间戳timestamp定位响应的 xxx.timestamp_index 文件
- 在 xxx.timestamp_index 内进行二分查找,找到第一个小于等于 timestamp 的 (timestamp、offset) 对。
- 根据 offset查找对应的position
- 从position开始遍历xxx.log文件找到第一个大于等于 timestamp 的消息,返回该消息的时间戳即可
3. 综述-方案选择
方案1:实现简单,但扩展性查,对Broker端性能影响较大
方案2:对内存资源消耗增加一倍,无论是否使用此功能都有开销
方案3:查找offset与timestamp逻辑分离,使用才有极小开销,功能扩展性好,后续可以实现基于timestamp的消息查询功能
综上所述,推荐选择方案3(美团此方案在线稳定运行了10+月)















 5110
5110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









