






数据准备非常重要:
1.从不同的渠道收集数据;
2.清理数据中意外错误或被认为是极端值的取值;
3.生成衍生的变量(feature)。
在数据处理过程,需要进行的操作:
当名义变量的取值大于12个,考虑降低基数:
1>将相同含义的变量合并;
2>出现频率下的类别被合并为一个新的类别,并给予一个合理的标识,如other。
3>合并变量的类别使得某些预测力指标最大化。
下面是采用决策树的方法,对于有12个类别的某个feature,首先把所有的看成一个分组,然后找出最优的二元分割方法,具体见《信用风险评分卡研究》的P92。
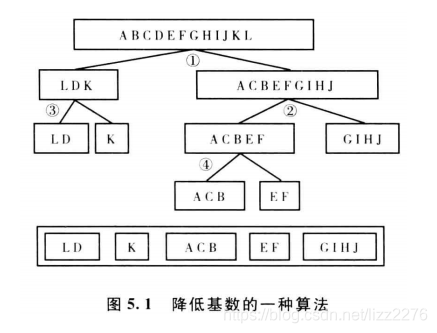
还有其他的一些降低基数的指标。

连续变量的分段:
连续变量必须分段,为了方便构建打分卡,两种方法:等距分段和最优分段。
等距分段是指分段的区间是一样的,比如客户年龄以10岁为间隔分段。
最优分段是使得该变量的预测能力指标得到优化,相当于名义变量降低基数的最优分群。
如下是采用决策树的方法,先规定最小分段的规模,然后进行初始的等距分段(取值顺序保持原始变量的顺序),然后利用决策树二分法,进行分组,知道组数达到设定的分组数量。
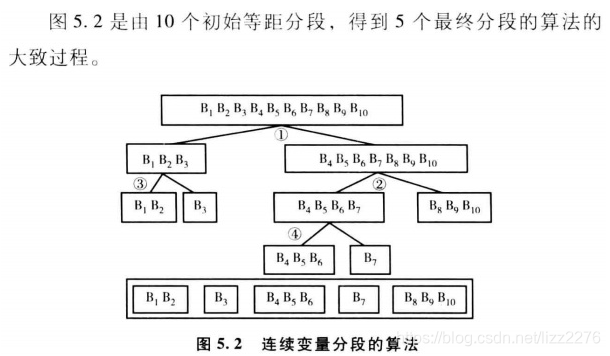
抽样和权重计算
数据库的数据量大,采取抽的方法获取数据,用户信用评分卡的开发。
有3中常见的抽样方法:
1>随机抽样;
2>均衡(对称)抽样;
3>分层抽样。
1.随机抽样
从总体中随机抽取两个不相交的样本集,一个用户训练,一个用户验证。
2.均衡抽样
从总体中抽样的两个样本集,每个样本集中的违约比率与初始总体不同。
————————————————
版权声明:本文为CSDN博主「心雨心辰」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xidianliutingting/article/details/53260363

















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









