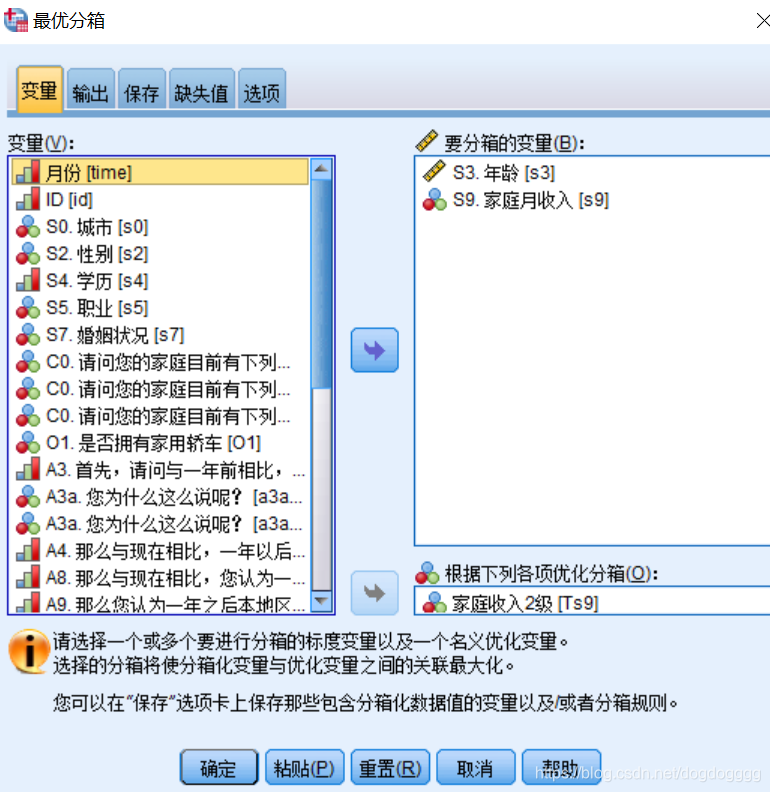
连续变量数值的最优分段 文章目录 连续变量数值的最优分段 前言 1. 最优分箱(出现了问题) 前言 最优分箱: 可视分箱,操作简单,适合如04节所说的简单分箱方法,比如:等距、等量、标准差。 可视分箱没有考虑建模时怎样最优化,因此在SPSS中推出了最优分箱。 对前述(04节)的可视化分段的进一步自动化; 用于 建模分析前,对连续变量的最优分段方式进行探索(变量如何切,能使得建模效果达到最好); 根据某些作为“关键指示变量”的分类变量(因变量),将原有的一个或多个连续变量按照==该分类变量 类间差异最大化(对因变量进行预测,使预测效果最佳)==的优化原则离散化为分类变量。 模型熵:熵越小越准确 决定系数越大越好。 1. 最优分箱(出现了问题)








 本文介绍了SPSS中的最优分箱方法,用于连续变量的建模分析前的最优分段,旨在通过分类变量最大化因变量预测效果。讨论了模型熵和决定系数的概念,并指出在实际操作中遇到的问题。
本文介绍了SPSS中的最优分箱方法,用于连续变量的建模分析前的最优分段,旨在通过分类变量最大化因变量预测效果。讨论了模型熵和决定系数的概念,并指出在实际操作中遇到的问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 7782
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
7782
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






