def forward(self, feat_fv, feat_fi, feat_v, feat_i):
batchSize = feat_fv.shape[0]
dim = feat_fv.shape[1]
T = 0.07
feat_fv = F.normalize(feat_fv, dim=1)
feat_fi = F.normalize(feat_fi, dim=1)
feat_v = F.normalize(feat_v, dim=1)
feat_i = F.normalize(feat_i, dim=1)
l_pos_v = torch.bmm(feat_fv.view(batchSize, 1, -1), feat_v.view(batchSize, -1, 1))
l_pos_v = l_pos_v.view(batchSize, 1)
l_pos_i = torch.bmm(feat_fi.view(batchSize, 1, -1), feat_i.view(batchSize, -1, 1))
l_pos_i = l_pos_i.view(batchSize, 1)
l_pos = torch.zeros((batchSize, 1)).to(self.device)
l_neg = torch.zeros((batchSize, batchSize-1)).to(self.device)
for b in range(batchSize):
if l_pos_v[b] >= l_pos_i[b]:
# pos logit
l_pos_batch = l_pos_v[b].unsqueeze(0)
l_pos = l_pos.scatter_add_(0, torch.tensor([[b]]).to(self.device), l_pos_batch)
# neg logit
feat_v_without_pos = feat_v[torch.arange(feat_v.size(0)) != b]
index_base = [b for _ in range(batchSize-1)]
index = torch.tensor([index_base]).to(self.device)
l_neg_batch = torch.bmm(feat_fv[b].unsqueeze(0).unsqueeze(0), feat_v_without_pos.view(1, -1, dim).transpose(2, 1))
l_neg_batch = l_neg_batch.view(-1, batchSize-1)
l_neg = l_neg.scatter_add_(0, index, l_neg_batch)
else:
# pos logit
l_pos_batch = l_pos_i[b].unsqueeze(0)
l_pos = l_pos.scatter_add_(0, torch.tensor([[b]]).to(self.device), l_pos_batch)
# neg logit
feat_i_without_pos = feat_i[torch.arange(feat_i.size(0)) != b]
index_base = [b for _ in range(batchSize-1)]
index = torch.tensor([index_base]).to(self.device)
l_neg_batch = torch.bmm(feat_fi[b].unsqueeze(0).unsqueeze(0), feat_i_without_pos.view(1, -1, dim).transpose(2, 1))
l_neg_batch = l_neg_batch.view(-1, batchSize-1)
l_neg = l_neg.scatter_add_(0, index, l_neg_batch)
out = torch.cat((l_pos, l_neg), dim=1) / T
loss = self.cross_entropy_loss(out, torch.zeros(out.size(0), dtype=torch.long,
device=feat_fv.device))
return loss
最新发布








 本文介绍了PyTorch中的torch.nn.functional.normalize函数,该函数用于对张量进行L2范数归一化。通过指定的维度(dim)对数据进行处理,确保每一行或每一列的元素除以其对应范数,从而实现单位化。举例说明了dim为0时的操作,解释了其计算过程。参考了官方文档和其他相关资源,有助于深入理解该函数的使用。
本文介绍了PyTorch中的torch.nn.functional.normalize函数,该函数用于对张量进行L2范数归一化。通过指定的维度(dim)对数据进行处理,确保每一行或每一列的元素除以其对应范数,从而实现单位化。举例说明了dim为0时的操作,解释了其计算过程。参考了官方文档和其他相关资源,有助于深入理解该函数的使用。


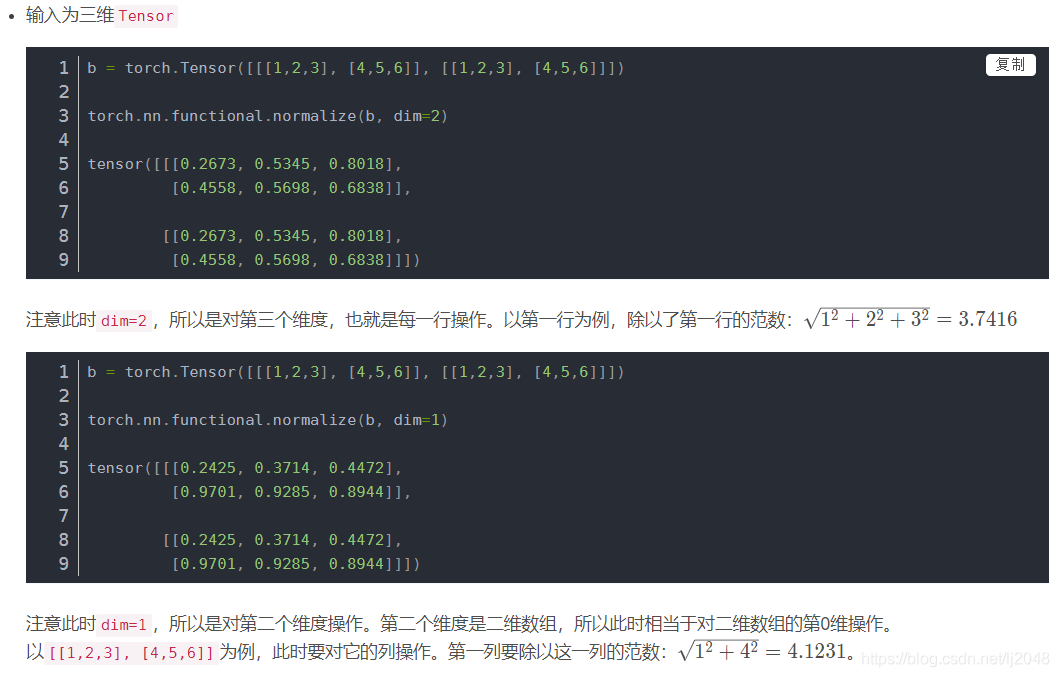
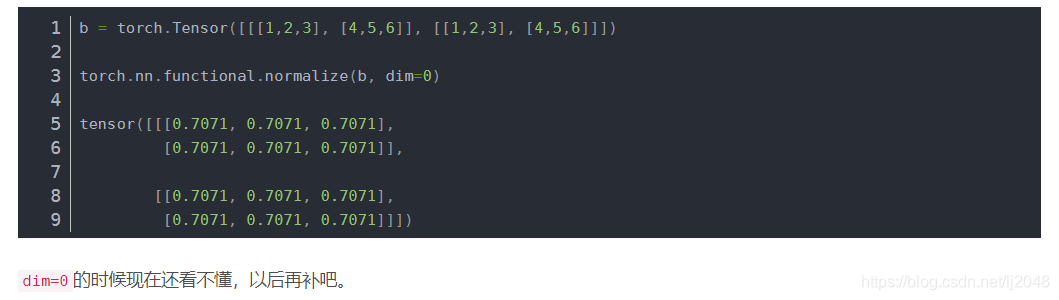 最后dim=0,是1/根号下1平方+1平方,2/根号下2平方+2平方,3/根号下3平方+3平方,所以都是0.7071
最后dim=0,是1/根号下1平方+1平方,2/根号下2平方+2平方,3/根号下3平方+3平方,所以都是0.7071

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











