









摘要
人类能够天生识别出未知的目标。这里主要的任务是:
- 识别出没有监督信息的位置目标,作为“unknown"类别
- 在不忘记之前的已经学习到的类别的基础上增量式学习未知类别
要识别出unknown,大概率使用了无监督的方法,具体怎么做的不清楚
增量式学习,如果我自己做,可能使用蒸馏+新数据进行训练。使用噪音输入保持现有的模型学习到的东西,不丢失。在实际工作中,一般是有数据的,这样还不如全部一起参与训练。
这个和“显著性检测”有什么区别?
引言
过去的深度学习对强监督的学习方式,这里放松下条件:
- 测试图片里出现未知的目标,其类别应该未”unknown"
- 当这些类别已知后,模型应该能够增量学习这个新类
发展心理学研究发现,识别未知事物的原因,关键在于好奇心。这种好奇心能够激发人学习新事物的欲望。这激励我们研究一个新问题,即模型能够识别未知对象成“unknown"。若训练数据明确含义后,能够识别他们。
这个想说明什么,凑字数吗?
识别未知目标未”unknown"是需要很强的泛化能力的。Scheirer和Bendale研究过分类的open set问题,但检测还没有人做
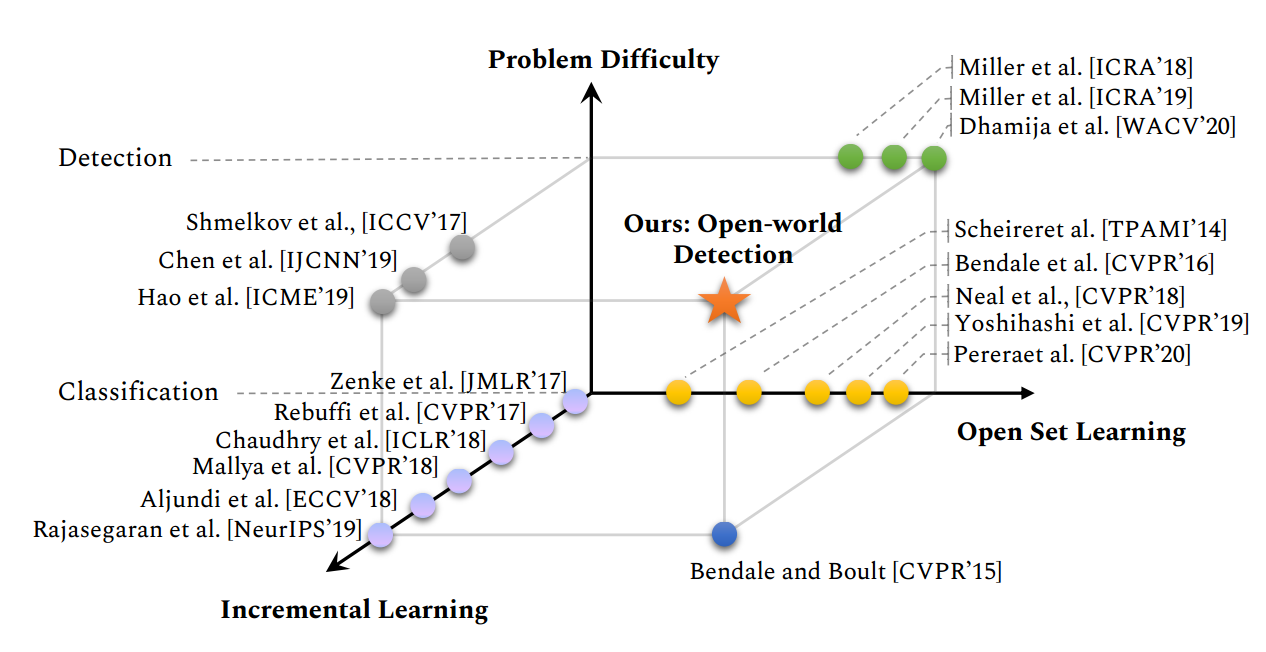
这里提供了些参考文献
Open Set和Open World的分类不能简单于它们的检测,这是因为检测会涉及背景。很多未知的目标是作为已知的目标引入到检测中的。但这些未标注的目标,会显示的作为背景进行学习。Dhamijaf发现,即使有额外的标注,最好的检测器也会有较高的假阳检测,即未知的目标会被分成已知的目标。Miller等人提出使用dropout采样来得到目标检测的不确定度。这个是Open Set目标检测唯一的同行评审工作。我们将Open World 检测更进一步学习新的类别,一旦检测识别成unknown,就会在所有未知感兴趣的样本提供label。
这里没看懂,看了后面再补充前面的
这个世界是多样性的,动态的,Open World检测是个很常见的问题,但我们不可能得到所有目标的类别。在机器人,自动驾驶,植物科目,医疗,监视领域的实践表明,在训练时,不能完全了解预测推断遇到所有类型。最好的解决方式是,推断时,把未知的目标有效识别成unknown,已知的目标识别出来。当对未知的类别,有更多的信息时,把它们加入到已存在的知识体系里。下面时我们工作的贡献:
- 我们引入了新的问题,即更加接近真实世界的Open Set 检测问题
- 我们通过对比聚类未知事物的能量来解决这个问题
- 我们建立了一个benchmark,来全面评价各种方法
- 我们同时带来一个副产品,在增量目标检测中达到最好的精度
Related Work
Open Set Classification:Open Set分类问题时,测试预测时,会遇到未知的类别。Scheirer是得到样本与训练数据的距离来判断。后续的工作是使用多分类器,使得未知的分类置信度降低。
Bendale and Boult是在深度网络中使用Weibull分布去估算风险(即OpenMax分类器)。Liu等人利用长尾理论,进行度量学习。相似的基础,有一些方法是检测出不在样本分布。最近自监督方法在探索Open Set的识别问题。然而,他们能识别出未知的物体,但不能在多个数据集上,进行动态增量式更新。我们的方法是以前没有人探索的。
Open World Classification:不同于静态分类,它们能够让已知和未知并存。当未知类提供新的label时,模型能够自适应的改进。他们的方法通过重新校正类别概率来平衡风险。通过模板匹配,区分低匹配的未知类别。然而他们没有benchmark。
Open Set Detection:Dhamija等人发现最好的检测器将未知的类会分成置信度高的已知类。有一个工作是聚焦在不确定度来拒绝未知类,这种方法不能增量学习
Open World Object Detection
考虑一个目标检测器Mc,能够检测所有的C类,同时也能够认识出未知类别。若增加n个新类,不用在整个数据集上重新训练
ORE: Open World Object Detector
开放场景的目标检测,是不需要对未知类别提供监督信息,也不会忘记之前的学习的知识。我们提供ORE方法解决它。
这里的关键部分是隐空间上的对比聚类。为了使用对比聚类来优化未知类别,我们需要它们的实例的监督信息。很明显是不可能获得无穷多的未知标注,即使是一部分也是不可能的。为了解决这个问题,我们使用在RPN上,对未知类别上做自动标注。通过在隐空间上分离自动标注的未知实例,来帮助区别已知和未知类别。
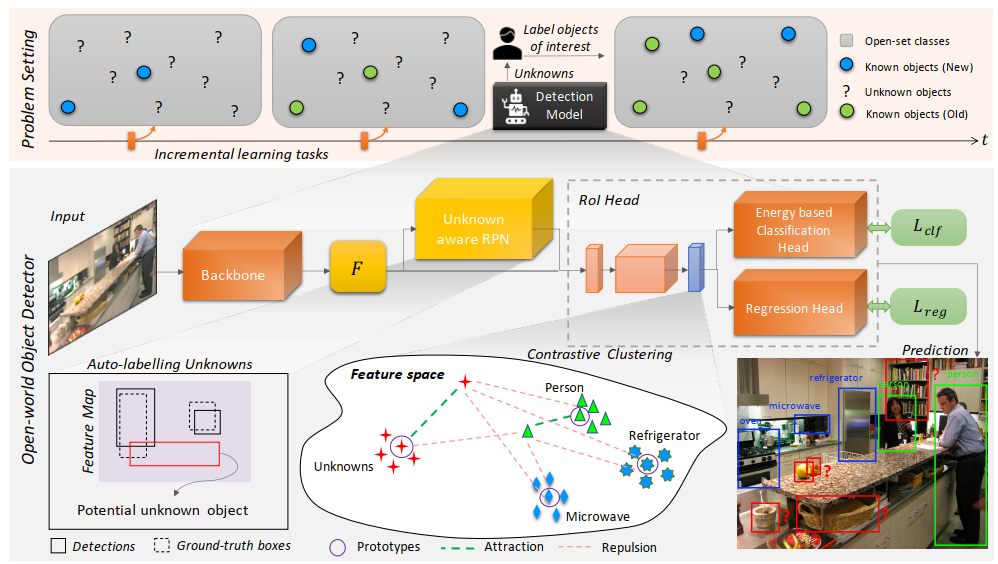
在RoI上的特征进行对比聚类,在RPN上做自适应做自动标注,class head上识别出未知类别。下面分别介绍各部分:
Contrastive Clustering
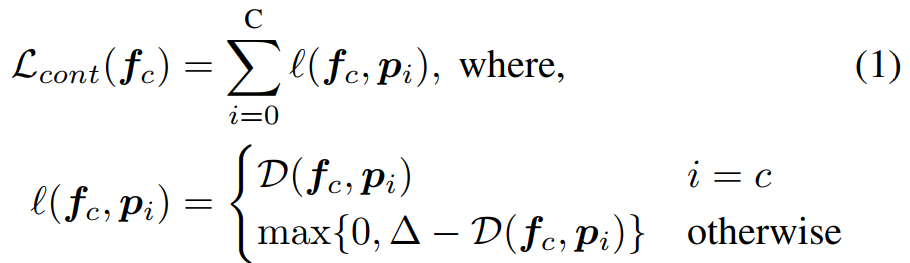
上式中,是原型向量,和
是中间层的特征向量,i,c为某一类序号。D是距离函数,
表示相似度。每一类的特征向量的平均向量作为原型向量。这个原型向量是ORE的重要部分。整个训练过程是端到端的,这个原型向量也在不断更新的。我们使用一个固定长度的队列,来存储不同类别的向量,使之能够在整个训练过程中跟踪这些特征向量。
下面实际是聚类的过程,不断的更新每个类别的中心点,如果出现新的类别,就就第一次出现时,增加一个新的中心点。

这个聚类loss,有点像center loss。
Auto-labelling Unknowns with RPN
在RPN中如何自动化标注呢?RPN中能够产生前背景的候选bbox,我们选择与groundtruth没有重叠的,且分类置信度高的标注为unkmown。简单的说,我们选择背景中分类最高的k个候选框,作为unknown。
在RPN中标注出来了unknown,在分类器直接增加一个类别进行训练,可行吗?这里没看懂。从后面的能量部分,好像说的是把unknown作为一个类别在训练,那聚类loss起多大的作用呢?
Energy Based Unknown Identifier
这里其实和softmax差不多,增加了一个温度,这个与蒸馏中的温度是一个意思。
没怎么看懂,这个能量是干什么的,看起来和softmax差不多。
Alleviating Forgetting
作者的方法,参考的是《Frustratingly simple few-shot object detection》,以后补充。
实验
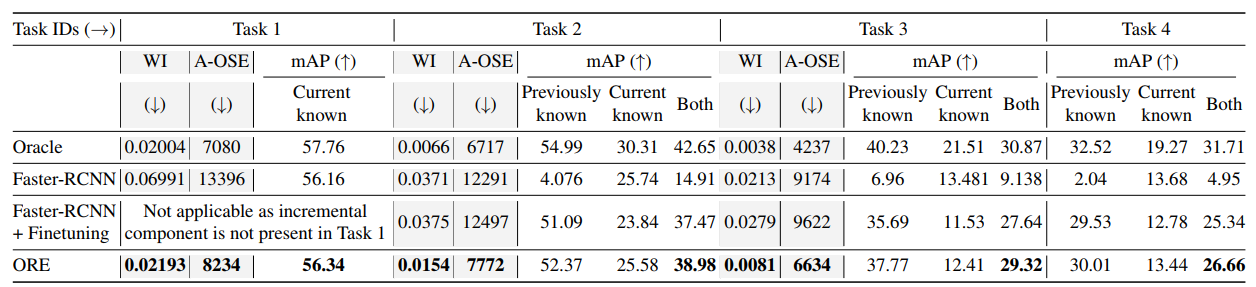
从这里看到,ORE都比原始的Faster-RCNN要强,原始的Faster-RCNN在增量训练上,效果很差。
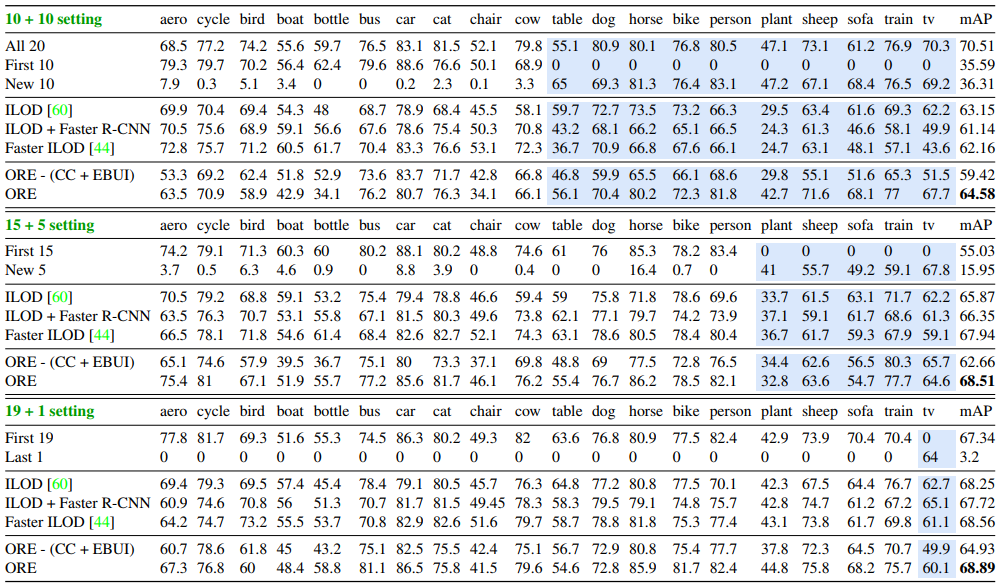
从上表来看,ORE-(CC+EBUI)指的是没有CC和EBUI下,结果并不好,说明CC和EBUI起作用了。但文章中说好像不是这个意思

















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









