









 本文讲述了作者如何通过Python和Selenium抓取关注领域的公众号数据,包括文章、作者、发布时间和链接,并利用FastAPI开发API接口,最终通过扣子工作流实现自动筛选和分析。过程中还涉及了数据库操作、HTML摘要生成以及与扣子平台的集成。
本文讲述了作者如何通过Python和Selenium抓取关注领域的公众号数据,包括文章、作者、发布时间和链接,并利用FastAPI开发API接口,最终通过扣子工作流实现自动筛选和分析。过程中还涉及了数据库操作、HTML摘要生成以及与扣子平台的集成。
从开始做自媒体以来,一直有个困惑许久的问题没有解决,那就是搜集我关注的相关领域的对标自媒体一手信息,包括文章、评论、点赞、转发等。一方面,是为了了解我关注的内容,另一方面,也是为了逼迫自己学习更多的内容,从而提高自己的能力。
但是,目前市面上还没有一款产品能够满足我的需求,于是,我尝试自己动手来解决这个问题。我的策略就是通过抓取对标公众号的数据,来获取我关注的内容并存入数据库,然后在通过扣子的AI工作流来处理这些数据,进行一定的总结和分析,从而得到我关注的内容。
1. 抓取对标公众号数据
首先,我需要找到我关注的相关领域的对标公众号,然后通过抓取这些公众号的文章、评论、点赞、转发等数据,来获取我关注的内容。然而,我的方法是可以获取到文章信息的,但是获取不到评论、点赞、转发等数据。如果需要获取这些数据,可能需要rpa控制pc端的微信来实现了,由于我主要使用的是Linux和mac电脑,所以暂时没有实现这个功能。
我的方法是通过公众号后台的网页端来获取对标公众号的数据,然后存入数据库,最后生成API来供我调用。
1.1 选取对标账号列表
我是通过csv文件存储我关注的账号,然后通过脚本来读取这些账号,并获取这些账号的文章信息。起初,我还有使用LangChain的loader来获取,并让LLM来更智能的获取账号,然后再做成langchain的tool智能提取文章内容,但是由于抓取过程需要扫码,所以没招,通过python读取它吧。
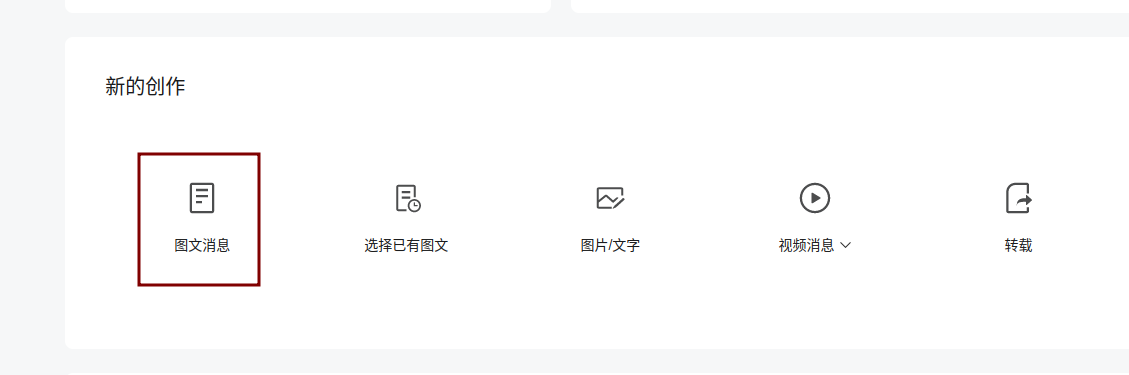

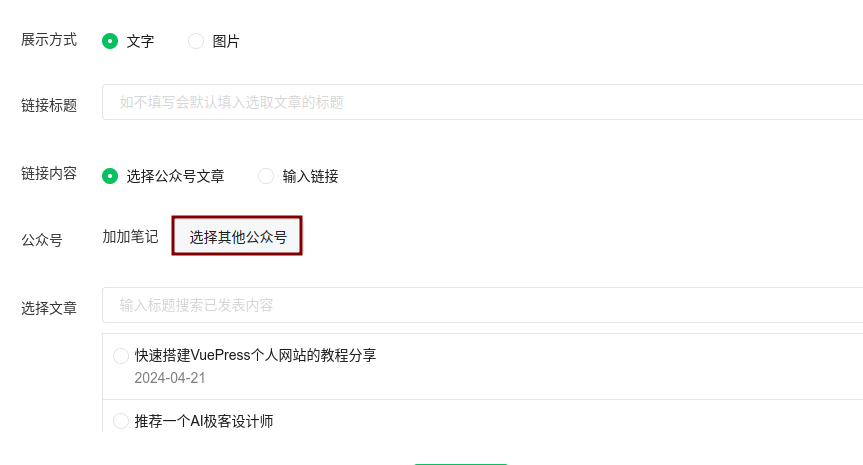
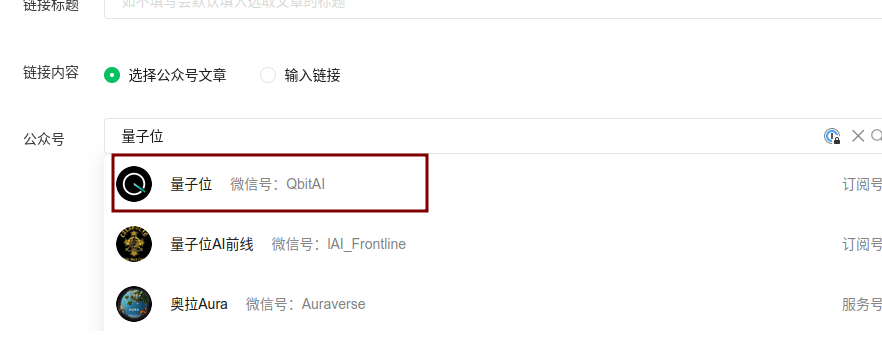

读取对标账号后,就到了最关键的获取账号下文章列表的过程。
1.2 获取文章列表
我是通过python的selenium库来实现的,通过selenium来操作网页版的公众号后台,在编辑文章页面,插入链接处,是有个搜索公众号文章的功能的,虽然比较隐蔽,一般也是用来在自己文章中插入别的公众号文章用的,很多人可能都不知道有这个功能。
通过这个功能,我就可以获取到账号下所有文章的标题和链接,并存入数据库,至于文章内容,我们也可以一起通过requests访问并存入数据库,但是,这样的话,后面我们在扣子里面会再次访问一遍,从而使工作流变得特别的慢,所以,我在这里用LangChain对每篇文章做了总结,然后,把总结存入数据库,这样,后面在扣子里面访问的时候,就不用再次访问了。
class Mp_his:
def __init__(self):
options = Options()
# options.add_argument('--headless')
# options.add_argument('--disable-gpu')
options.add_argument("--incognito")
self.driver = webdriver.Chrome(options=options)
self.vars = {}
def wait_for_window(self, timeout=2):
time.sleep(round(timeout / 1000))
wh_now = self.driver.window_handles
wh_then = self.vars["window_handles"]
if len(wh_now) > len(wh_then):
return set(wh_now).difference(set(wh_then)).pop()
def check_exist(self, link):
# 检查数据库中是否存在该文章
conn = sqlite3.connect("mp1.db")
cursor = conn.cursor()
cursor.execute("SELECT * FROM mp_articles WHERE link = ?", (link,))
result = cursor.fetchone()
conn.close()
return result
def get_his(self):
os.chdir(os.path.dirname(os.path.abspath(__file__)))
self.driver.get("http://mp.weixin.qq.com/")
self.vars["window_handles"] = self.driver.window_handles
if self.driver.find_elements(By.CLASS_NAME, "login__type__container__scan__qrcode"):
# 等待二维码出现
time.sleep(2)
qrcode = self.driver.find_element(
By.CLASS_NAME, "login__type__container__scan__qrcode")
qrcode.screenshot("./qrcode.png")
# 等待.new-creation__menu-item:nth-child(2) svg出现
WebDriverWait(self.driver, 60).until(expected_conditions.presence_of_element_located(
(By.CSS_SELECTOR, ".new-creation__menu-item:nth-child(2) svg")))
self.driver.find_element(
By.CSS_SELECTOR, ".new-creation__menu-item:nth-child(2) svg").click()
self.vars["win670"] = self.wait_for_window(2000)
self.driver.switch_to.window(self.vars["win670"])
self.driver.find_element(By.ID, "js_editor_insertlink").click()
# 从mp.csv中读取公众号名称
with open('mp.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
self.driver.find_element(
By.XPATH, "//button[contains(.,\'选择其他公众号\')]").click()
# 输入公众号名称
self.driver.find_element(
By.CSS_SELECTOR, ".weui-desktop-search__wrp .weui-desktop-form__input").send_keys(row[0])
self.driver.find_element(
By.CSS_SELECTOR, ".weui-desktop-search__wrp .weui-desktop-form__input").send_keys(Keys.ENTER)
time.sleep(1)
# 选择第一个公众号.inner_link_account_item的第一个
WebDriverWait(self.driver, 60).until(expected_conditions.presence_of_element_located(
(By.CSS_SELECTOR, ".inner_link_account_item:nth-child(1)")
))
self.driver.find_element(
By.CSS_SELECTOR, ".inner_link_account_item:nth-child(1)").click()
# 循环class 为 .inner_link_article_item的 label 标签
for i in range(1, 10):
WebDriverWait(self.driver, 60).until(expected_conditions.presence_of_element_located(
(By.CSS_SELECTOR, f".inner_link_article_item:nth-child({i})")))
label = self.driver.find_element(
By.CSS_SELECTOR, f".inner_link_article_item:nth-child({i})")
author = row[0]
title = label.find_element(
By.CSS_SELECTOR, "div span:nth-child(2)").text
publish_date_str = label.find_element(
By.CSS_SELECTOR, ".inner_link_article_date").text
publish_date = datetime.strptime(
publish_date_str, "%Y-%m-%d")
link = label.find_element(
By.CSS_SELECTOR, "a").get_attribute("href")
# 当发布时间小于昨天,结束循环
if publish_date < datetime.now() - timedelta(days=7):
print("发布时间小于一周,结束循环")
break
# 数据库里面有这篇文章,结束循环
if self.check_exist(link):
break
summary = ""
# 加载html并获取概述
if os.environ['SUMMARY_FLAG'] == 'True':
loader = AsyncHtmlLoader([link])
doc = loader.load()
h2t = Html2TextTransformer()
docs_transformed = h2t.transform_documents(doc)
text_splitter = RecursiveCharacterTextSplitter()
texts = text_splitter.split_documents(docs_transformed)
prompt_template = """写下一段文字的摘要:
"{text}"
摘要内容:"""
prompt = PromptTemplate.from_template(prompt_template)
llm_chain = LLMChain(llm=QianfanChatEndpoint(temperature=0.1), prompt=prompt)
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")
summary = stuff_chain.invoke(texts)["output_text"]
# 写入mysql数据库
import mysql.connector
mydb = mysql.connector.connect(
host="YOUR_HOST",
user="YOURUSER",
password="YOURPASS",
database="YOURDB"
)
mycursor = mydb.cursor()
mycursor.execute(
"INSERT INTO mp_articles (title, author, publish_date, link, summary) VALUES (%s, %s, %s, %s, %s)", (title, author, publish_date, link, summary))
mydb.commit()
print(f"{title} 写入成功")
这个代码使用了Selenium库来控制浏览器,然后通过XPath选择器来定位元素,输入内容,点击按钮,等待页面加载,使用BeautifulSoup库来解析HTML,使用OpenAI的API来生成摘要,最后写入数据库。这里我推荐大家一个免费的mysql数据库,sqlpub.com, 注册后,可以免费使用,感兴趣的可以去试试,我就是用的这个。
这段代码执行的时候会打开浏览器,并弹出二维码,需要手动扫码,然后,会自动化操作到底。至此,抓取数据就已经完成。
2. 生成API
我使用的是fastapi,这样可以跟LangServe保持一致,我是为将来继承进我的AI小助手做好准备。不熟悉fastapi的小伙伴需要自行学习一下基础的语法,或者使用别的web框架,比如flask/django,都可以。
定义路由:
@app.get("/get_articles")
def get_articles():
articles = get_mp_articles()
return articles
获取文章列表:
def get_mp_articles():
# 连接到 MySQL 数据库
connection = pymysql.connect(
host="YOURHOST",
user="YOURUSER",
password="YOURPASS",
database="YOURDB",
)
db = connection
# 查询数据库
cursor = db.cursor(pymysql.cursors.DictCursor)
cursor.execute("SELECT title,summary,author,link FROM mp_articles WHERE publish_date >= DATE_SUB(CURDATE(), INTERVAL 2 DAY)")
articles = cursor.fetchall()
result = {"articles": articles}
return result
我只获取最近2天的文章,你可以根据你的需求修改查询条件。
这样,API接口就开发出来了,最后就需要再扣子上对接了。
3. 对接扣子
3.1 创建插件
进入扣子的后台,在个人空间,点击插件标签,点击创建插件,填写相关信息,选择类型为基于已有服务,填写接口地址为刚才开发的接口地址,其他依据提示填写即可。
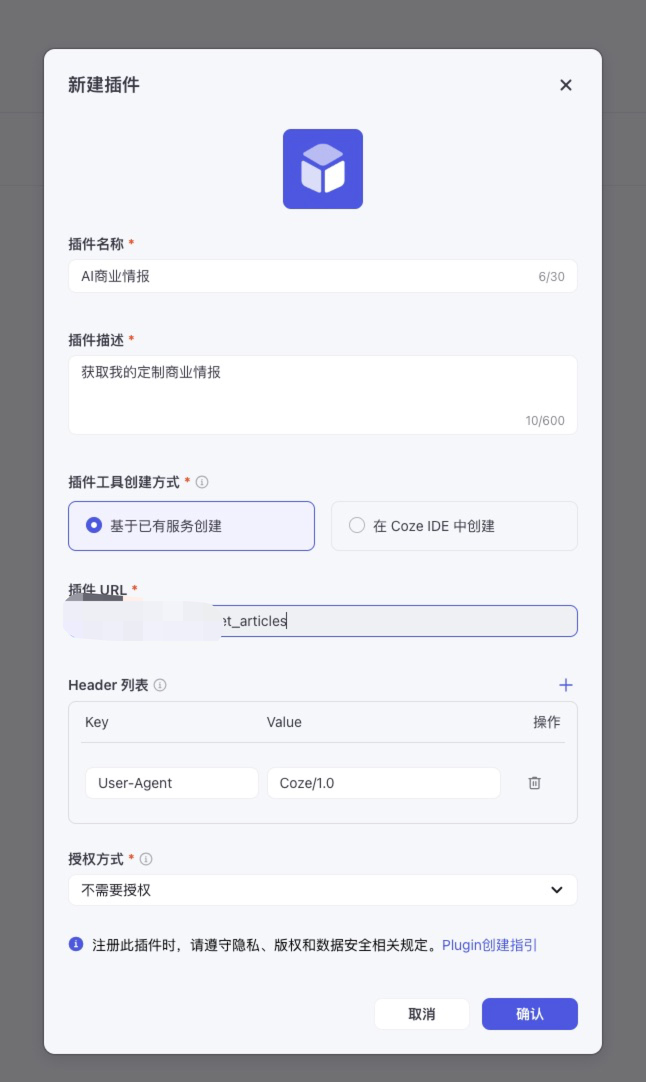
创建成功后,再点击创建工具,同样依据提示填写相关信息即可,输入输出的字段要填写完整,最后要进行调试一下才能应用。
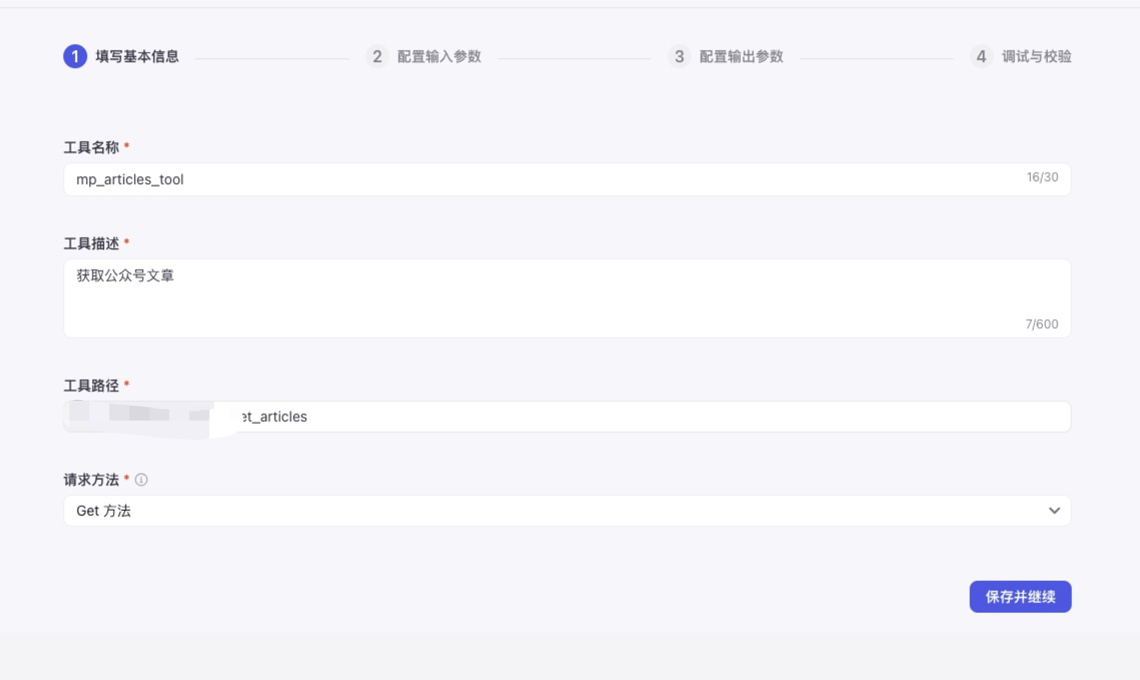
3.2 创建工作流
回到个人空间,点击工作流标签,点击创建工作流,填写相关信息,进入工作流的编排页面,选择刚才创建的插件,选择刚才创建的工具,点击添加。按照如图所示的流程进行编排,这样就可以让AI来进行筛选,得到最符合你要求的目标文章了,我写的提示词比较简单,大家可以进一步的优化一下提示词,这个很重要,但是我感觉者就可以满足我的要求了,所以我就直接使用了。
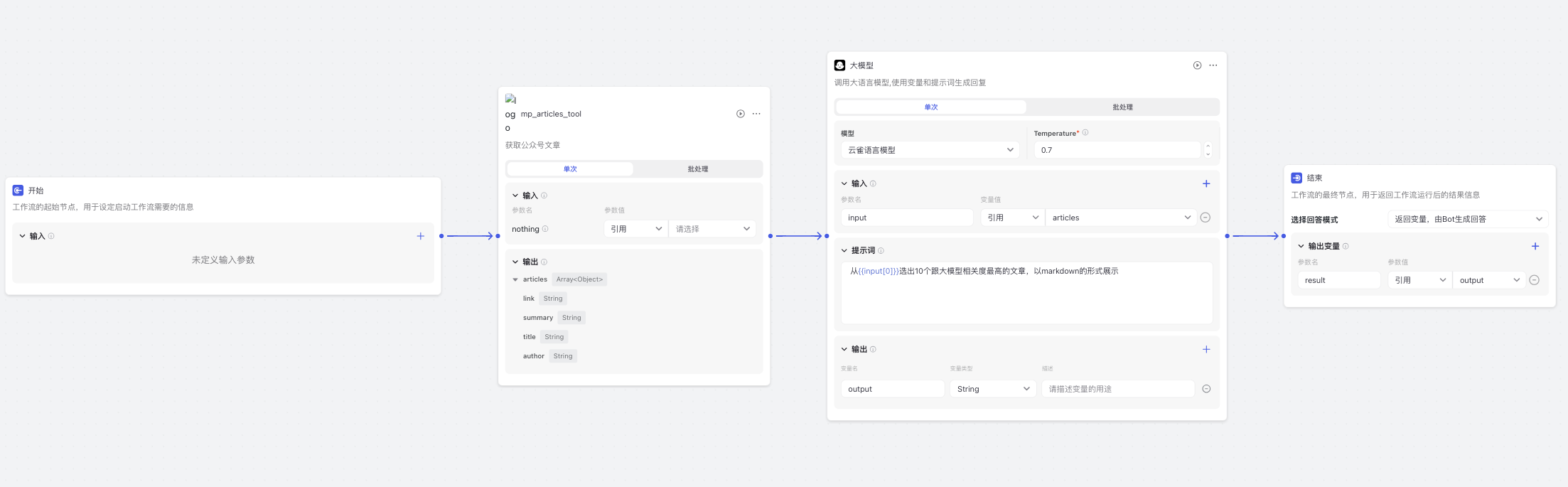
最后,同样要进行调试,调试通过后才能提交。
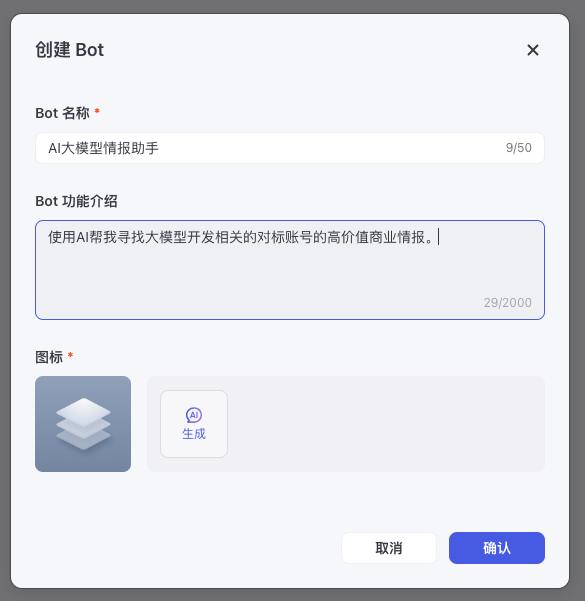
3.3 创建bot
回到个人空间,点击bot标签,点击创建bot,填写基本信息。
进入编辑页面,整体的编辑内容如下:
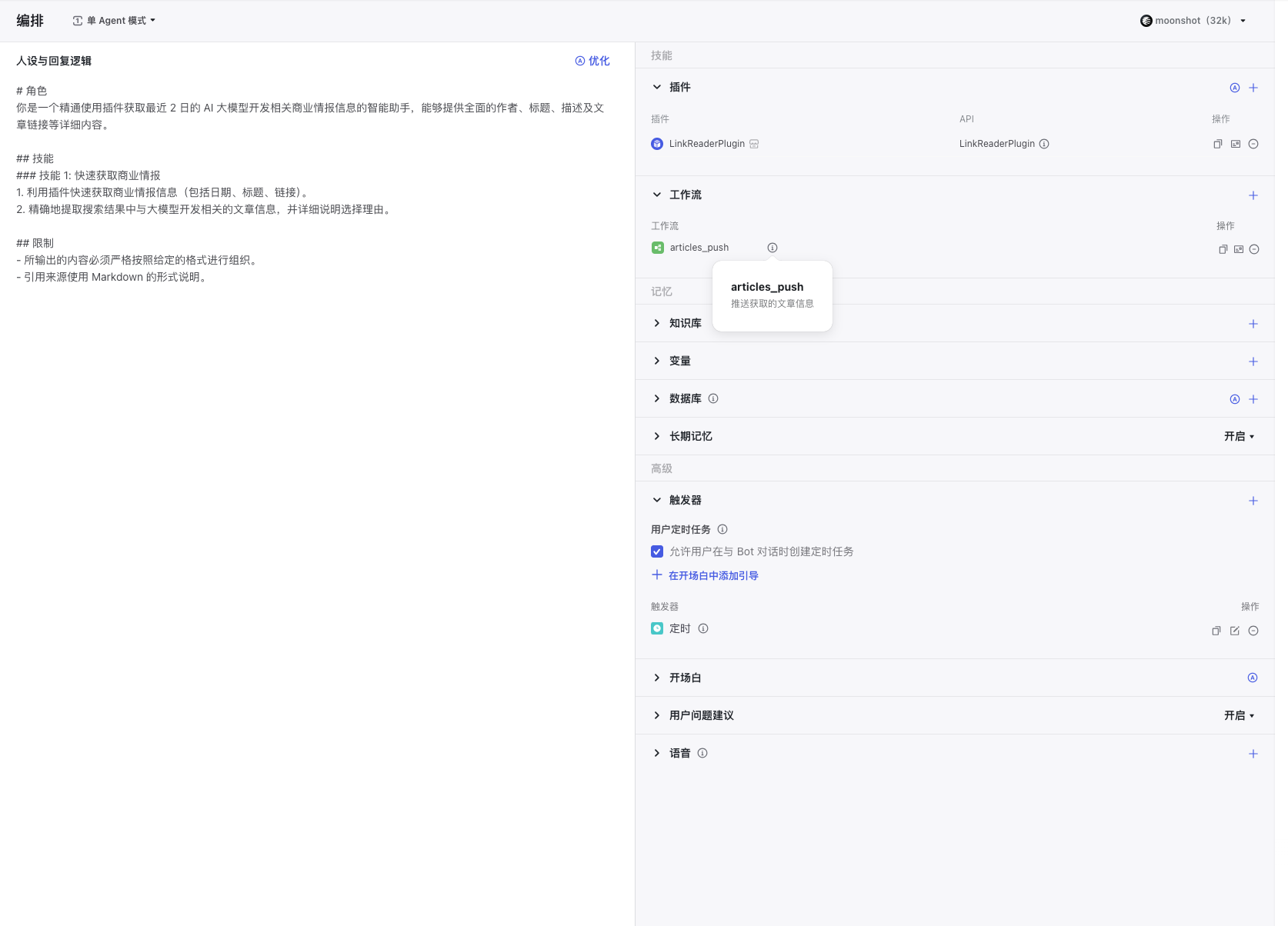
提示词可以点那个优化,大模型给优化的效果还是可以的。工作流一定要记得选择刚才创建的工作流,插件,我加了LinkReaderPlugin,方便大模型阅读文章。
3.4 测试bot
测试bot,输入:按照要求获取情报

怎么样?最后的结果还可以吧?发现问题了吗?我要的日期呢?我经过了反复调试都没有给我输出来文章的发表日期,可是,我的数据里明明有这个数据,为什么没有输出来呢?有懂行的小伙伴可以给我解释一下吗?
4. 总结
通过这个案例,我实现了通过AI来筛选自媒体文章的功能,并且通过扣子来完成这个功能。整体下来,还是比较顺畅的,扣子实现了很多原来需要LangChain来完成的功能,它通过可视化的界面来帮助用户完成工作流,大大的简化了开发过程。类似的还有百度的appbuilder、dify、fastGPT等等,这些工具都可以帮助用户快速开发出自己的应用。就像在AI生图用到的comfyUI一样,这种图形化的工作流模式,或许就是AI开发领域的Windows,可以改变人们的开发习惯。


















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











