







一、环境搭建和代码下载
1.python环境
下载python
我使用的是python3.10版本,其中自带pip,下载链接如下:https://www.python.org/downloads/windows/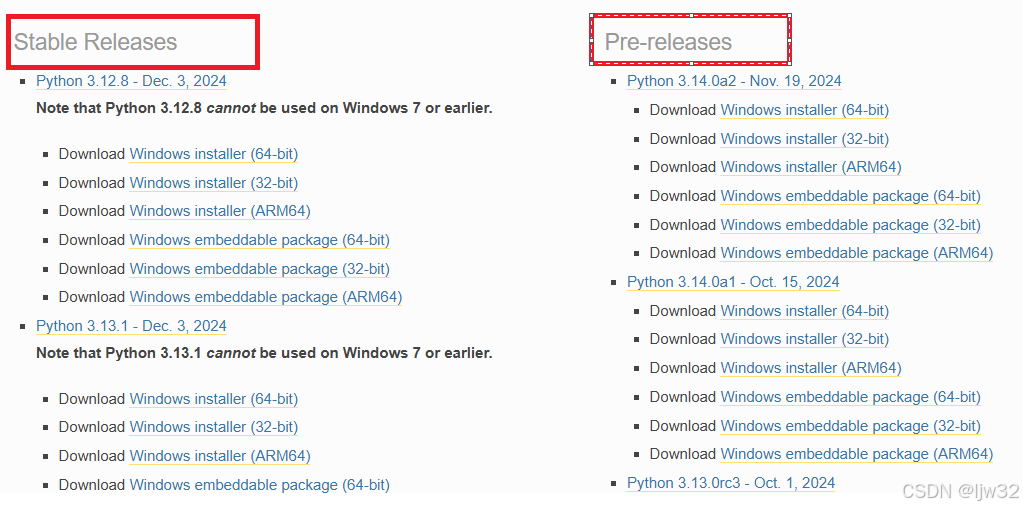
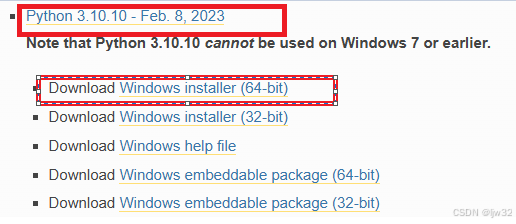
下载Windows installer(64-bit)
Stable Releases:稳定发布版本,指的是已经测试过的版本,相对稳定。
Pre-releases:预发布版本,指的是版本还处于测试阶段,不怎么稳定。
Windows embeddable package:Windows可嵌入程序包,通俗一点就是一个压缩包。
Windows help file:指的是帮助文档,可无视,对于小白帮助不了什么。
安装操作: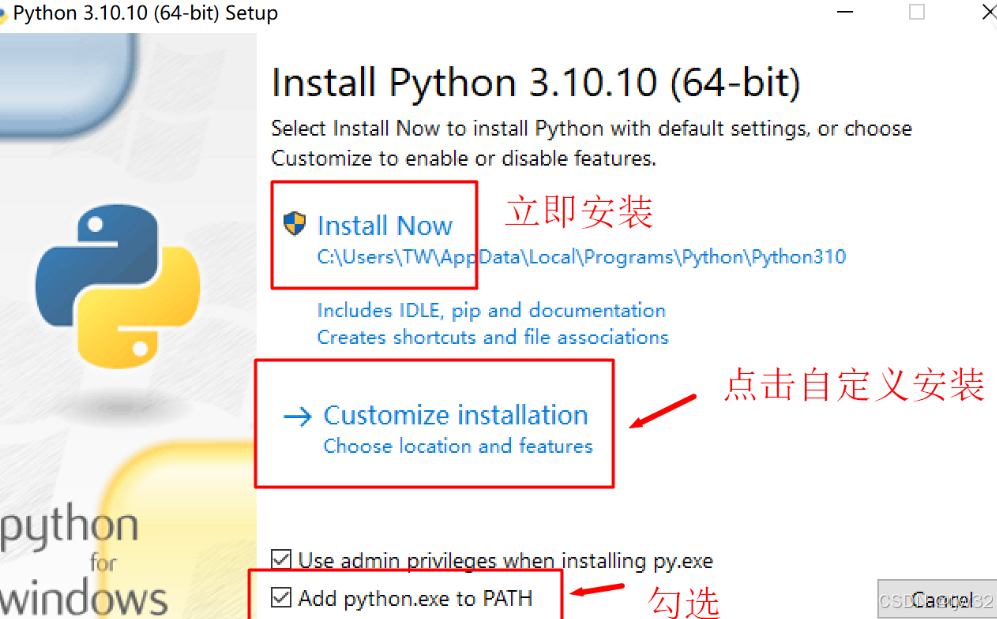
Install Now:立即安装,点了会默认安装python的位置与默认勾选python功能
Customize installation choose location and features:自定义安装选择位置和功能。
Use admin privileges when installing py.exe: 安装py.exe时使用管理员权限,勾选这个是为了程序或者命令运行过程中更改系统设置或则注册表,如果没勾选,那你就只能以普通用户的身份进行读的权限,没有改的权限,也就没法完成更改操作。
Add python.exe to PATH:将python.exe添加到PATH,就是把python的路径添加到PATH环境变量中。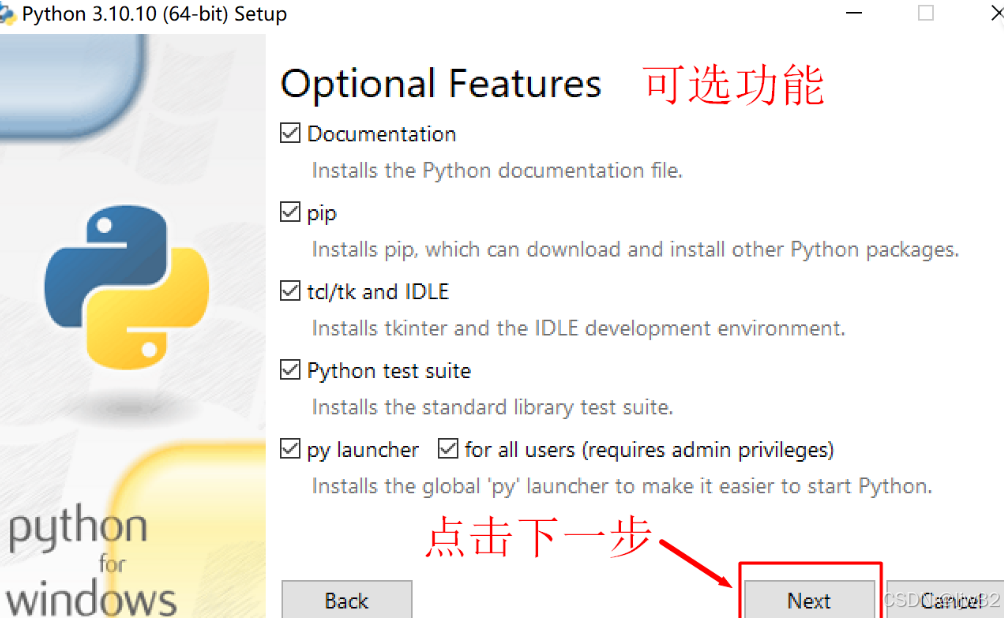
Documentation:安装Python文档文件。
pip:安装pip,这个是一个安装和管理Python包的工具,就是以后你可以通过Win+R输入cmd回车,然后输入pip install+包名下载相应的python模块。
tcl/tk and IDLE:安装tkinter和IDLE开发环境。
Python test suite:安装标准库测试套件。
py launcher: Python启动器。【for all user】所用用户(需要管理员权限)两个一起勾选后会安装全局Python启动器,使启动Python变得更容易。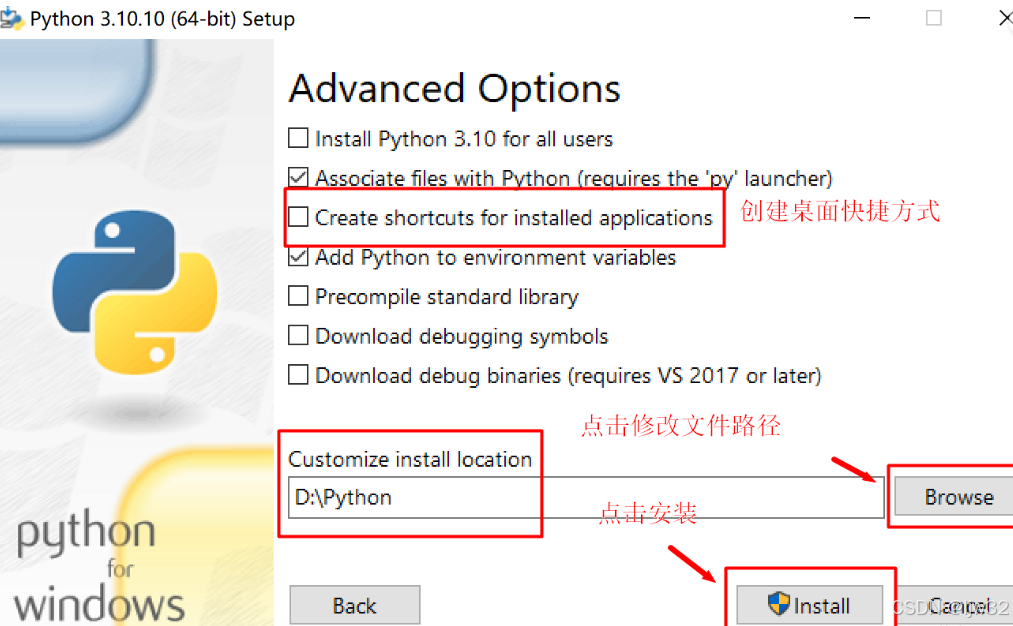
Associate files with Python:将文件与Python关联。
Create shortcuts for installed applications:为已安装的应用程序创建快捷方式。
Add Python to environment variables:将Python添加到环境变量里。
检测python是否安装成功
1、Win+R打开运行窗口输入“cmd”,点击【确定】或者回车键。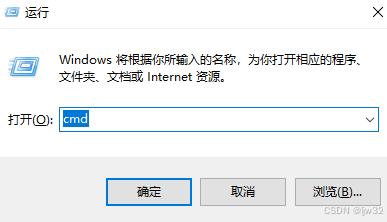
2、输入python -V点击回车键查看Python版本号。(打完python之后要打个空格再打-V,否则会报错出现不是内部命令的情况,还有V必须是大写) 或者也可以输入python --version查看python版本号。
输入pip --version查看pip是否安装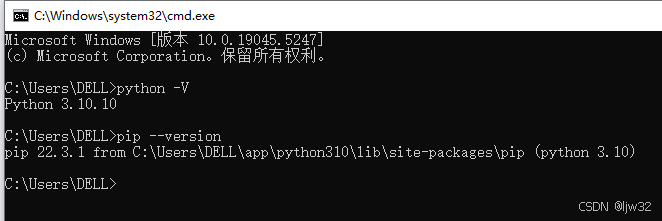
解决报错
如果不显示python版本号,那么可能是在安装python时没有勾选设置其PATH环境变量,如果是pip未显示,则是在python安装时没有选择安装pip,以上错误可以选择重新安装python解决,或者手动设置python的环境变量
手动设置环境变量:找到python的安装目录和pip的位置,pip的位置在python安装目录下的Scripts文件里,直接将python安装路径和pip路径设置到环境变量中即可,重新在命令窗口输入python -V和pip --version就可以看到对应的版本号,到此python安装已经结束!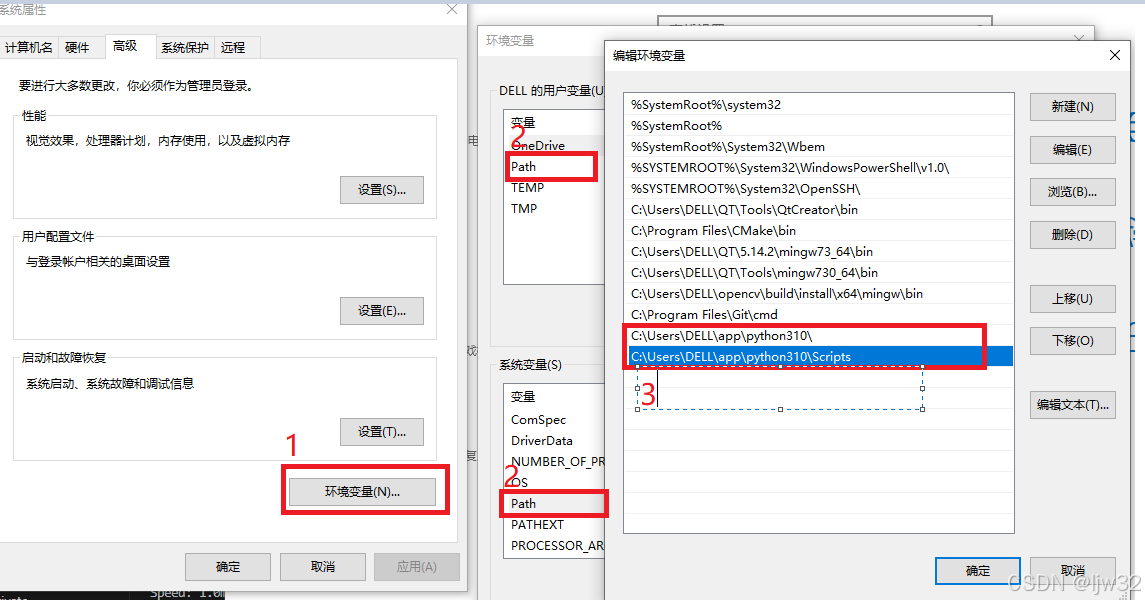
2.vscode下载
下载链接:https://code.visualstudio.com/ 点击下载即可
安装过程没有什么需要注意的
下面是给vscode安装中文插件,安装之后重新打开即可。可以不安装
3.Git下载(可选做)
用于克隆项目代码使用,网上也有Git的下载教程
4.PyToch(可选做)
首先需要确定你的电脑是否有显卡
查看电脑自带的显卡版本,操作步骤如下:
按下Windows键 + R,输入DxDiag并点击确定
在DirectX诊断工具启动后,点击显示标签,显卡的名称与制造商会显示在设备栏位中,而驱动程序的版本则会显示在驱动程序栏位中。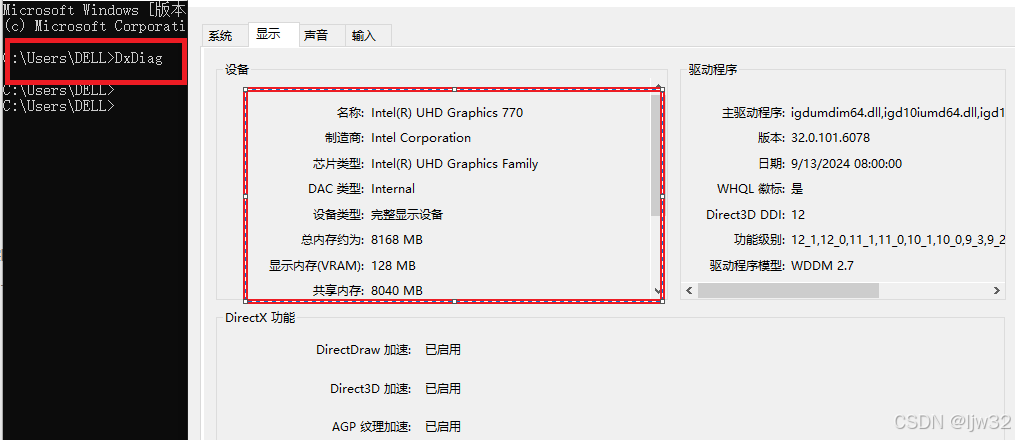
由上图可以看出我是英特尔类型的芯片同时没有显卡,所以我没必要安装pytoch。
对于其他朋友如果你是英伟达的芯片同时有显卡的话,可以先安装显卡驱动(安装NVIDIA驱动),下载链接如下:
https://www.nvidia.cn/geforce/drivers/
安装好后即可查看自己的cuda版本 在此可以看出CUDA的版本,然后根据下面的CUDA下载对应的PyToch版本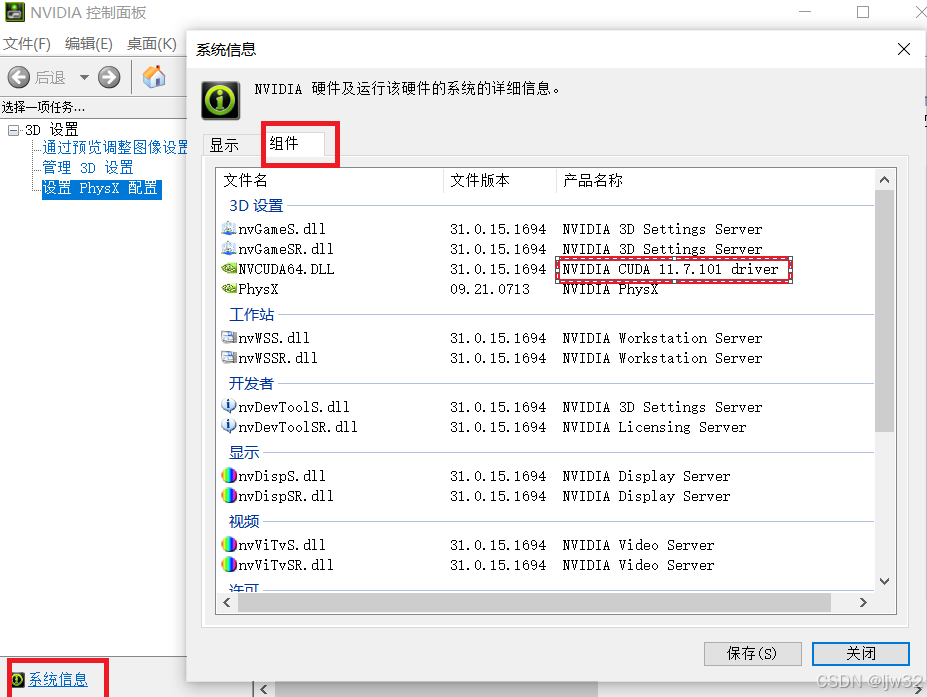
torch对应版本下载安装
https://pytorch.org/get-started/previous-versions/
# 检查CUDA版本
nvidia-smi
nvcc -V
# 检测GPU是否可以被调用
import torch
torch.__version__
# 检查显存占用
nvidia-smi
#显存清空
import torch
torch.cuda.empty_cache()
# 批量卸载依赖
pip uninstall torch torchaudio torchvision -y
# 安装torch
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
# pip的缓存文件夹
pip 配置缓存路径 在windows操作平台,默认情况,pip下使用的系统目录 C:\Users\用名名称\AppData\Local\pip
4.代码下载
创建一个文件夹,我这里创建的是yolo文件夹,一会要在这个文件夹里克隆或者下载YOLOv10的工程文件以及模型文件。
方式1:
在官网上直接下载YOLOv10的项目工程文件,下载链接如下:https://github.com/THU-MIG/yolov10
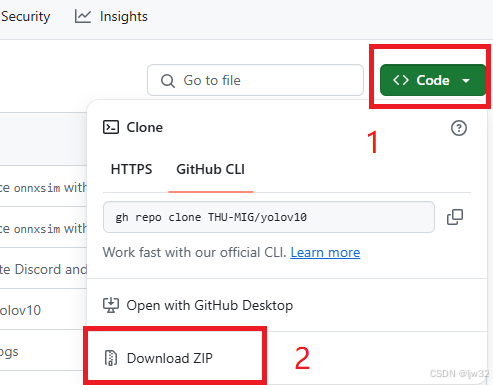
下载后将压缩包解压到自己创建的yolo文件夹里即可
方式2:
使用Git下载,即使用Git指令克隆项目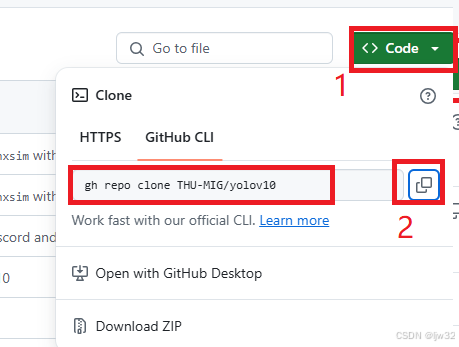
复制克隆代码指令到vscode中的终端输入即可,终端我这里选的是command prompt,也就是cmd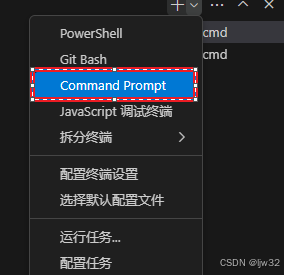
我这里的操作是:在vscode中打开自己创建的yolo文件夹并打开终端进入到yolo目录下,然后输入克隆指令即可
模型文件(Model)下载
模型文件链接:https://github.com/THU-MIG/yolov10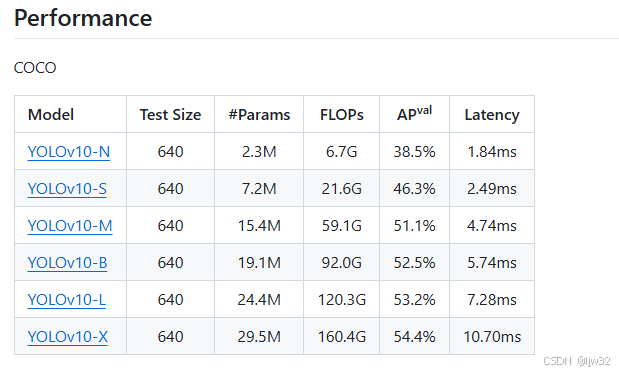
你可以按照自己的需求下载不同的模型文件,将下载的模型文件和克隆的项目工程文件放到同一个目录下即可,我这里下载的是最小的模型文件YOLOv10n.pt,并将模型文件和之前克隆的项目工程文件放到yolo文件下。后期如果无法识别出结果时可以在这里下载其他的模型文件进行尝试
5.虚拟环境
虚拟环境的创建、激活和退出指令取决于你使用的虚拟环境管理工具。以下是venv的虚拟环境管理工具及其相关指令:
venv(Python 3.3+ 内置)
创建虚拟环境:
在vscode中打开终端,并进入到自己创建的yolo目录下,输入如下指令即可
python3 -m myvenv
或者
python -m myvenv
(根据你的系统和Python版本,可能需要使用 python3 或 python)
激活虚拟环境:
-
Windows:
.\myvenv\Scripts\activate
或者
env\Scripts\activate
-
Unix 或 MacOS(使用 bash):
source /path/to/env/bin/activate
退出虚拟环境:
deactivate
6.下载依赖
根据上面的操作,激活虚拟环境并进入到YOLOv10工程文件 输入如下指令即可下载YOLOv10运行所需的依赖:
-
确保你处于虚拟环境中(如果使用虚拟环境)。
-
运行以下命令来安装依赖项:
pip install -r requirements.txt
或者,如果你使用的是 Python 3(取决于你的系统配置):
pip3 install -r requirements.txt
这个命令会读取 requirements.txt 文件中的每一行,并使用 pip 来安装列出的包及其版本。确保 requirements.txt 文件位于当前工作目录中,或者提供正确的文件路径。
注意:如果你没有显卡也就意味着你没有安装PyToch,可以将requirements.txt中的如下内容删除后再执行依赖下载操作,也可以不删除
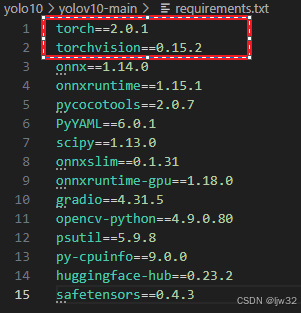
7.文件目录结构
从自己创建yolo文件开始,整个目录结构如下图:
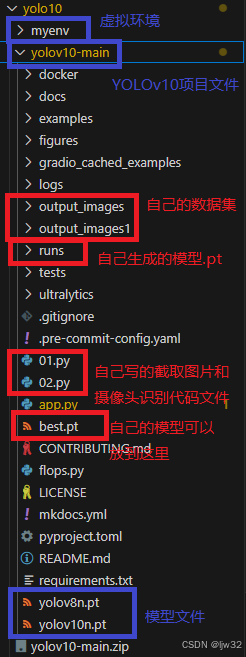
蓝色部分就是当前所需的内容,红色部分是后期添加的,所以你当前只需保证有蓝色部分的内容即可
二、数据采集和模型训练
1.数据采集即数据集(图片集):
截图摄像头图片,运行该代码会开启摄像头,按s截图,图片存放在output_images文件里,按ESC退出
#该代码起名为01.py,所以运行 python 01.py 即可
import cv2
import os
cap=cv2.VideoCapture(0)
cap.set(3, 640) # set Width
cap.set(4, 480) # set Height
if not cap.isOpened():
print("can't open the webcam")
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
print("pix:".format(width, height))
output_dir='output_images'
os.makedirs(output_dir,exist_ok=True)
img_counter=0
while True:
ret,frame=cap.read()
if not ret:
break
cv2.imshow('Webcam',frame)
k=cv2.waitKey(1)
if k%256==27:
print("Escape hit,closing...")
break
elif k%256==ord('s') : #s save frame
img_name=os.path.join(output_dir,"opencv_frame_{}.png".format(img_counter))
cv2.imwrite(img_name,frame)
print("{}保存".format(img_name))
img_counter+=1
cap.release()
cv2.destroyAllWindows()2.收集数据集后即可,即可开始标注
方式1:
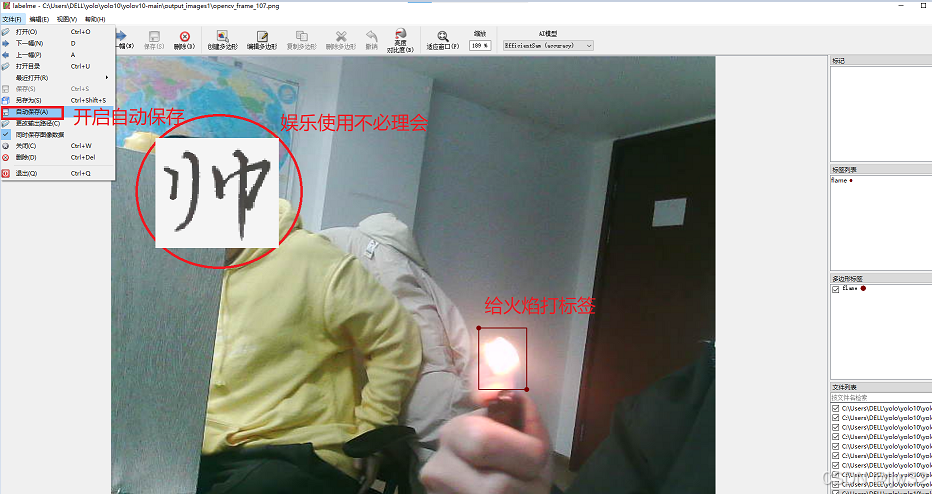
本地标注,labelme是运行本地标注工具
命令行输入:labelme
下一张 d ;上一张 a
方式2:
在线标注 roboflow在线标注
3.数字标注后生成训练集和验证集步骤:
终端输入:
labelme2yolo --json_dir 此处为绝对路径
如之前我数据集存放的文件是output_images:
labelme2yolo --json_dir C:\Users\DELL\yolo\yolo10\yolov10-main\output_images按照如上操作后在数据集文件output_images下会生成YOLODataset文件
打开dataset.yaml模型训练配置文件,你就会看到
path: \\?\C:\Users\DELL\yolo\yolo10\yolov10-main\output_images\YOLODataset
train: images/train
val: images/val
test:
# train 训练集
# val 验证集
# test 测试集
names:
0: flame
4.模型训练
命令行输入:yolo detect train data=data.yaml model=yolov10n.pt epochs=20 batch=8 imgsz=640 device=0
参数说明
yolo detect train 训练关键词 固定文件
data=data.yaml 模型配置文件
model=yolov10n.pt 模型文件
epochs=20 训练回合数
batch=8 训练批次大小,即每个批次样本数
imgsz=640 训练文件大小
ddevice=0 训练显卡 一块就是0,没有就去掉
比如我的模型配置文件是dataset.yaml,相对路径是./output_images/YOLODataset/dataset.yaml
我选用的模型文件是yolov10n.pt,所以命令行输入:
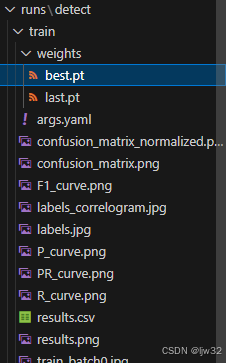
yolo detect train data=./output_images/YOLODataset/dataset.yaml model=yolov10n.pt epochs=20 batch=8 imgsz=640 device=0通过上述操作后会生成runs文件,best.pt是根据你的数据集训练出来的效果最佳的模型,last.pt是最后一次生成的模型,一般使用best.pt模型
5.目标检测
通过上述的操作后你已经训练出了自己的模型,可以识别自己数据集中的物品
代码实现如下:
自定义模型图片识别,此处做的是摄像头的目标检测,使用的模型是best.pt
#此处我将该代码存放在02.py,所以直接运行:python 02.py
import cv2
import supervision as sv
from ultralytics import YOLOv10
model = YOLOv10(f'best.pt')
# bounding_box_annotator = sv.BoundingBoxAnnotator()
bounding_box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
cap=cv2.VideoCapture(0, cv2.CAP_DSHOW)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
if not cap.isOpened():
print("can't open the webcam")
while True:
ret,frame=cap.read()
if not ret:
break
results = model(frame)[0]
detections = sv.Detections.from_ultralytics(results)
annotated_image = bounding_box_annotator.annotate(scene=frame, detections=detections)
annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)
cv2.imshow('Webcam',annotated_image)
k=cv2.waitKey(1)
if k%256==27:
print("Escape hit,closing...")
break
cap.release()
cv2.destroyAllWindows()如果识别不出来可以试着使用last.pt模型,实在不行就增加数据集的数量 即多拍一些图片,或者在第4步时使用其他更大的模型文件,模型文件在:https://github.com/THU-MIG/yolov10
6.识别结果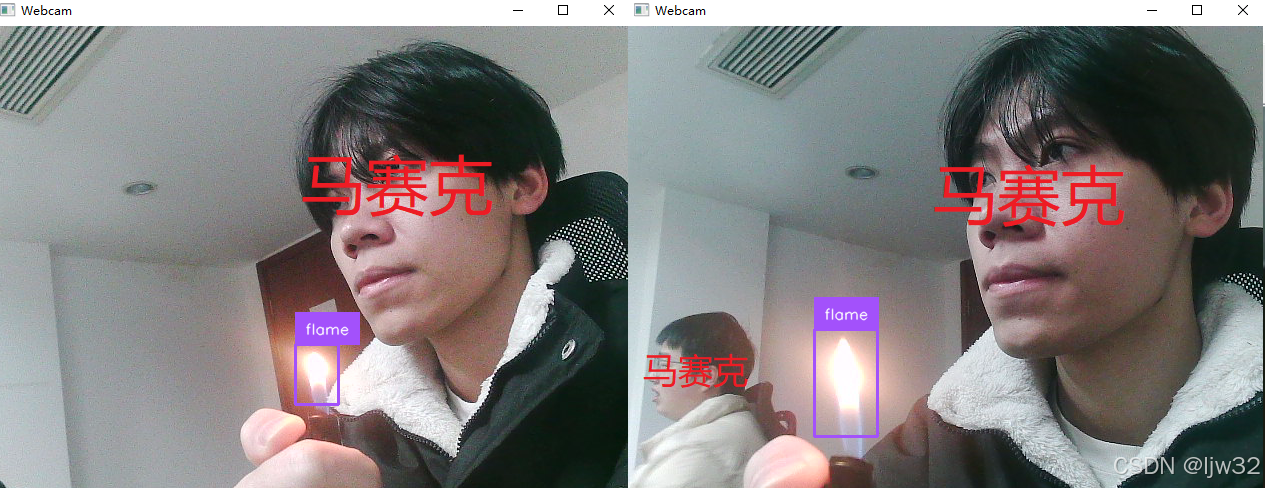

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









