








筑基
最近因为负责部门的数据归档目标为ES,本着学以致用惯性连同ELK玩了下;本文主要是对ElasticSearch热门中文分词器:IK-Analyzer中热词功能的两种扩展如何实现,以及实现过程中的渡劫之路showtime。
从IK官方文档中只给出1种扩展方式:基于远程词库
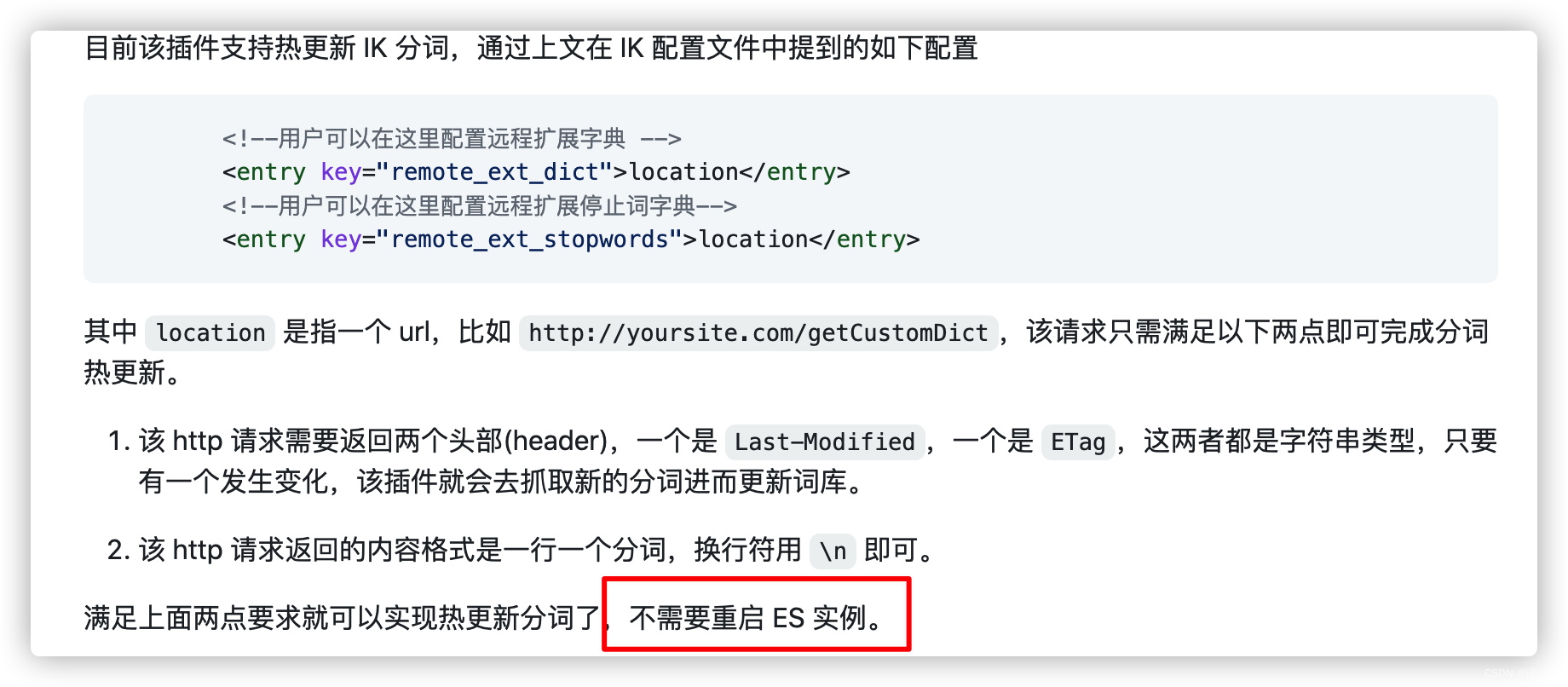
该方案的优点显而易见,但是一切皆建立在不同业务场景下,官方推荐未必能考虑到所有的应用场景,通过笔者了解还有更为高效处理方式,今天两个都进行手撸【老规矩,莫要白嫖!】
持鱼-基于远程词库加载停用词
按官方所述,需要提供一个API便于加载,改API中至少维护
Last-Modified或ETag
变化,Talk is cheap,show my code:
@GetMapping("/extend_word/{type}")
public void extendWord(HttpServletResponse response, @PathVariable(name = "type") Integer type) {
try {
String filePath = "src/ik/" + (type == 1 ? "extend_word.txt" : "extend_stopword.txt");
File file = new File(filePath);
response.setContentType("text/plain;charset=utf-8");
// 有一个发生变化
response.setHeader("Last-Modified", String.valueOf(file.length()));
// response.setHeader("ETag", String.valueOf(file.length()));
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
StringBuilder sb = new StringBuilder();
String str;
while((str = bufferedReader.readLine()) != null){
sb.append(str).append("\n");
}
sb.deleteCharAt(sb.length() - 1);
ServletOutputStream outputStream = response.getOutputStream();
outputStream.write(sb.toString().getBytes());
outputStream.flush();
outputStream.close();
bufferedReader.close();
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}

先别解释,看看效果在说:
不启动远程词库:
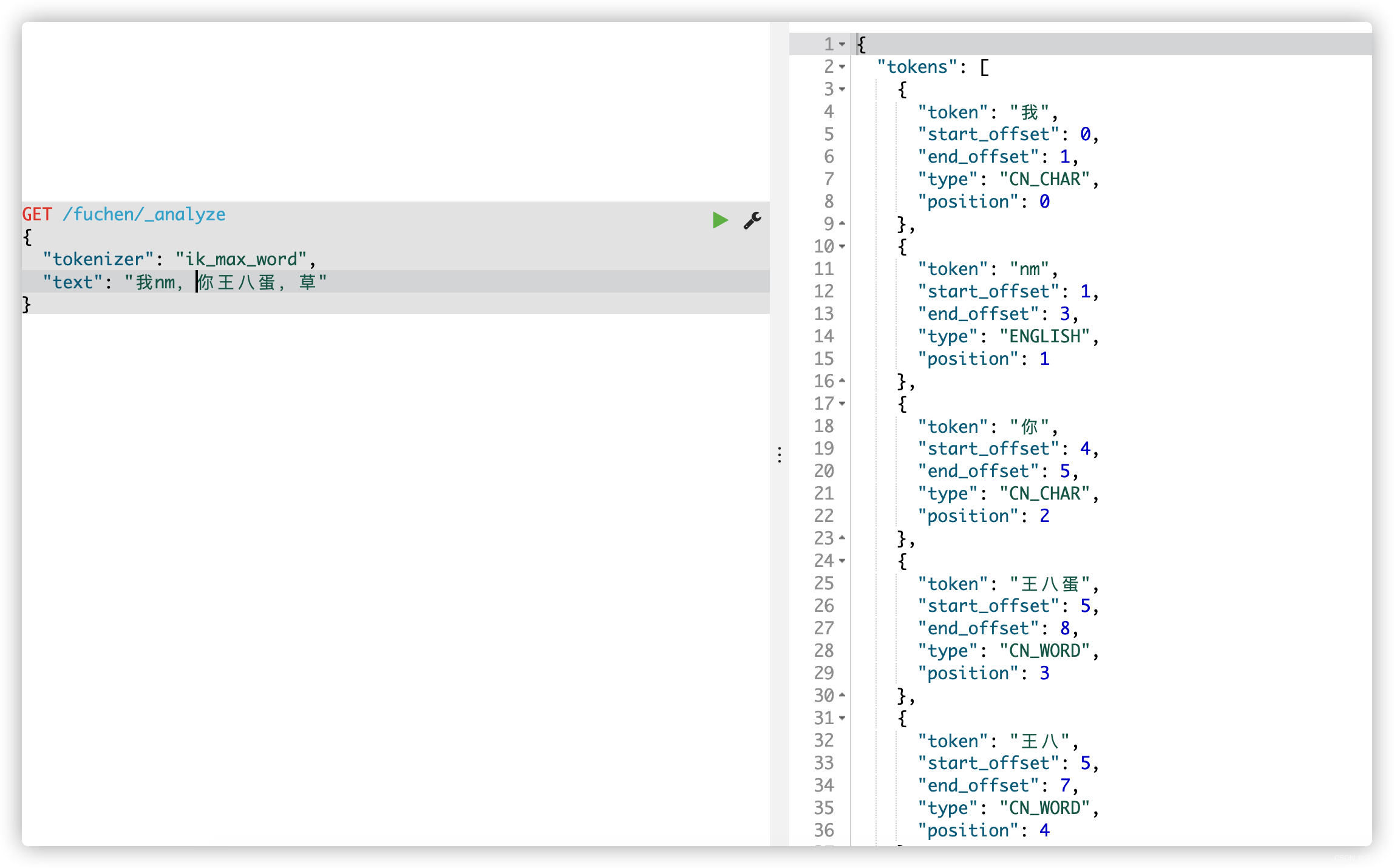
这要是在你网站上, 不好好过滤下,基本就要裂开了,OK,开启远程词库再看下【注意我没有重新启动ES,虽然无法证明,但童叟无欺好吧】:
- 先启动提供更新API服务
- 找到IK的配置文件IKAnalyzer.cfg.xml

- show case
ES后台已经出现效果了,我们再次看看kibana上是否生效

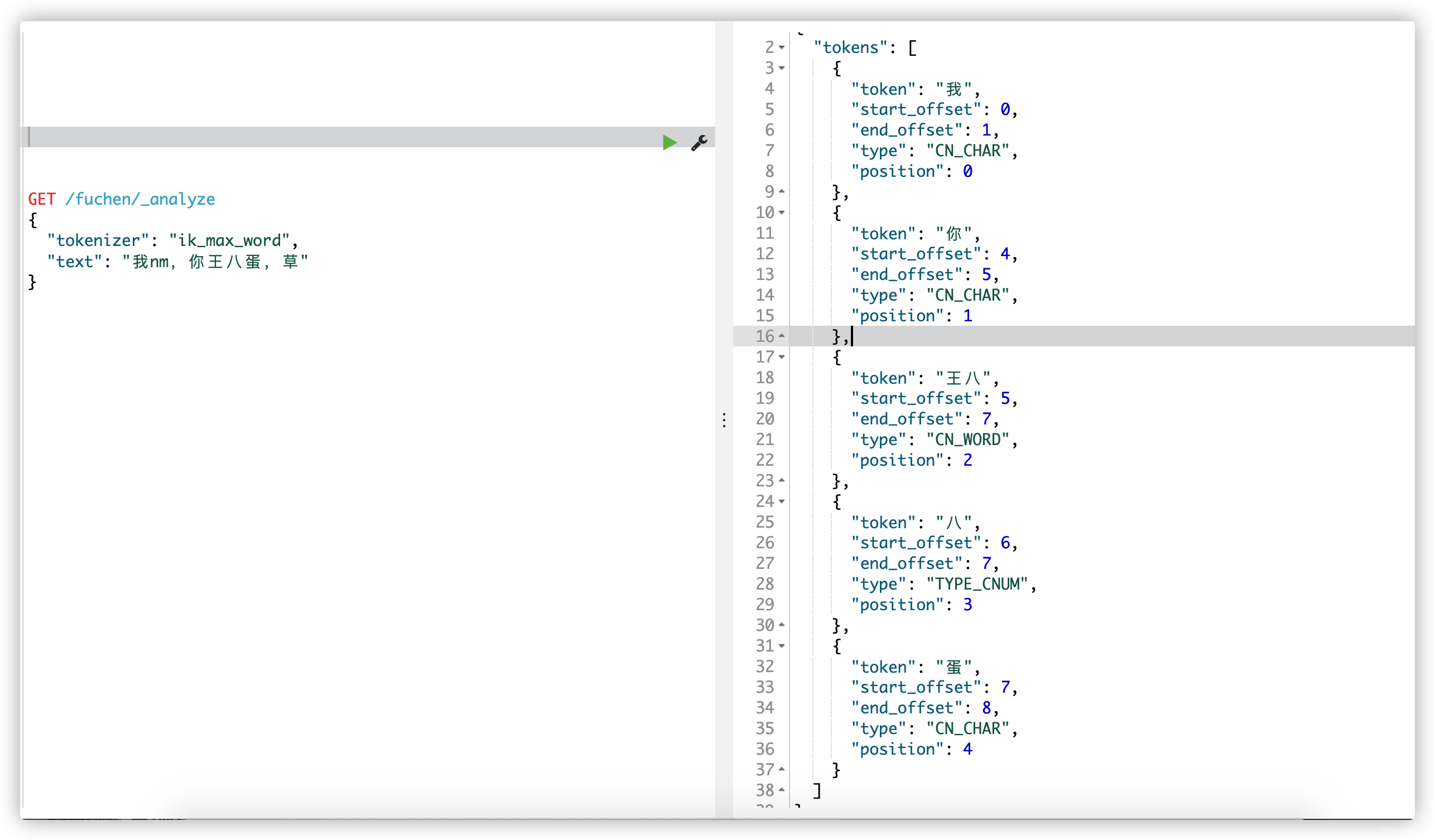
思考几个问题:
优点:
- 无需重启,即刻生效
- 跨平台,语言无惯性,提供接口即可
- 上手门槛低
缺点:
- 为了这个接口要么基于业务,要么重新部署。
- 更新热词的频率,不能直接控制,默认70秒延迟
持渔-基于MySQL加载热词
同理,先上coding,哦不先啰嗦两句,该方式核心就是改源码,自定义扩展实现
1. 先去官网写在源代码压缩包
2. 关注核心类Dictionary
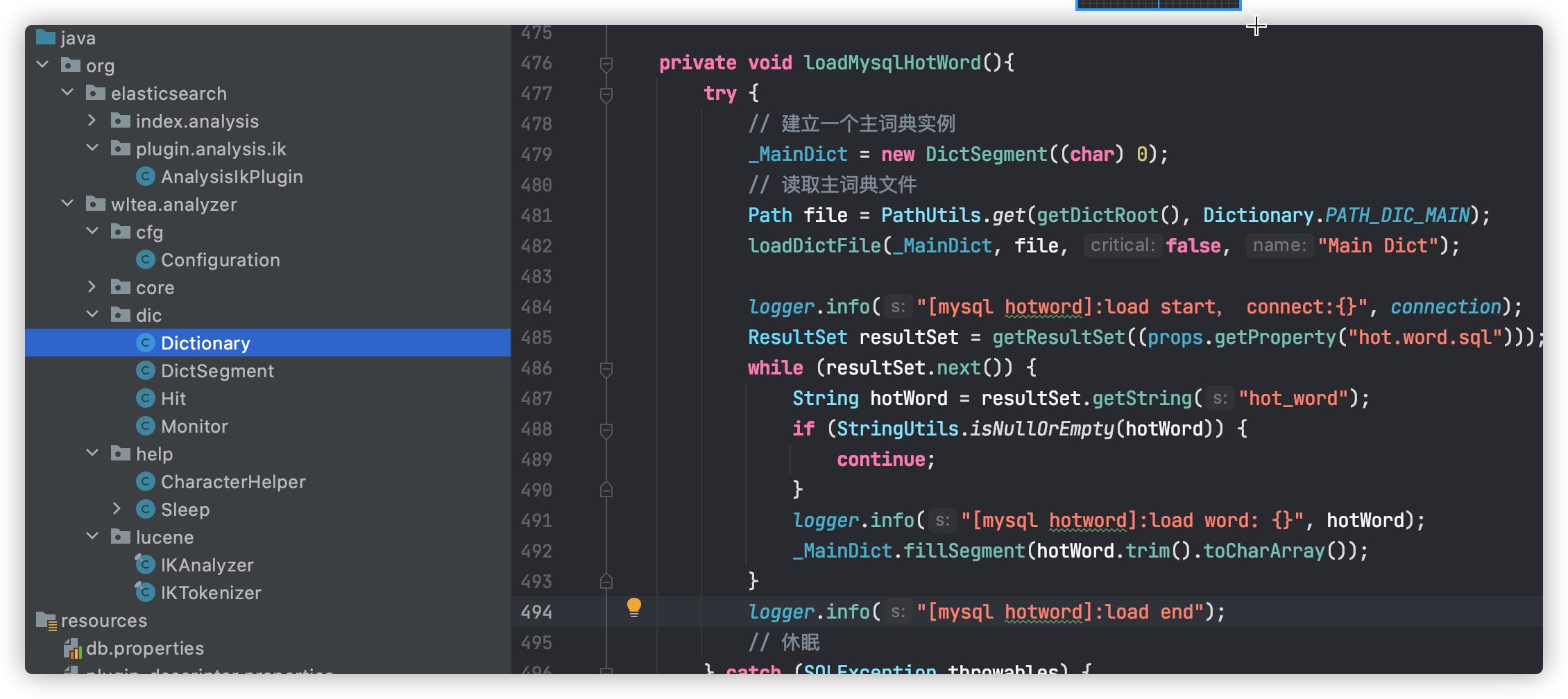
3. 照猫画虎-自定义扩展方法
这里采用Mysql,未必要和我一样,其他存储类midleware 如:mongodb、redis都可以
private static final Properties myProps = new Properties();
private static Connection connection = null;
static {
//获取数据库连接
try {
Class.forName("com.mysql.cj.jdbc.Driver");
myProps.load(Dictionary.class.getClassLoader().getResourceAsStream("db.properties"));
connection = DriverManager.getConnection(myProps.getProperty("url"), myProps.getProperty("uname"), myProps.getProperty("password"));
// System.out.println("test props" + myProps.getProperty("uname") + " -- con:" + connection);
} catch (Exception e) {
e.printStackTrace();
}
}
private void loadMysqlHotWord(){
try {
// 建立一个主词典实例
_MainDict = new DictSegment((char) 0);
// 读取主词典文件
Path file = PathUtils.get(getDictRoot(), Dictionary.PATH_DIC_MAIN);
loadDictFile(_MainDict, file, false, "Main Dict");
logger.info("[mysql hotword]:load start, connect:{}", connection);
ResultSet resultSet = getResultSet((props.getProperty("hot.word.sql")));
while (resultSet.next()) {
String hotWord = resultSet.getString("hot_word");
if (StringUtils.isNullOrEmpty(hotWord)) {
continue;
}
logger.info("[mysql hotword]:load word: {}", hotWord);
_MainDict.fillSegment(hotWord.trim().toCharArray());
}
logger.info("[mysql hotword]:load end");
// 休眠
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
private void reloadMysqlHotWord() {
logger.info("mysql自定义词典加载...");
Dictionary tmpDict = new Dictionary(configuration);
tmpDict.configuration = getSingleton().configuration;
tmpDict.loadMysqlHotWord();
tmpDict.loadMysqlStopWord();
_MainDict = tmpDict._MainDict;
_StopWords = tmpDict._StopWords;
logger.info("mysql自定义词典加载完毕!");
}
4. 初始化中线程热更新
我这里为了演示,每10秒开1次,可以根据自己的业务特定灵活控制。
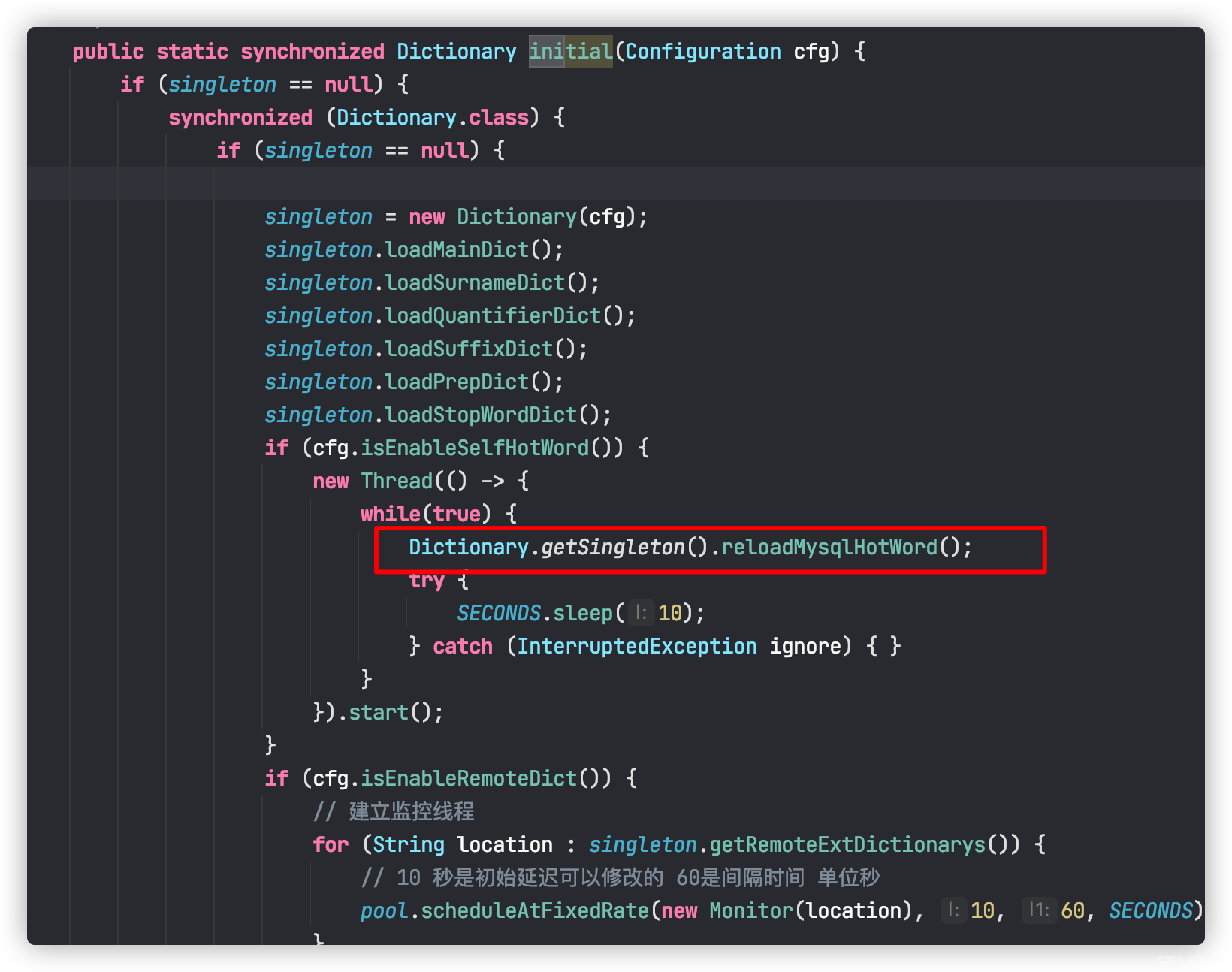
5. 重新打包,并重新启动ES:
控制台已经有效果了,来看看生效结果

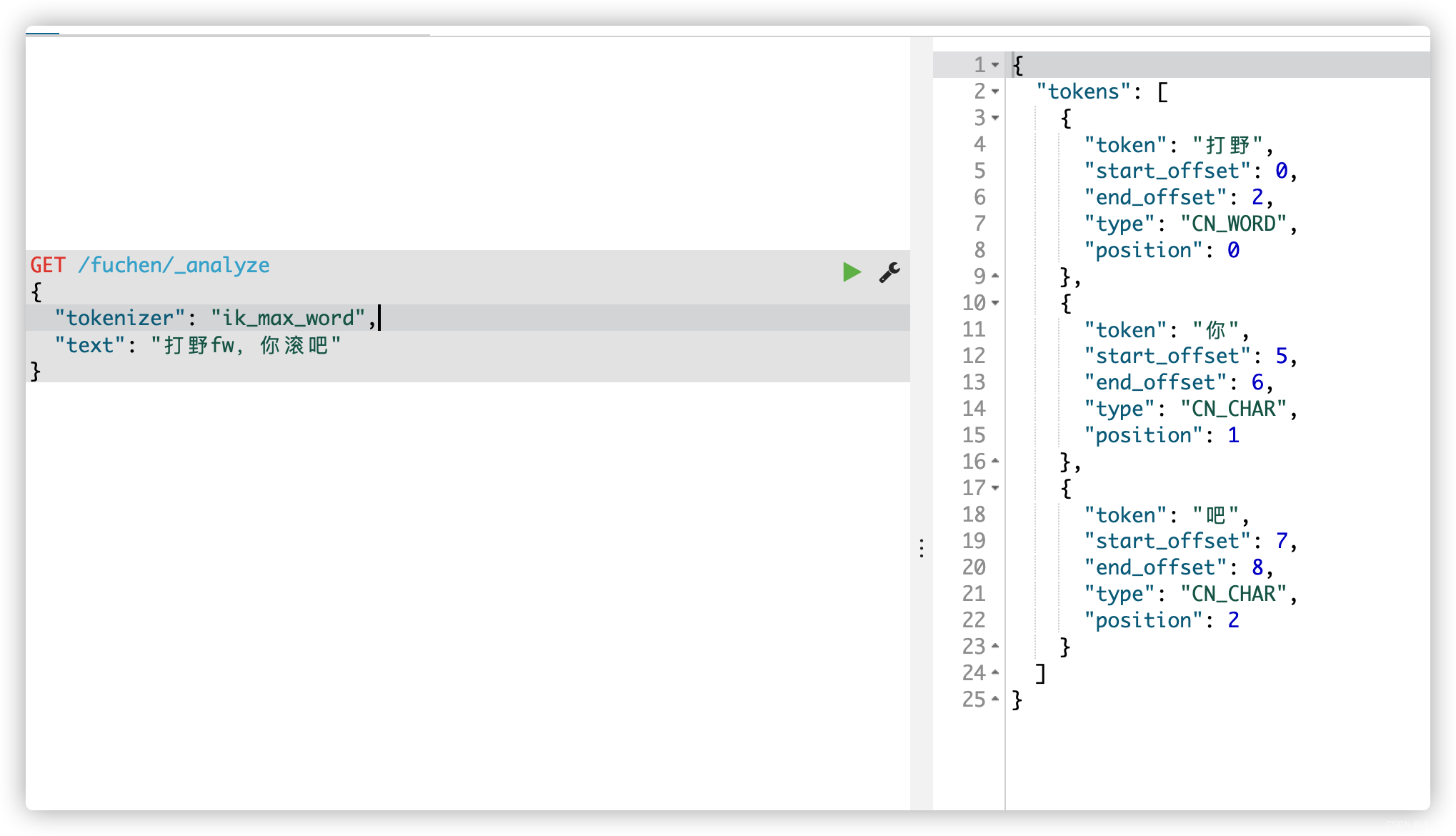
继续思考:
优点:
- 无需单独部署,重新打包即可
- 更新频率完全由自己控制
- 维护方便,黑盒;直接操作你所选型存储中间件即可
缺点:
- 上手难度2颗星
- 源代码侵入,安全策略需要注意
- 你需要会java,因为IK是java写的
飞升
然而,你所看到的都是笔者忙活一天的结晶,然后你没有感受到我被一堆奇葩的问题摁在地上摩擦的那种痛,堪比DYM【手动diss自己:一个插件研究一早上一下午,真的是老了】
写代码永远是开发中最简单的,但是想要AC,就要七上八下,使出浑身解数【咳咳,DDDD】
- 权限检查
由于IK作者对源码增加了安全访问策略的限制,一开始没有注意到,会看到控制台报错
Caused by: java.security.AccessControlException: access denied (“java.lang.RuntimePermission” “setContextClassLoader”)
at java.base/java.security.AccessControlContext.checkPermission(AccessControlContext.java:485)
at java.base/java.security.AccessController.checkPermission(AccessController.java:1068)
at java.base/java.lang.SecurityManager.checkPermission(SecurityManager.java:416)
关于安全策略是Java在1.0的时候就已经具备了,有兴趣可以单独看看,其实提升也比较明显,我们只需要加入对应安全免检测即可:有两种方式,详情参考安全策略通过
有一点需要注意,安全策略的规避不应该放大,否则便失去了java本身的优良特性,因此建议选择介绍中的方案二
- 跳出舒适圈
其实是打包后运行时遇到一些令人窒息的操作,
- 比如properties 配置文件读取,因为在调试时IDEA先天性优势,可以基于项目路径自动识别,但是打包后,脱离IDEA,FileNotFoundException 就跟我闹:
解决核心就是: xxx.class.getClassLoader().getResourceAsStream("db.properties“)- 还有采用了JDBC,原来靠着mvn给我引入,运行的时候忘记手动导包,被ClassNotFoundExcepton 整的头皮发麻,到底是太安逸了现在的开发环境。
元婴
其实每次在玩的技术栈或者工具时,总会有一段难以言语的扯疼,仿佛一生就此要结束,殊不知贪恋人世界的我们怎会如此妥协,势必要跟它斗上一斗,努力过后虽未必成功,但深刻于心,沉淀于忆,迸发于coding。
下一期我们研究下ELKB,敬请关注。















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









