







本文已收录 https://github.com/lkxiaolou/lkxiaolou 欢迎star。搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践。
背景
最近某天的深夜,刚洗完澡就接到业务方打来电话,说他们的 dubbo 服务出故障了,要我协助排查一下。
电话里,询问了他们几点
- 是线上有损故障吗?——是
- 止损了吗?——止损了
- 有保留现场吗?——没有
于是我打开电脑,连上 VPN 看问题。为了便于理解,架构简化如下
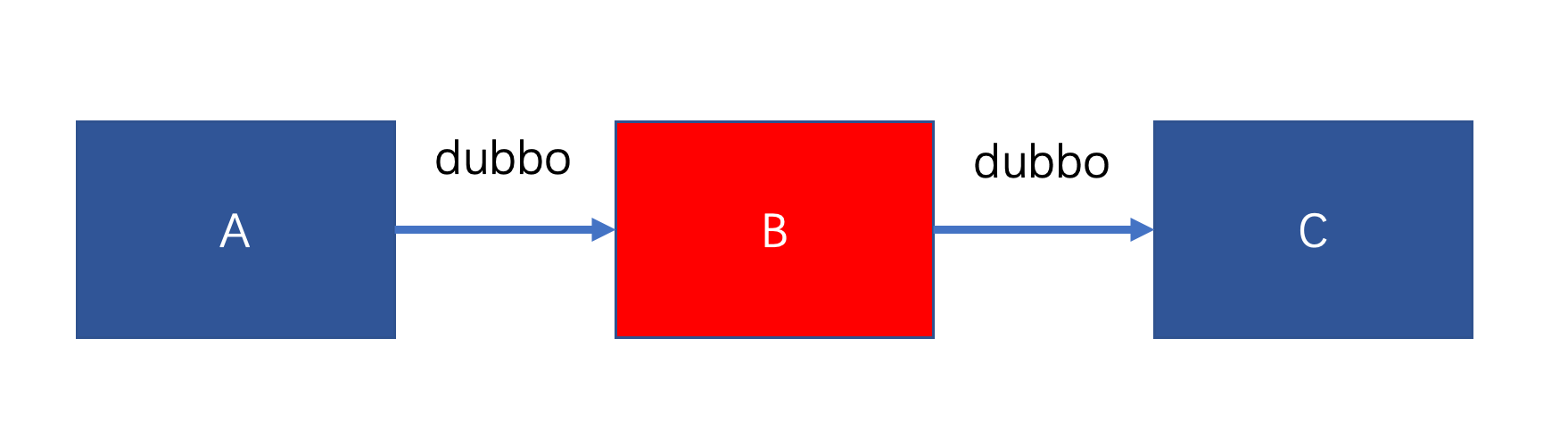
只需要关注 A、B、C 三个服务,他们之间调用都是 dubbo 调用。
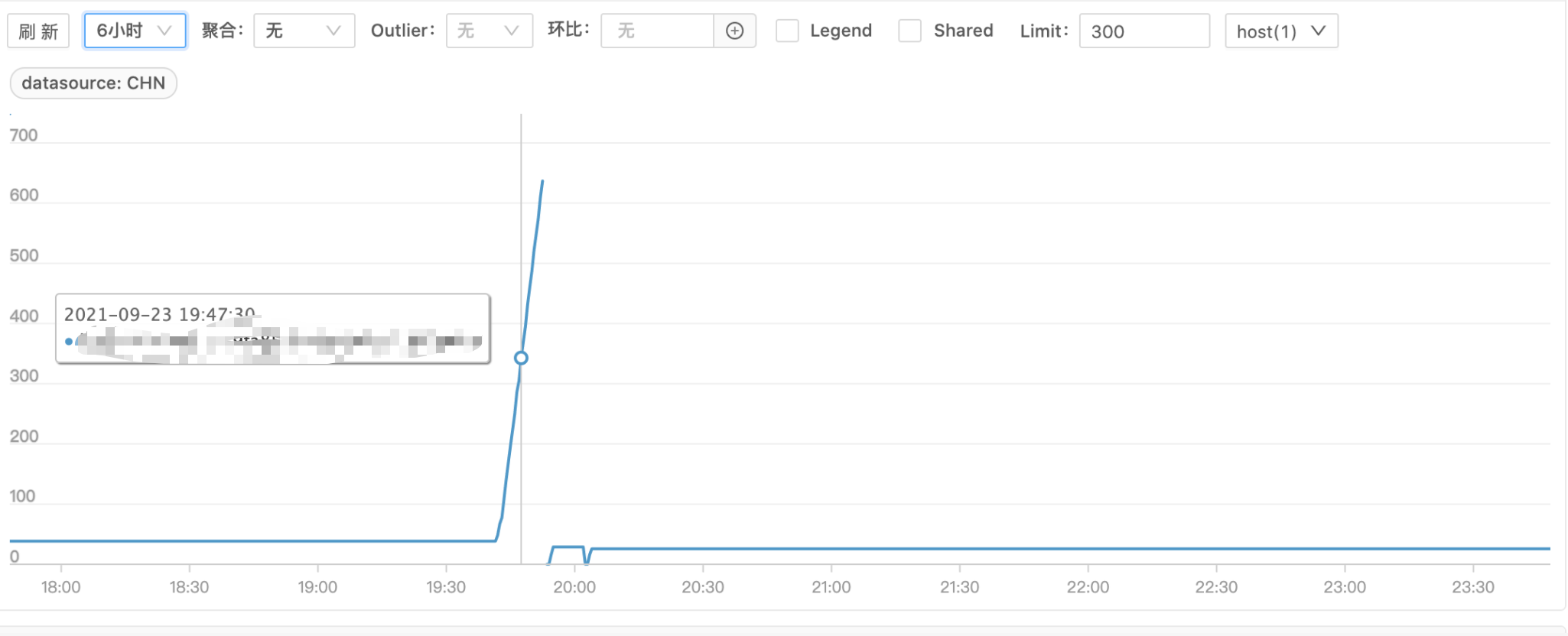
发生故障时 B 服务有几台机器完全夯死,处理不了请求,剩余正常机器请求量激增,耗时增加,如下图(图一请求量、图二耗时)
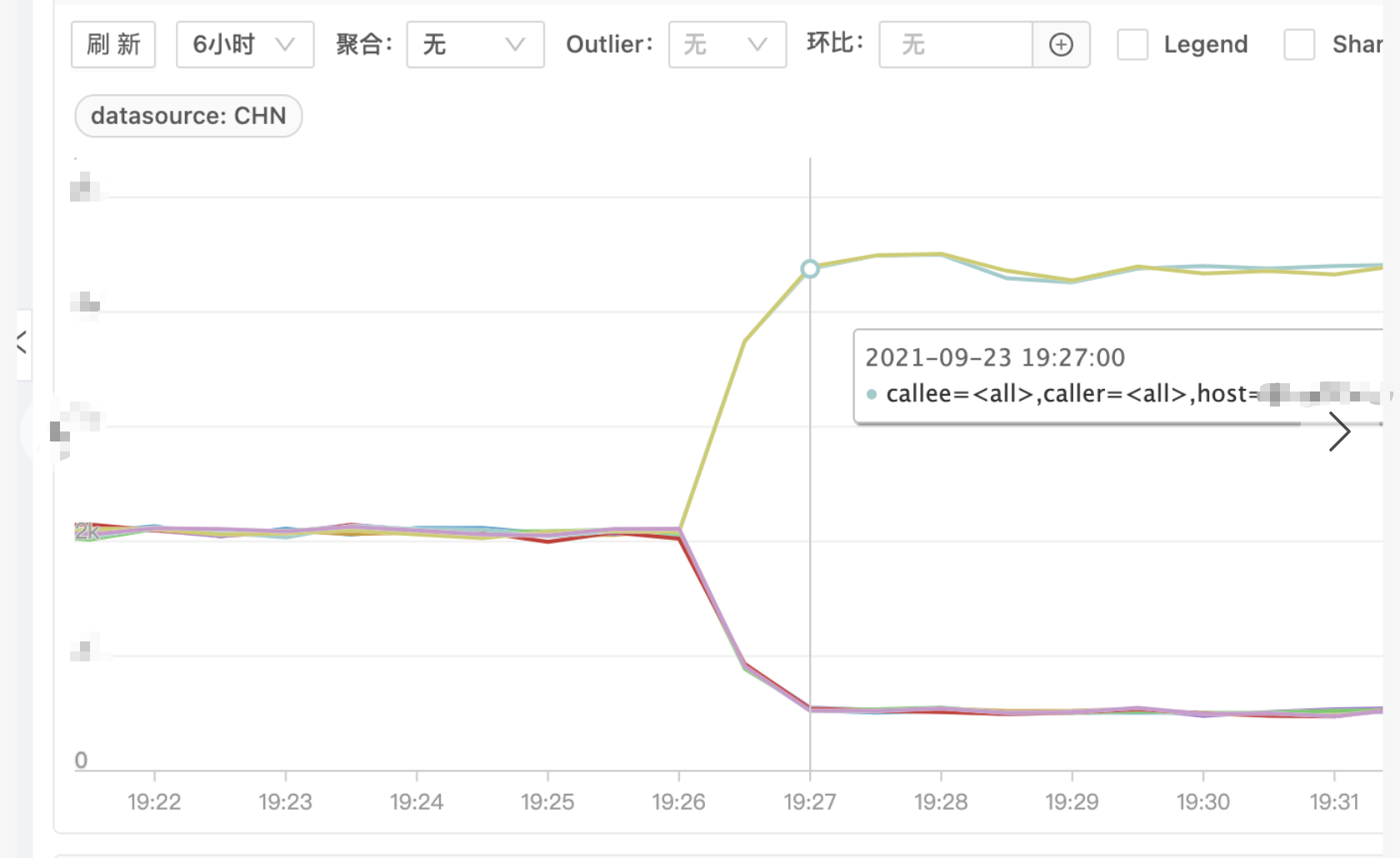
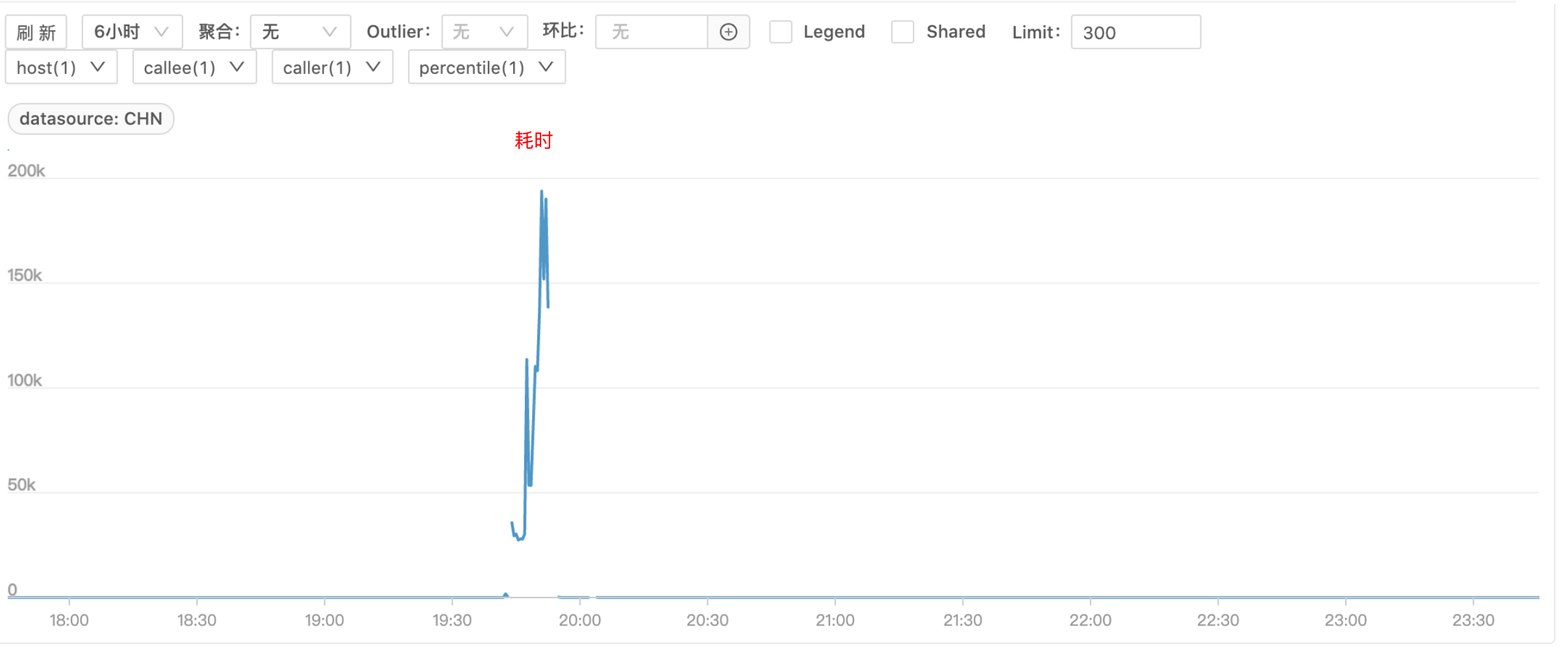
问题排查
由于现场已被破坏,只能先看监控和日志
- 监控
除了上述监控外,翻看了 B 服务 CPU 和内存等基础监控,发现故障的几台机器内存上涨比较多,都达到了 80% 的水平线,且 CPU 消耗也变多
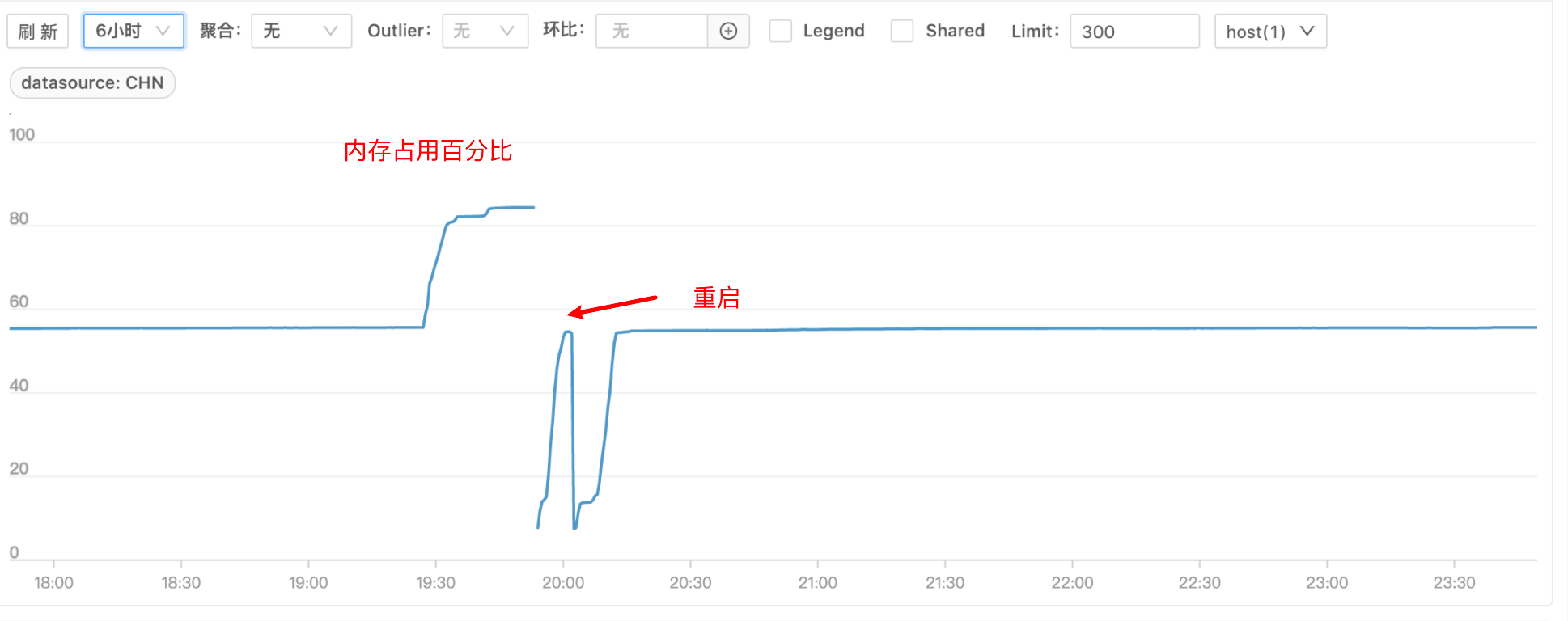
这时比较怀疑内存问题,于是看了下 JVM 的 fullGC 监控
果然 fullGC 时间上涨很多,基本可以断定是内存泄漏导致服务不可用了。但为什么会内存泄漏,还无法看出端倪。
- 日志
申请机器权限,查看日志,发现了一条很奇怪的 WARN 日志
[dubbo-future-timeout-thread-1] WARN org.apache.dubbo.common.timer.HashedWheelTimer$HashedWheelTimeout
(HashedWheelTimer.java:651)
- [DUB 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1758
1758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









