







一. HBase的介绍
列的而不是基于行的模式。
二.HBase体系结构
1. 设计思路
HBase是一个分布式的数据库,使用Zookeeper管理集群,使用HDFS作为底层存储。在架构层面上由HMaster(Zookeeper选举产生的Leader)和多个HRegionServer组成,基本架构如下图所示:
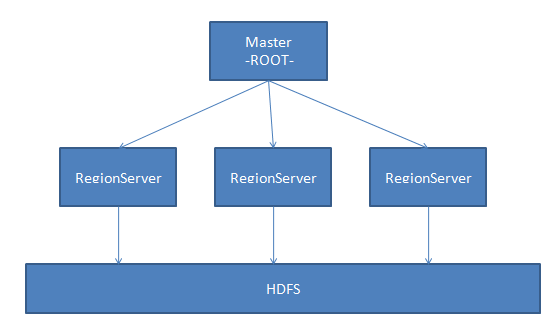
在HBase的概念中,HRegionServer对应集群中的一个节点,一个HRegionServer负责管理多个HRegion,而一个HRegion代表一张表的一部分数据。在HBase中,一张表可能会需要很多个HRegion来存储数据,每个HRegion中的数据并不是杂乱无章的。HBase在管理HRegion的时候会给每个HRegion定义一个Rowkey的范围,落在特定范围内的数据将交给特定的Region,从而将负载分摊到多个节点,这样就充分利用了分布式的优点和特性。另外,HBase会自动调节Region所处的位置,如果一个HRegionServer过热,即大量的请求落在这个HRegionServer管理的HRegion上,HBase就会把HRegion移动到相对空闲的其它节点,依次保证集群环境被充分利用。
2. 基本架构
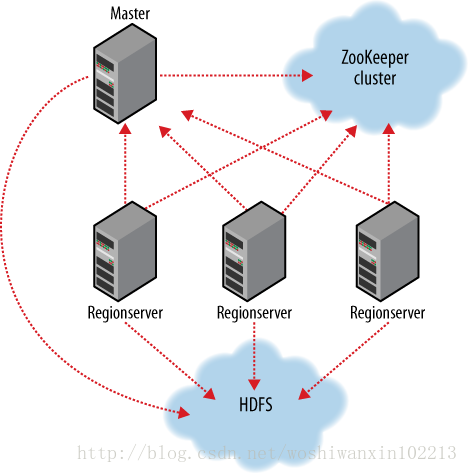
HBase由HMaster和HRegionServer组成,同样遵从主从服务器架构。HBase将逻辑上的表划分成多个数据块即HRegion,存储在HRegionServer中。HMaster负责管理所有的HRegionServer,它本身并不存储任何数据,而只是存储数据到HRegionServer的映射关系(元数据)。集群中的所有节点通过Zookeeper进行协调,并处理HBase运行期间可能遇到的各种问题。HBase的基本架构如下图所示:
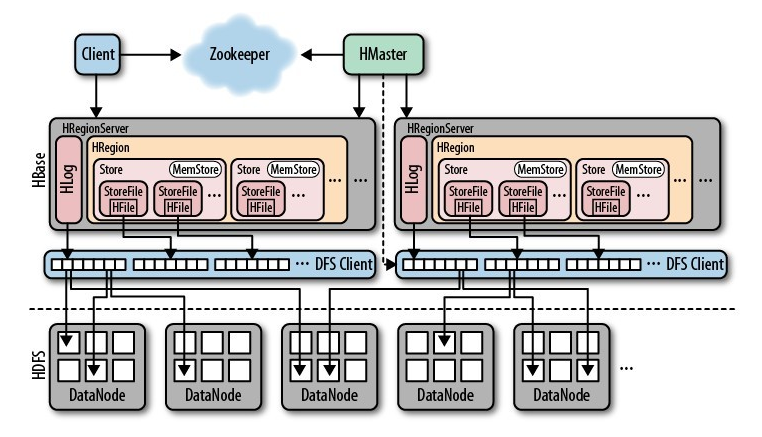
Client:使用HBase的RPC机制与HMaster和HRegionServer进行通信,提交请求和获取结果。对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC。
Zookeeper:通过将集群各节点状态信息注册到Zookeeper中,使得HMaster可随时感知各个HRegionServer的健康状态,而且也能避免HMaster的单点问题。
- 通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
- 存贮所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给Master
- 存储HBase的schema和table元数据
- 默认情况下,HBase 管理ZooKeeper 实例,比如, 启动或者停止ZooKeeper
- Zookeeper的引入使得Master不再是单点故障
HMaster:管理所有的HRegionServer,告诉其需要维护哪些HRegion,并监控所有HRegionServer的运行状态。当一个新的HRegionServer登录到HMaster时,HMaster会告诉它等待分配数据;而当某个HRegion死机时,HMaster会把它负责的所有HRegion标记为未分配,然后再把它们分配到其他HRegionServer中。HMaster没有单点问题,HBase可以启动多个HMaster,通过Zookeeper的选举机制保证集群中总有一个HMaster运行,从而提高了集群的可用性。
HRegion:当表的大小超过预设值的时候,HBase会自动将表划分为不同的区域,每个区域包含表中所有行的一个子集。对用户来说,每个表是一堆数据的集合,靠主键(RowKey)来区分。从物理上来说,一张表被拆分成了多块,每一块就是一个HRegion。我们用表名+开始/结束主键,来区分每一个HRegion,一个HRegion会保存一个表中某段连续的数据,一张完整的表数据是保存在多个HRegion中的。
在HRegion下介绍一下切分和分配大表的内容
HBase中的表是由行和列组成的。HBase中的表可能达到数十亿行和数百万列。每个表的大小可能达到TB级,有时甚至PB级。这些表会切分成小一点儿的数据单位,然后分配到多台服务器上。这些小一点儿的数据单位叫region。托管region的服务器叫RegionServer。一张表由多个小一点的region组成,如图1所示。 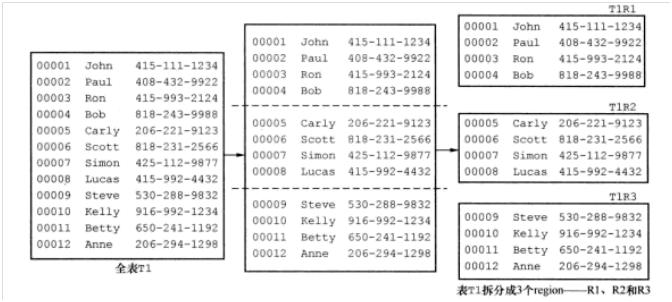
图1 多个小一点的region组成一张表
RegionServer和HDFS DataNode典型情况下并列配置在同一物理硬件上,如图2所示。RegionServer本质上是HDFS客户端,在上面存储/访问数据。主(master)进程分配region给RegionServer,每个RegionServer一般托管多个region。 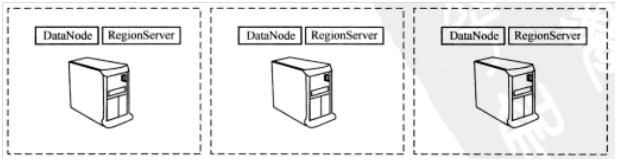
图2 RegionServer和DataNode典型情况下并列配置在同一台主机上
考虑到基础数据存储在HDFS上,所有客户端都可以在一个命名空间下访问。所有RegionServer都可以访问文件系统里同一个文件,因此RegionServer可以托管任何region,如图3所示。通过DataNode和RegionServer并列配置,理论上RegionServer可以把本地DataNode作为主要DataNode进行读写操作。 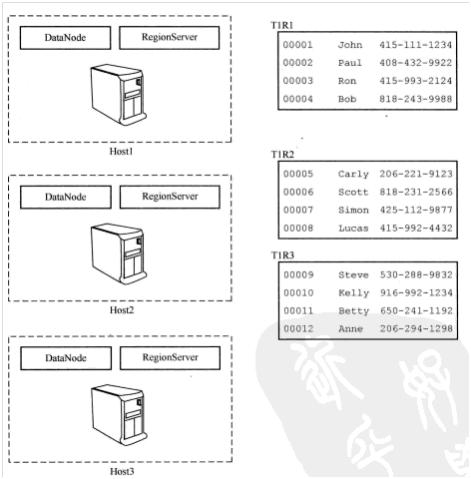
图3 RegionServer托管region的示意图
单个region大小由hbase-site.xml文件里的配置参数HBase.hregion.max.filesize决定,当一个region大小变得大于该值时,它会切分成两个region。
如何找到region
当一个region分配给RegionServer时,客户端应用如何知道它的位置?
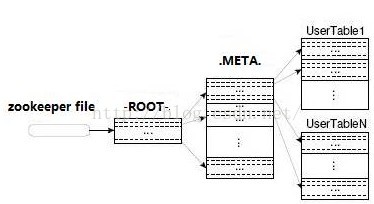
HBase中有两个特殊的表,-ROOT-和.META.,用来查找各种表的region位置在哪里。-ROOT-和.META.也会切分成region,其中,-ROOT-永远不会切分超过一个region,.META.和其他表一样可以按需切分成许多region。
当客户端应用要访问某行时,它先找-ROOT-表,查找什么地方可以找到负责某行的region。-ROOT-指向.META.表的region去寻找答案。.META.表由入口地址组成,客户端应用使用这个入口地址判断哪一个RegionServer托管待查找的region。这个查找过程就像是一个3层分布式B+树(如图4所示),-ROOT-表是B+树的-ROOT-节点,.META. region是-ROOT-节点的叶子,用户表的region是.META. region的叶子。 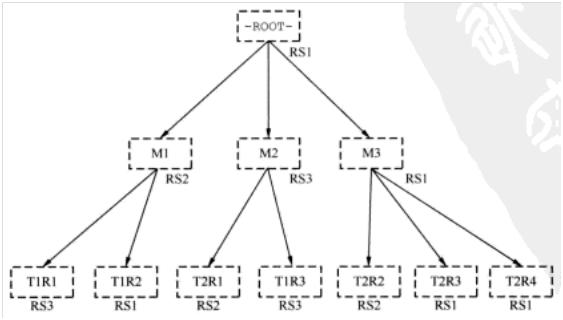
图4 -ROOT-、.META.和用户表的B+树视图
在图4中,-ROOT-表只包含了一个region,托管在RegionServer RS1上;.META.表包含了3个region,托管在RS1、RS2和RS3上面;用户表T1和T2分别包含3个和4个region,分别在RS1、RS2和RS3上面。 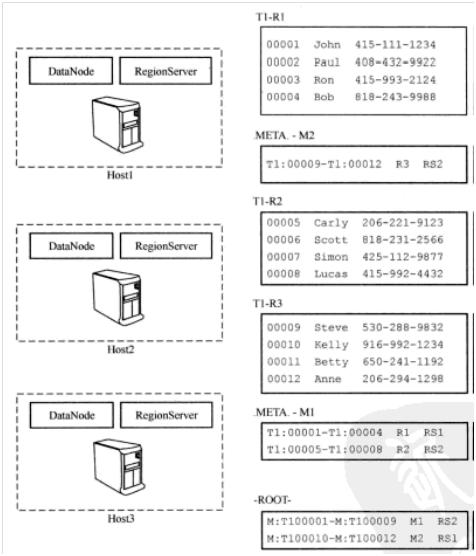
图5 HBase中的表分布在各个RegionServer上
如图5所示,RegionServer 1(RS1)托管用户表T1的region R1和.META.表的region M2;RegionServer 2(RS2)托管用户表的region R2、R3和.META.表的region M1;RegionServer 3(RS3)只托管了-ROOT-。
HRegionServer:HBase中的所有数据从底层来说一般都是保存在HDFS中的,用户通过一系列HRegionServer获取这些数据。集群一个节点上一般只运行一个HRegionServer,且每一个区段的HRegion只会被一个HRegionServer维护。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统读写数据,是HBase中最核心的模块。HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了逻辑表中的一个连续数据段。HRegion由多个HStore组成,每个HStore对应了逻辑表中的一个列族的存储,可以看出每个列族其实就是一个集中的存储单元。因此,为了提高操作效率,最好将具备共同I/O特性的列放在一个列族中。
HStore:HBase存储的核心。由MemStore和StoreFile组成。
MemStore是Sorted Memory Buffer。用户写入数据的流程:
如下图所示,StoreFile文件数量达到4个的时候(默认的数量是4个),每个文件大小64M(特别注意:版本1的时候是64M,版本2的时候是128M),合并后的文件如果大于256M(版本2的时候是512M)的时候,就会拆分成2个128M的文件,这样split的两个文件分别存储到2个不同RegionServer下的Region;
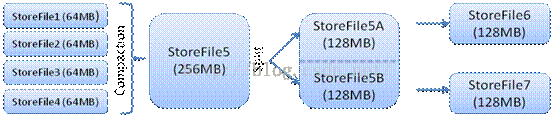
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile ->单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个Region,Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上
由此过程可知,HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能。
HLog:引入HLog原因:
在分布式系统环境中,无法避免系统出错或者宕机,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,引入HLog就是防止这种情况;
工作机制:
每 个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到 StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知,HMaster首先处理遗留的 HLog文件,将不同region的log数据拆分,分别放到相应region目录下,然后再将失效的region重新分配,领取到这些region的 HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
3. HBase存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,格式主要有两种:
1 HFile HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
2 HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File
HFile

HFile文件不定长,长度固定的块只有两个:Trailer和FileInfo
Trailer中指针指向其他数据块的起始点
File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN,AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等
Data Index和Meta Index块记录了每个Data块和Meta块的起始点
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制
每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询
每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏
HFile里面的每个KeyValue对就是一个简单的byte数组。这个byte数组里面包含了很多项,并且有固定的结构。

KeyLength和ValueLength:两个固定的长度,分别代表Key和Value的长度
Key部分:Row Length是固定长度的数值,表示RowKey的长度,Row 就是RowKey
Column Family Length是固定长度的数值,表示Family的长度
接着就是Column Family,再接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)
Value部分没有这么复杂的结构,就是纯粹的二进制数据
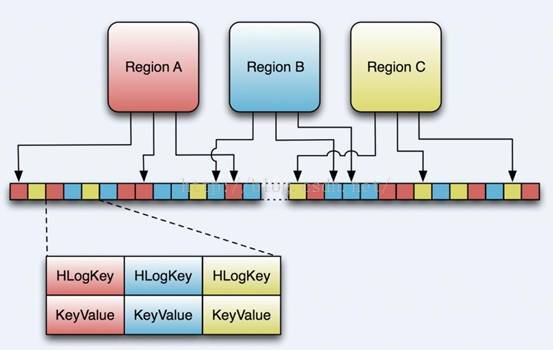
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue
4. ROOT表和META表
-ROOT- 保存 .META. 表存在哪里的踪迹. -ROOT- 表结构如下:
Key:
.META. region key (.META.,,1)
Values:
info:regioninfo (序列化.META.的 HRegionInfo 实例 )
info:server ( 保存 .META.的RegionServer的server:port)
info:serverstartcode ( 保存 .META.的RegionServer进程的启动时间)
.META. 保存系统中所有region列表。 .META.表结构如下:
Key:
Region key 格式 ([table],[region start key],[region id])
Values:
info:regioninfo (序列化.META.的 HRegionInfo 实例 )
info:server ( 保存 .META.的RegionServer的server:port)
info:serverstartcode ( 保存 .META.的RegionServer进程的启动时间)
以上是官网文档对于.meta.和-root-的描述,简而言之,-root-中存储了.meta.的位置,而在.meta.中保存了具体数据(region)的存储位置。如图:
Zookeeper中记录了-ROOT-表的location
客户端访问数据的流程:
Client -> Zookeeper -> -ROOT- -> .META.-> 用户数据表
多次网络操作,不过client端有cache缓存
a. 启动时序
1.启动时主服务器调用AssignmentManager.
2.AssignmentManager 在META中查找已经存在的区域分配。
3.如果区域分配还有效(如 RegionServer 还在线),那么分配继续保持。
4.如果区域分配失效,LoadBalancerFactory 被调用来分配区域。 DefaultLoadBalancer 将随机分配区域到RegionServer.
5.META 随RegionServer 分配更新(如果需要) , RegionServer 启动区域开启代码(RegionServer 启动时进程)
b.故障转移
当regionServer故障退出时:
1.区域立即不可获取,因为区域服务器退出。
2.主服务器会检测到区域服务器退出。
3.区域分配会失效并被重新分配,如同启动时序。
详细介绍如下:
一个叫做ZooKeeper的系统提供了HBase系统的入口点。ZooKeeper是一种集中服务,用来维护配置信息、命名服务、提供分布式同步和提供分组服务等。这是一种高可用的、可靠的分布式配置服务。
客户端与HBase系统的交互分几个步骤,ZooKeeper是入口点。整个交互过程如图6所示。 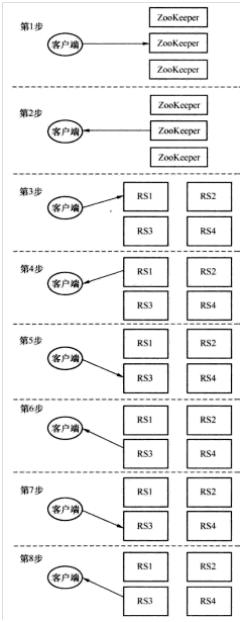
图6 客户端与HBase系统的交互过程
从图6可以看出,交互步骤为:
第一步:客户端询问ZooKeeper,-ROOT-在哪里?
第二步:ZooKeeper回复客户端,-ROOT-在RegionServer RS1上面。
第三步:客户端询问在RS1上的-ROOT-表,哪一个.META. region可以找到表T1里的行00007?
第四步:RS1上的-ROOT-表回复客户端,在RegionServer RS3上的.META. region M2可以找到。
第五步:客户端询问RS3上的.META. region M2,在哪一个region上可以找到表T1里的行00007以及哪一个RegionServer为它提供服务?
第六步:RS3上的.META. region M2回复客户端,数据在RegionServer RS3上面的region T1R3上。
第七步:客户端发消息给RS3上面的region T1R3,要求读取行00007。
第八步:RS3上面的region T1R3将数据返回给客户端。
5.预写日志(wal)
每个RegionServer会将更新(Puts, Deletes)先记录到预写日志中(WAL),然后将其更新在Store的MemStore里面。这样就保证了HBase的写的可靠性。如果没有WAL,当RegionServer宕掉的时候,MemStore还没有flush,StoreFile还没有保存,数据就会丢失。HLog 是HBase的一个WAL实现,一个RegionServer有一个HLog实例。
WAL 保存在HDFS 的 /hbase/.logs/ 里面,每个region一个文件。
三. HBase数据模型
1.概念视图
以bigTable论文中的例子来说明,有一个名为webtable的表,包含两个列族:contents和anchor.在这个例子里面,anchor有两个列 (anchor:cssnsi.com,anchor:my.look.ca),contents仅有一列(contents:html)
Row Key | Time Stamp | ColumnFamily contents | ColumnFamily anchor |
"com.cnn.www" | t9 |
| anchor:cnnsi.com = "CNN" |
"com.cnn.www" | t8 |
| anchor:my.look.ca = "CNN.com" |
"com.cnn.www" | t6 | contents:html = "<html>..." |
|
"com.cnn.www" | t5 | contents:html = "<html>..." |
|
"com.cnn.www" | t3 | contents:html = "<html>..." |
|
RowKey:行键,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
Column:属于某一个columnfamily,每条记录可动态添加
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
Value(Cell):一个cell由familyName:columnName唯一定义
2.物理视图
尽管在概念视图里,表可以被看成是一个稀疏的行的集合。但在物理上,它的是区分列族 存储的。新的columns可以不经过声明直接加入一个列族.
Row Key | Time Stamp | Column Family anchor |
"com.cnn.www" | t9 | anchor:cnnsi.com = "CNN" |
"com.cnn.www" | t8 | anchor:my.look.ca = "CNN.com" |
Row Key | Time Stamp | ColumnFamily "contents:" |
"com.cnn.www" | t6 | contents:html = "<html>..." |
"com.cnn.www" | t5 | contents:html = "<html>..." |
"com.cnn.www" | t3 | contents:html = "<html>..." |
值得注意的是在上面的概念视图中空白cell在物理上是不存储的,因为根本没有必要存储。因此若一个请求为要获取t8时间的contents:html,他的结果就是空。相似的,若请求为获取t9时间的anchor:my.look.ca,结果也是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回。例如,如果请求为获取行键为"com.cnn.www",没有指明时间戳的话,活动的结果是t6下的contents:html,t9下的anchor:cnnsi.com和t8下anchor:my.look.ca。
对于hbase我一直有一个疑问,在hbase提供了修改和删除的接口,但是hdfs本身很难实现修改和删除(可以将文件块从hdfs中下载,进行修改再上传),那么hbase是如何实现快速的删除与修改呢?实际上在HBase中,修改和删除数据都是增加1个新版本的数据(时间戳为最新),旧版本的数据并没有发生变化,而实际上的修改和删除是在Hfile的合并阶段实现的。
四. HBase读写流程
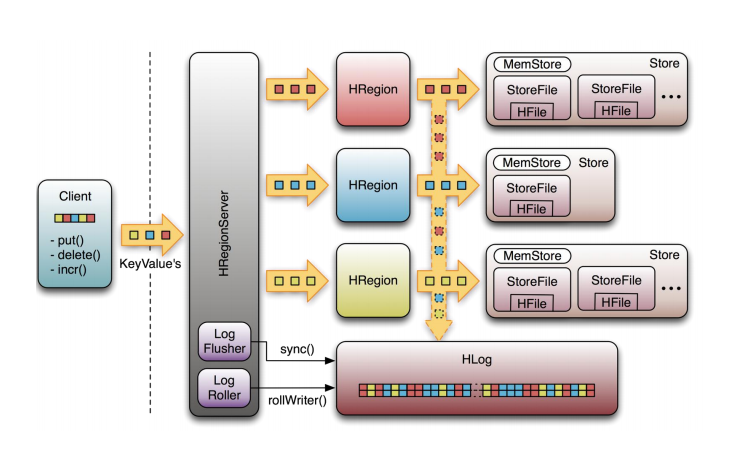
上图是HRegionServer数据存储关系图。上文提到,HBase使用MemStore和StoreFile存储对表的更新。数据在更新时首先写入HLog和MemStore。MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到Flush队列,由单独的线程Flush到磁盘上,成为一个StoreFile。与此同时,系统会在Zookeeper中记录一个CheckPoint,表示这个时刻之前的数据变更已经持久化了。当系统出现意外时,可能导致MemStore中的数据丢失,此时使用HLog来恢复CheckPoint之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定阈值后,就会进行一次合并操作,将对同一个key的修改合并到一起,形成一个大的StoreFile。当StoreFile的大小达到一定阈值后,又会对 StoreFile进行切分操作,等分为两个StoreFile。
1. 写操作流程
步骤1:Client通过Zookeeper的调度,向HRegionServer发出写数据请求,在HRegion中写数据。
步骤2:数据被写入HRegion的MemStore,直到MemStore达到预设阈值。
步骤3:MemStore中的数据被Flush成一个StoreFile。
步骤4:随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
步骤5:StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
步骤6:单个StoreFile大小超过一定阈值后,触发Split操作,把当前HRegion Split成2个新的HRegion。父HRegion会下线,新Split出的2个子HRegion会被HMaster分配到相应的HRegionServer 上,使得原先1个HRegion的压力得以分流到2个HRegion上。
2. 读操作流程
步骤1:client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
步骤2:从.META.表查找,获取存放目标数据的HRegion信息,从而找到对应的HRegionServer。
步骤3:通过HRegionServer获取需要查找的数据。
步骤4:HRegionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
五. HBase使用场景
半结构化或非结构化数据:对于数据结构字段不够确定或杂乱无章,很难按一个概念去进行抽取的数据适合用HBase。如随着业务发展需要存储更多的字段时,RDBMS需要停机维护更改表结构,而HBase支持动态增加。
记录非常稀疏:RDBMS的行有多少列是固定的,为空的列浪费了存储空间。而HBase为空的列不会被存储,这样既节省了空间又提高了读性能。
多版本数据:根据RowKey和列标识符定位到的Value可以有任意数量的版本值(时间戳不同),因此对于需要存储变动历史记录的数据,用HBase将非常方便。
超大数据量:当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要在集群中加入新的节点即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了数据的可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
六. HBase的MapReduce
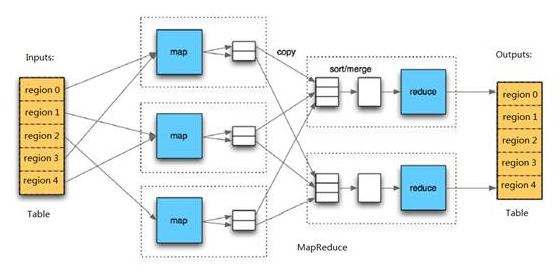
HBase中Table和Region的关系,有些类似HDFS中File和Block的关系。由于HBase提供了配套的与MapReduce进行交互的API如TableInputFormat和TableOutputFormat,可以将HBase的数据表直接作为Hadoop MapReduce的输入和输出,从而方便了MapReduce应用程序的开发,基本不需要关注HBase系统自身的处理细节。
七. Hbase优化
1. 预先分区
默认情况下,在创建 HBase 表的时候会自动创建一个 Region 分区,当导入数据的时候,所有的 HBase 客户端都向这一个 Region 写数据,直到这个 Region 足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的 Regions,这样当数据写入 HBase 时,会按照 Region 分区情况,在集群内做数据的负载均衡。
2. Rowkey优化
HBase 中 Rowkey 是按照字典序存储,因此,设计 Rowkey 时,要充分利用排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
此外,Rowkey 若是递增的生成,建议不要使用正序直接写入 Rowkey,而是采用 reverse 的方式反转Rowkey,使得 Rowkey 大致均衡分布,这样设计有个好处是能将 RegionServer 的负载均衡,否则容易产生所有新数据都在一个 RegionServer 上堆积的现象,这一点还可以结合 table 的预切分一起设计。
3. 减少列族数量
不要在一张表里定义太多的 ColumnFamily。目前 Hbase 并不能很好的处理超过 2~3 个 ColumnFamily 的表。因为某个 ColumnFamily 在 flush 的时候,它邻近的 ColumnFamily 也会因关联效应被触发 flush,最终导致系统产生更多的 I/O。
4. 缓存策略
创建表的时候,可以通过 HColumnDescriptor.setInMemory(true) 将表放到 RegionServer 的缓存中,保证在读取的时候被 cache 命中。
5. 设置存储生命期
创建表的时候,可以通过 HColumnDescriptor.setTimeToLive(int timeToLive) 设置表中数据的存储生命期,过期数据将自动被删除。
6. 硬盘配置
每台 RegionServer 管理 10~1000 个 Regions,每个 Region 在 1~2G,则每台 Server 最少要 10G,最大要1000*2G=2TB,考虑 3 备份,则要 6TB。方案一是用 3 块 2TB 硬盘,二是用 12 块 500G 硬盘,带宽足够时,后者能提供更大的吞吐率,更细粒度的冗余备份,更快速的单盘故障恢复。
7. 分配合适的内存给RegionServer服务
在不影响其他服务的情况下,越大越好。例如在 HBase 的 conf 目录下的 hbase-env.sh 的最后添加 export HBASE_REGIONSERVER_OPTS="-Xmx16000m$HBASE_REGIONSERVER_OPTS”
其中 16000m 为分配给 RegionServer 的内存大小。
8. 写数据的备份数
备份数与读性能成正比,与写性能成反比,且备份数影响高可用性。有两种配置方式,一种是将 hdfs-site.xml拷贝到 hbase 的 conf 目录下,然后在其中添加或修改配置项 dfs.replication 的值为要设置的备份数,这种修改对所有的 HBase 用户表都生效,另外一种方式,是改写 HBase 代码,让 HBase 支持针对列族设置备份数,在创建表时,设置列族备份数,默认为 3,此种备份数只对设置的列族生效。
9. WAL(预写日志)
可设置开关,表示 HBase 在写数据前用不用先写日志,默认是打开,关掉会提高性能,但是如果系统出现故障(负责插入的 RegionServer 挂掉),数据可能会丢失。配置 WAL 在调用 JavaAPI 写入时,设置 Put 实例的WAL,调用 Put.setWriteToWAL(boolean)。
10. 批量写
HBase 的 Put 支持单条插入,也支持批量插入,一般来说批量写更快,节省来回的网络开销。在客户端调用JavaAPI 时,先将批量的 Put 放入一个 Put 列表,然后调用 HTable 的 Put(Put 列表) 函数来批量写。
11. 客户端一次从服务器拉取的数量
通过配置一次拉去的较大的数据量可以减少客户端获取数据的时间,但是它会占用客户端内存。有三个地方可进行配置:
1)在 HBase 的 conf 配置文件中进行配置 hbase.client.scanner.caching;
2)通过调用 HTable.setScannerCaching(intscannerCaching) 进行配置;
3)通过调用 Scan.setCaching(intcaching) 进行配置。三者的优先级越来越高。
12. RegionServer的请求处理I/O线程数
较少的 IO 线程适用于处理单次请求内存消耗较高的 Big Put 场景 (大容量单次 Put 或设置了较大 cache 的Scan,均属于 Big Put) 或 ReigonServer 的内存比较紧张的场景。
较多的 IO 线程,适用于单次请求内存消耗低,TPS 要求 (每秒事务处理量 (TransactionPerSecond)) 非常高的场景。设置该值的时候,以监控内存为主要参考。
在 hbase-site.xml 配置文件中配置项为 hbase.regionserver.handler.count。
13. Region的大小设置
配置项为 hbase.hregion.max.filesize,所属配置文件为 hbase-site.xml.,默认大小 256M。
在当前 ReigonServer 上单个 Reigon 的最大存储空间,单个 Region 超过该值时,这个 Region 会被自动 split成更小的 Region。小 Region 对 split 和 compaction 友好,因为拆分 Region 或 compact 小 Region 里的StoreFile 速度很快,内存占用低。缺点是 split 和 compaction 会很频繁,特别是数量较多的小 Region 不停地split, compaction,会导致集群响应时间波动很大,Region 数量太多不仅给管理上带来麻烦,甚至会引发一些Hbase 的 bug。一般 512M 以下的都算小 Region。大 Region 则不太适合经常 split 和 compaction,因为做一次 compact 和 split 会产生较长时间的停顿,对应用的读写性能冲击非常大。
此外,大 Region 意味着较大的 StoreFile,compaction 时对内存也是一个挑战。如果你的应用场景中,某个时间点的访问量较低,那么在此时做 compact 和 split,既能顺利完成 split 和 compaction,又能保证绝大多数时间平稳的读写性能。compaction 是无法避免的,split 可以从自动调整为手动。只要通过将这个参数值调大到某个很难达到的值,比如 100G,就可以间接禁用自动 split(RegionServer 不会对未到达 100G 的 Region 做split)。再配合 RegionSplitter 这个工具,在需要 split 时,手动 split。手动 split 在灵活性和稳定性上比起自动split 要高很多,而且管理成本增加不多,比较推荐 online 实时系统使用。内存方面,小 Region 在设置memstore 的大小值上比较灵活,大 Region 则过大过小都不行,过大会导致 flush 时 app 的 IO wait 增高,过小则因 StoreFile 过多影响读性能。
14. 操作系统参数
Linux系统最大可打开文件数一般默认的参数值是1024,如果你不进行修改并发量上来的时候会出现“Too Many Open Files”的错误,导致整个HBase不可运行,你可以用ulimit -n 命令进行修改,或者修改/etc/security/limits.conf和/proc/sys/fs/file-max 的参数,具体如何修改可以去Google 关键字 “linux limits.conf ”
15. Jvm配置
修改 hbase-env.sh 文件中的配置参数,根据你的机器硬件和当前操作系统的JVM(32/64位)配置适当的参数
HBASE_HEAPSIZE 4000 HBase使用的 JVM 堆的大小
HBASE_OPTS "‐server ‐XX:+UseConcMarkSweepGC"JVM GC 选项
HBASE_MANAGES_ZKfalse 是否使用Zookeeper进行分布式管理
16. 持久化
重启操作系统后HBase中数据全无,你可以不做任何修改的情况下,创建一张表,写一条数据进行,然后将机器重启,重启后你再进入HBase的shell中使用 list 命令查看当前所存在的表,一个都没有了。是不是很杯具?没有关系你可以在hbase/conf/hbase-default.xml中设置hbase.rootdir的值,来设置文件的保存位置指定一个文件夹,例如:<value>file:///you/hbase-data/path</value>,你建立的HBase中的表和数据就直接写到了你的磁盘上,同样你也可以指定你的分布式文件系统HDFS的路径例如:hdfs://NAMENODE_SERVER:PORT/HBASE_ROOTDIR,这样就写到了你的分布式文件系统上了。
17. 缓冲区大小
hbase.client.write.buffer
这个参数可以设置写入数据缓冲区的大小,当客户端和服务器端传输数据,服务器为了提高系统运行性能开辟一个写的缓冲区来处理它,这个参数设置如果设置的大了,将会对系统的内存有一定的要求,直接影响系统的性能。
18. 扫描目录表
hbase.master.meta.thread.rescanfrequency
定义多长时间HMaster对系统表 root 和 meta 扫描一次,这个参数可以设置的长一些,降低系统的能耗。
19. split/compaction时间间隔
hbase.regionserver.thread.splitcompactcheckfrequency
这个参数是表示多久去RegionServer服务器运行一次split/compaction的时间间隔,当然split之前会先进行一个compact操作.这个compact操作可能是minorcompact也可能是major compact.compact后,会从所有的Store下的所有StoreFile文件最大的那个取midkey.这个midkey可能并不处于全部数据的mid中.一个row-key的下面的数据可能会跨不同的HRegion。
20. 缓存在JVM堆中分配的百分比
hfile.block.cache.size
指定HFile/StoreFile 缓存在JVM堆中分配的百分比,默认值是0.2,意思就是20%,而如果你设置成0,就表示对该选项屏蔽。
21. ZooKeeper客户端同时访问的并发连接数
hbase.zookeeper.property.maxClientCnxns
这项配置的选项就是从zookeeper中来的,表示ZooKeeper客户端同时访问的并发连接数,ZooKeeper对于HBase来说就是一个入口这个参数的值可以适当放大些。
22. memstores占用堆的大小参数配置
hbase.regionserver.global.memstore.upperLimit
在RegionServer中所有memstores占用堆的大小参数配置,默认值是0.4,表示40%,如果设置为0,就是对选项进行屏蔽。
23. Memstore中缓存写入大小
hbase.hregion.memstore.flush.size
Memstore中缓存的内容超过配置的范围后将会写到磁盘上,例如:删除操作是先写入MemStore里做个标记,指示那个value, column 或 family等下是要删除的,HBase会定期对存储文件做一个major compaction,在那时HBase会把MemStore刷入一个新的HFile存储文件中。如果在一定时间范围内没有做major compaction,而Memstore中超出的范围就写入磁盘上了。

















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









