









原文链接:
Focal Loss损失函数(超级详细的解读)-CSDN博客
建议参考的链接:
FocalLoss原理通俗解释及其二分类和多分类场景下的原理与实现_focal loss 二分类-CSDN博客
感悟:
区分正负样本和易分样本
什么是损失函数?
1、什么是损失呢?
在机器学习模型中,对于每一个样本的预测值与真实值的差称为损失。
2、什么是损失函数呢?
显而易见,是一个用来计算损失的函数。它是一个非负实值函数,通常使用L(Y, f(x))来表示。
3、那损失函数有什么用呢?
度量一个模型进行每一次预测的好坏(即预测值与真实值的差距程度)。差距程度越小,则损失越小,该学习模型越好。
4、损失函数如何使用呢?
损失函数主要是用在模型的训练阶段。在每一个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值与真实值的差异值,即损失值。得到损失值后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值靠拢,从而达到学习的目的。在训练完该模型后,此时模型通过反向传播后,已经使得每个参数都为最优。所以使用该模型进行预测得到的结果一定是接近真实结果的。
有哪些损失函数?
1、分类任务损失:
0-1 loss、熵与交叉熵loss、softmax loss及其变种、KL散度、Hinge loss、Exponential loss、Logistic loss、Focal Loss等待。
2、回归任务损失:
L1 loss、L2 loss、perceptual loss、生成对抗网络损失、GAN的基本损失、-log D trick、Wasserstein GAN、LS-GAN、Loss-sensitive-GAN等等。
Focal Loss损失函数介绍
Focal Loss的引入主要是为了解决one-stage目标检测中正负样本数量极不平衡问题。
那么什么是正负样本不平衡(Class Imbalance)呢?
在一张图像中能够匹配到目标的候选框(正样本)个数一般只有十几个或几十个,而没有匹配到的候选框(负样本)则有10000~100000个。这么多的负样本不仅对训练网络起不到什么作用,反而会淹没掉少量但有助于训练的样本。
上面说了是为了解决一阶段目标检测模型,那为什么二阶段不用解决呢?
因为在二阶段中分了两步,第一步时同样也会生成许多的负样本以及很少的正样本,但到第二步时,它会在第一步的基础上选取特定数量的正负样本去检测,所以正负样本并不会特别不平衡
为了解决该问题,许多网络也进行过许多处理方法,比如:hard negative mining(难例挖掘),即并不会使用所有的负样本去训练网络,而是去选取损失比较大的来训练。
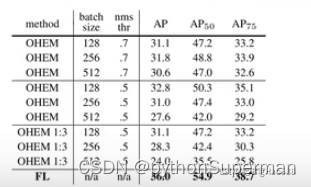
上表是一张采用hard negative mining和Focal Loss方法的比较,和显然使用Focal Loss的效果非常好。
Focal Loss理论知识
Focal loss是基于二分类交叉熵CE的。它是一个动态缩放的交叉熵损失,通过一个动态缩放因子,可以动态降低训练过程中易区分样本的权重,从而将重心快速聚焦在那些难区分的样本(有可能是正样本,也有可能是负样本,但都是对训练网络有帮助的样本)。
接下来我将从以下顺序详细说明:Cross Entropy Loss (CE) -> Balanced Cross Entropy (BCE) -> Focal Loss (FL)。
1、Cross Entropy Loss:基于二分类的交叉熵损失,它的形式如下:
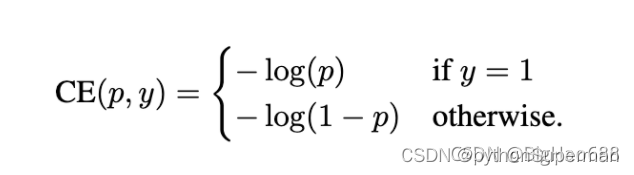
上式中,y的取值为1和-1,分别代表前景和背景。p的取值范围为0~1,是模型预测属于前景的概率。接下来定义一个关于P的函数:
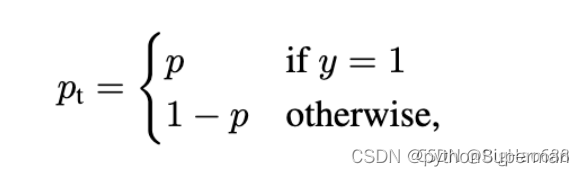
结合上式,可得到简化公式:
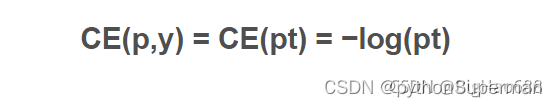
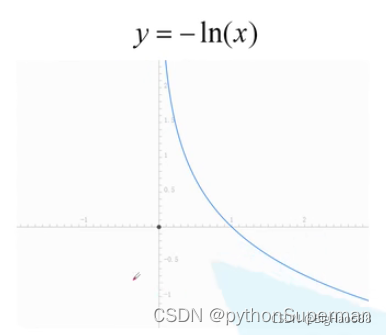
注意:公式中的log函数就是ln函数:
2、Balanced Cross Entropy:常见的解决类不平衡方法。引入了一个权重因子α ∈ [ 0 , 1 ] ,当为正样本时,权重因子就是α,当为负样本时,权重因子为1-α。所以,损失函数也可以改写为:

这里,𝛼𝑡是根据类别频率逆转的权重。
这里给出一张图:
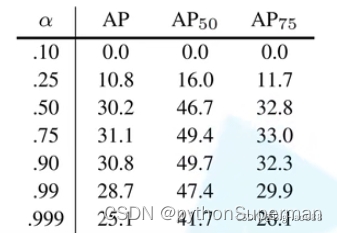
可以看出当权重因子为0.75时,效果最好。
3、Focal Loss:虽然BCE解决了正负样本不平衡问题,但并没有区分简单还是难分样本。当易区分负样本超级多时,整个训练过程将会围绕着易区分负样本进行,进而淹没正样本,造成大损失。所以这里引入了一个调制因子 ,用来聚焦难分样本,公式如下:

γ为一个参数,范围在 [0,5], 当 γ为0时,就变为了最开始的CE损失函数。
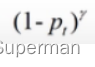 可以减低易分样本的损失贡献,从而增加难分样本的损失比例,解释如下:当Pt趋向于1,即说明该样本是易区分样本,此时调制因子
可以减低易分样本的损失贡献,从而增加难分样本的损失比例,解释如下:当Pt趋向于1,即说明该样本是易区分样本,此时调制因子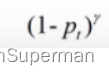 是趋向于0,说明对损失的贡献较小,即减低了易区分样本的损失比例。当pt很小,也就是假如某个样本被分到正样本,但是该样本为前景的概率特别小,即被错分到正样本了,此时 调制因子
是趋向于0,说明对损失的贡献较小,即减低了易区分样本的损失比例。当pt很小,也就是假如某个样本被分到正样本,但是该样本为前景的概率特别小,即被错分到正样本了,此时 调制因子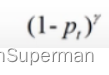 是趋向于1,对loss也没有太大的影响。
是趋向于1,对loss也没有太大的影响。
对于 γ的不同取值,得到的loss效果如图所示:
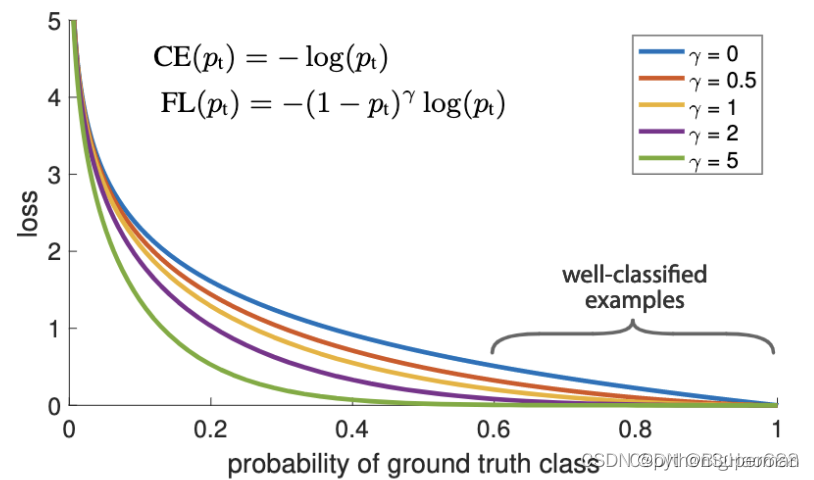
可以看出,当pt越大,即易区分的样本分配的非常好,其所对于的loss就越小。
通过以上针对正负样本以及难易样本平衡,可以得到应该最终的Focal loss形式:
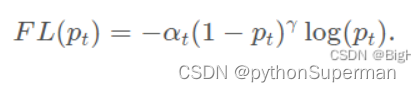
即通过αt 可以抑制正负样本的数量失衡,通过 γ 可以控制简单/难区分样本数量失衡。
Focal Loss理论知识总结:
①调制因子是用来减低易分样本的损失贡献 ,无论是前景类还是背景类,pt越大,就说明该样本越容易被区分,调制因子也就越小。②αt用于调节正负样本损失之间的比例,前景类别使用 αt 时,对应的背景类别使用 1 − αt 。
③γ 和 αt 都有相应的取值范围,他们的取值相互间也是有影响的,在实际使用过程中应组合使用。
focal loss vs balanced cross entropy
focal loss相比balanced cross entropy而言,二者都是试图解决样本不平衡带来的模型训练问题,后者从样本分布角度对损失函数添加权重因子,前者从样本分类难易程度出发,使loss聚焦于难分样本。
focal loss为什么有效
focal loss从样本难易分类角度出发,解决样本非平衡带来的模型训练问题。
相信很多人会在这里有一个疑问,样本难易分类角度怎么能够解决样本非平衡的问题,直觉上来讲样本非平衡造成的问题就是样本数少的类别分类难度较高。因此从样本难易分类角度出发,使得loss聚焦于难分样本,解决了样本少的类别分类准确率不高的问题,当然难分样本不限于样本少的类别,也就是focal loss不仅仅解决了样本非平衡的问题,同样有助于模型的整体性能提高。
要想使模型训练过程中聚焦难分类样本,仅仅使得Loss倾向于难分类样本还不够,因为训练过程中模型参数更新取决于Loss的梯度。
多分类场景下的FocalLoss
3.1 FocalLoss调节多分类的类别权重

在大部分博客甚至开源项目上,在多分类问题上 α \alphaα 也还是一个数。但在多分类问题上,这样理论上没办法解决调整不平衡数据的问题,相当于所有的数据都乘以了一个小数,没效果。 上面的理解是我在向ChatGPT提问时它给出的答案,我觉得这个是比较合理的。
3.2 FocalLoss调节多分类难易样本权重

3.3 整合上述过程,完成多分类的FocalLoss

从上面例子可以看出,因为one-hot的存在,真正对loss起作用的其实只有样本所在的那一行。
因此,我们可以将FocalLoss公式改进为如下:

3.4 Pytorch 实现多分类FocalLoss
class FocalLoss(nn.Module):
"""
参考 https://github.com/lonePatient/TorchBlocks
"""
def __init__(self, gamma=2.0, alpha=1, epsilon=1.e-9, device=None):
super(FocalLoss, self).__init__()
self.gamma = gamma
if isinstance(alpha, list):
self.alpha = torch.Tensor(alpha, device=device)
else:
self.alpha = alpha
self.epsilon = epsilon
def forward(self, input, target):
"""
Args:
input: model's output, shape of [batch_size, num_cls]
target: ground truth labels, shape of [batch_size]
Returns:
shape of [batch_size]
"""
num_labels = input.size(-1)
idx = target.view(-1, 1).long()
one_hot_key = torch.zeros(idx.size(0), num_labels, dtype=torch.float32, device=idx.device)
one_hot_key = one_hot_key.scatter_(1, idx, 1)
one_hot_key[:, 0] = 0 # ignore 0 index.
logits = torch.softmax(input, dim=-1)
loss = -self.alpha * one_hot_key * torch.pow((1 - logits), self.gamma) * (logits + self.epsilon).log()
loss = loss.sum(1)
return loss.mean()
if __name__ == '__main__':
loss = FocalLoss(alpha=[0.1, 0.2, 0.3, 0.15, 0.25])
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
print(output)
output.backward()
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









